[OSS RELEASE] This is my story of how I've been using RLMs at work. Since its launch (Jan26), I started using it for daily tasks (coding, processing huge multi-million-token logs, and even automating browser use). I'm releasing this so you can too! It's one pip-install away
My RLM agent can effortlessly process ~80k lines of service logs from CloudWatch
in a single go. that's worth like 8 million tokens.
The cool part is, after 53 steps, it had spent only 32k "active" tokens* (not through the full 8MM yet atp, more like half).
That's nothing for Claude Fable 5 (rip), and weeell within effective context window, so its very "context-efficient".
It can go VERY far and I dont even have to handhold it or anything, i'm not worrying about context running out or compactions either.
I'm saying I kicked this thing off, almost without any context, and it was able to infer the service architecture based on logs alone, and spot issues my team didn't.
In this particular case it was able to narrow down on a specific slice and find a couple issues that flew under the team's radar (AgentCore's throttles, Slack's user_not_found)
Very handy.
I'll release this as OSS soon (my first release on llm tooling!)
[OSS RELEASE] This is my story of how I've been using RLMs at work. Since its launch (Jan26), I started using it for daily tasks (coding, processing huge multi-million-token logs, and even automating browser use). I'm releasing this so you can too! It's one pip-install away
My RLM agent can effortlessly process ~80k lines of service logs from CloudWatch
in a single go. that's worth like 8 million tokens.
The cool part is, after 53 steps, it had spent only 32k "active" tokens* (not through the full 8MM yet atp, more like half).
That's nothing for Claude Fable 5 (rip), and weeell within effective context window, so its very "context-efficient".
It can go VERY far and I dont even have to handhold it or anything, i'm not worrying about context running out or compactions either.
I'm saying I kicked this thing off, almost without any context, and it was able to infer the service architecture based on logs alone, and spot issues my team didn't.
In this particular case it was able to narrow down on a specific slice and find a couple issues that flew under the team's radar (AgentCore's throttles, Slack's user_not_found)
Very handy.
I'll release this as OSS soon (my first release on llm tooling!)
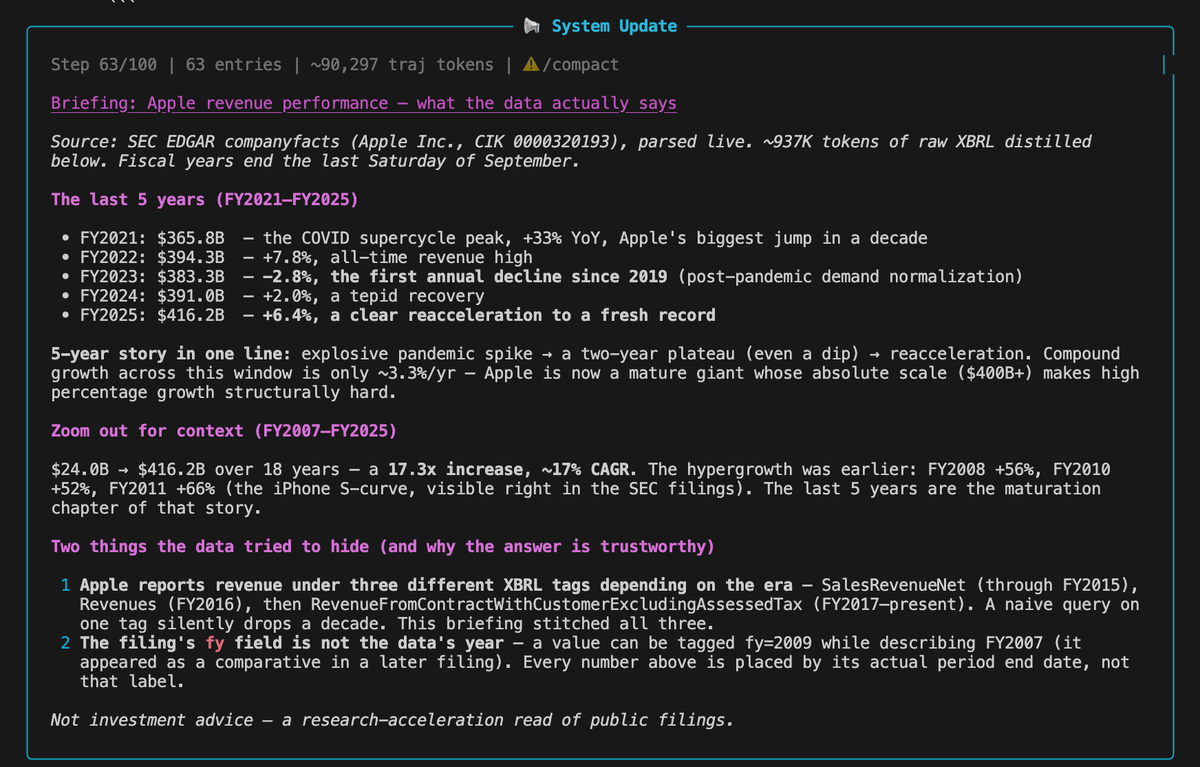
This sample prompt fetches years' worth of Apple financial reportings and analyzes revenue performance:
"Hey — curl `https://t.co/XT70JmvMmH` straight into a variable and teach me something about Apple's revenue performance over the years. It's a huge JSON of everything they've filed with the SEC; figure out the structure yourself and tell me the story the numbers tell."
the argument seems to be:
- some people got falsely diagnosed, so they treated something that didnt need treatment
- some people got correctly diagnosed, but for something that wouldn’t have caused any issues in their lifetime, so they may do unnecessary surgery for example.
- people may feel anxiety due to a diagnosis that is either false, or, true but not relevant in their lifetime.
- there is no scientific evidence that doing more of these innovative scans in fact improve survival rates.
- we should stick to things that are known to ultimately improve survival rates based on scientific evidence (like randomized trials), like mammography.
i’d say the first three are noise and downstream to the last two → basically it means the next step is to get scientific evidence this thing works to a positive outcome more often than not.
If we have something that has 95% false positive rate, it is basically useless, and we don’t need the extra data just for the sake of it. In this case, the first three arguments make sense → it’ll just make people anxious and go to surgery for no good reason. and that can be a big problem on itself which we need to acknowledge.
So it’s just a matter of letting it evolve until we can have said evidence, then everyone agrees.
IMO there is one counter-argument here → for rare diseases that have low prevalence (like <3% in the example below), yeah it is likely to have huge false positive rate.
But what about diseases that have HIGH prevalence (like >50%) instead? These are more likely to have a lower false positive rate.
Bottom line: until we dont have scientific evidence, keep using a flaky test only for high-prevalence diseases (in these cases, having more data can in fact help). Only after high-quality studies have provided evidence, can we recommend it more broadly, like on low-prevalence diseases.
i’m just saying things
indeed a fun thought experiment. This seems to depend on how deep the work is.
If we're talking about finding difficult security issues, that's super deep, and Fable might run leaps on GPT-5 even on a worse harness.
However, if we're talking about organizing things or consolidating information, that's not that deep as far as "intelligence" goes, and GPT-5 with a purpose-made harness could be the one running leaps.
https://t.co/kUNetW2M9n
[1/N] I’ve been wondering:
maybe search agents are bad at search partly because we make them do all the paperwork in their head.
So I tried a simple idea:
externalize the search state, then train the model to use that harness.
The result is Harness-1: a 20B search agent that can match or even beat much larger frontier AI on hard long-horizon search tasks.
>I think in a perfect world, you wouldn't need task-specific harnesses at all
yeah... but experience shows we're still at a point where task-specific harness will beat general harness on that specific task.
to be honest, it makes sense. Think about the difference between an experienced manager and a novice.
The experienced one will have a bunch of customized tricks and tools and excel spreadsheets and whatnot to help them keep track of deadlines, make more effective plans, spread workload across a team more productively, etc. all while having effective 1:1s with each person.
The novice manager might just wing it, and do it "free-style" on the fly kind of thing.
One has a bunch of task-specific tools that helps them not forget anything, be more productive, more thorough, etc. Like spreadsheets per employee, gantt charts, email tooling to not miss anything, etc.
The other has just a notepad and their own brain and thats it. maybe the calendar.
The "harness" here are these tools to help you stay in touch with all these details that are important for your task, without relying as much on raw brain power. It's "mechanism" rather than "good intentions". It helps. Even humans. Will help LLMs too, for the foreseeable future
> But whenever you have some new task, you'd have to create a new harness
Yeah, that's the tradeoff indeed. It helps to not have super narrow tasks.
Get the balance right --> don't make a "fix-unit-tests" harness, make a "code review" harness instead (example: https://t.co/geOwm6520D)
ARC-AGI is designed to take a stab at measuring general intelligence and the ability to generalize, very abstractly.
But you’ll notice it doesn’t teach us much about harnesses or practical applications. we could say its like an IQ test, when I’m really looking for some kind of job certificate → “can this AI solution do well on remembering my instructions, having a good world understanding, and do THIS* task appropriately, even if the task is complex (as opposed to simple) or hard (as opposed to easy**)?“
*p.s.: it’d be okay to have one focused toy problem per “task”, instead of one super problem. Think a problem representative of one of each: coding, teaching, doing marketing, organizing a team/company, etc. The best harness can and WILL look different for each.
**p.s.2: some things can be complex but easy, or simple but hard.
I remember seeing a bunch of ARC solutions having to do with per-task program synthesis, evolutionary algorithms, and other stuff that, at least right now, don’t seem to translate that cleanly to a daily task. by the way many solutions also are based on trying a bunch of times (different variations), as opposed to having 1 shot in real life.
Your toy problems seem to better capture the fact that you need to consistently make good decisions, and clean up your own mess when needed, instead of restarting from a blank slate and just trying again.
disclaimer: i haven't read much about it lately.
that’s exactly my point.
the “perfect” toy problem:
(a) exercises the same “capacities” (memory, planning…) as a real task with real value
(b) is easy to verify.
right now these problems are (b) but not (a)
I would like to see someone focus on designing the problem itself (not the harness). If the problem is good, we can just try a bunch of different harness variations and it’ll be easy to pick the winners
https://t.co/AiCRDFRQWu
@mhmazur Can we create a different experiment, as simple as this one, that exercises the same “fundamentals” that makes an agent useful in real life?
Like some sort of “2D Minecraft” where agents need to be competent at doing tasks and remembering what they did in order to be useful.
I certainly did it for a number of tasks. I've used this thing to read logs, write code, even upload receipts to an expense report using browser automation (will share soon)
The main downside is that I've been improving this harness myself, obviously it is behind in terms of how much work was spent to make it optimal.
Kind of? https://t.co/8pVHlV46Qz
The concept of RLM itself can support videos as its not tied to text (can work with any data that the underlying LLM can support)
But a specific implementation of it might need tweaks.
My implementation of the Recursive Language Model (RLM) paper by @a1zhang , Kraska, and @lateinteraction .
Key insight: "Treat long context as an external environment, not something to stuff into a context window."
Applied to video understanding — instead of encoding 38K frames into a prompt, the agent:
→ Treats video as an environment
→ Writes code to explore segments
→ Uses recursive LLM sub-calls for analysis
Tested: 20+ min video, 7 steps, $0.002
Paper: https://t.co/sMkqVscWZD
Code: https://t.co/J3GxdlKeav
Do notice that I specifically said "context-efficiency", not "token-efficiency". Thanks for calling that out.
I meant that the RLM can efficiently decide what needs to come into context.
But it wouldn't be able to process >8MM tokens if it didn't pull some of that into context at some point.
The thing is, a bunch of things can be processed by a sub-llm instead. Token spend can still grow, but active context window doesn't (as much).
Do notice that I specifically said "context-efficiency", not "token-efficiency". Thanks for calling that out.
I meant that the RLM can efficiently decide what needs to come into context.
But it wouldn't be able to process >8MM tokens if it didn't pull some of that into context at some point.
The thing is, a bunch of things can be processed by a sub-llm instead. Token spend can still grow, but active context window doesn't (as much).
My RLM agent can effortlessly process ~80k lines of service logs from CloudWatch
in a single go. that's worth like 8 million tokens.
The cool part is, after 53 steps, it had spent only 32k "active" tokens* (not through the full 8MM yet atp, more like half).
That's nothing for Claude Fable 5 (rip), and weeell within effective context window, so its very "context-efficient".
It can go VERY far and I dont even have to handhold it or anything, i'm not worrying about context running out or compactions either.
I'm saying I kicked this thing off, almost without any context, and it was able to infer the service architecture based on logs alone, and spot issues my team didn't.
In this particular case it was able to narrow down on a specific slice and find a couple issues that flew under the team's radar (AgentCore's throttles, Slack's user_not_found)
Very handy.
I'll release this as OSS soon (my first release on llm tooling!)


















![patpcj's tweet photo. [1/N] I’ve been wondering:
maybe search agents are bad at search partly because we make them do all the paperwork in their head.
So I tried a simple idea:
externalize the search state, then train the model to use that harness.
The result is Harness-1: a 20B search agent that can match or even beat much larger frontier AI on hard long-horizon search tasks.](https://pbs.twimg.com/media/HKJN3fIaUAA9lmx.png)




















