Production hurts.
If it doesn't, it means you didn't try hard enough.
When you're in production, things fail, users complain, oncall alerts wake you up in the middle of the night, incidents happen. Those endless video conferences nobody leaves until they are 100% sure not a single client is still affected.
You spend 1 month chasing that bug impossible to reproduce.
You fail and you need to explain it to your customers that lose money because of you.
That small issue you don't have time to fix is blocking someone.
Every single day there is a moment you remember there are thousands of requests coming into your system every second.
Every new customer makes the development team slower. Maybe it's just 1 hour a month, that's 0.01% of a developer's time in a 40 developer team. Seems low but it adds up.
Maintenance is not fun. You need people that make it fun, developers that write reports you actually want to read about the most boring fix.
Alerting is tricky and you need to fiddle for weeks until you nail it.
You need developers that care. I think they call it "being accountable".
Today we are releasing a new Tinybird, thanks to every single one spending your time on keeping this running.
Finalmente agradecer a la org de la @PyConES el ttrabajo que se han pegado este fin de semana y los meses anteriores. Aún más importante, destacar la comunidad de desarrolladores de Vigo, que perteneciendo o no al mundo de Python, han estado volcados igualmente en el evento.
La solución es un #RAG (Retrieved Augmented Generation) programado con #python, @milvusio, y @streamlit, que permite comprobar contra una BD de noticias contrastadas por multiples entidades independientes, si una noticia o consulta enviada por un usuario, es verdadera o falsa.
Aprovecho también esta publicación para dejaros un enlace al vídeo que he realizado de mi solución presentada al Hackaton patrocinado por @Newtral en el evento, la cual me ha permitido llevarme uno de los flamantes premios 🏆 .
Ya de vuelta en casa tras una @PyConES en #Vigo que ha sido impresionante y no únicamente por las charlas, sinó también por la posibilidad de poder re-encontrarme con gran cantidad de gente de múltiples comunidades.
I am so fucking tired of half-naked women in model demos. You're telling me you couldn't illustrate model's capabilities with a prompt about a busy farm stand? A macro photo of a spider? Car mechanic? Camel? Literally couldn't use anything else other than "sexy/redhead/bikini"?
I recreated an entire GPT architecture in a spreadsheet.
It is a nanoGPT designed by @karpathy with about 85000 parameters, small enough to be packed into a spreadsheet file.
It is great for learning about how transformer works as it shows all the data and parameters going through a transformer pipeline, and all the calculations are actually working inside those cells.
Here is a link to the project where you can download the file and play with it yourself. No coding needed, it is just a spreadsheet. 😉
Spreadsheet is all you need:
https://t.co/dreZlBDq4d
Also thanks to @BrendanBycroft with his LLM visualisation project which inspired this.
@javisantana El tema es que el wrapped le añade un un pico de carga gordo a todo lo anterior, que como bien comentas, hay que saber gestionar con mucho cuidado. Aunque sea "solo" lidiar con el escalado, la calidad de servicio y la disponibilidad de un pipeline de datos existente, cuidadín...
@javisantana Sólo comentar que esto no es el esfuerzo anual del wrapped. Posiblemente es el día a día de los data engineering y muchos de los resultados que utilizan para el wrapped, ya los tengan que calcular para KPIs, profiling de usuarios, info para artistas, el placement de anuncios, etc
Reading @MetaAI's Segment-Anything, and I believe today is one of the "GPT-3 moments" in computer vision. It has learned the *general* concept of what an "object" is, even for unknown objects, unfamiliar scenes (e.g. underwater & cell microscopy), and ambiguous cases.
I still can't believe both the model and data (11M images, 1B masks) are OPEN-sourced. Wow.😮
What's the secret sauce? Just follow the foundation model mindset:
1. A very simple but scalable architecture that takes multimodal prompts: text, key points, bounding boxes.
2. Intuitive human annotation pipeline that goes hand-in-hand with the model design.
3. A data flywheel that allows the model to bootstrap itself to tons of unlabeled images.
IMHO, Segment-Anything has done everything right.
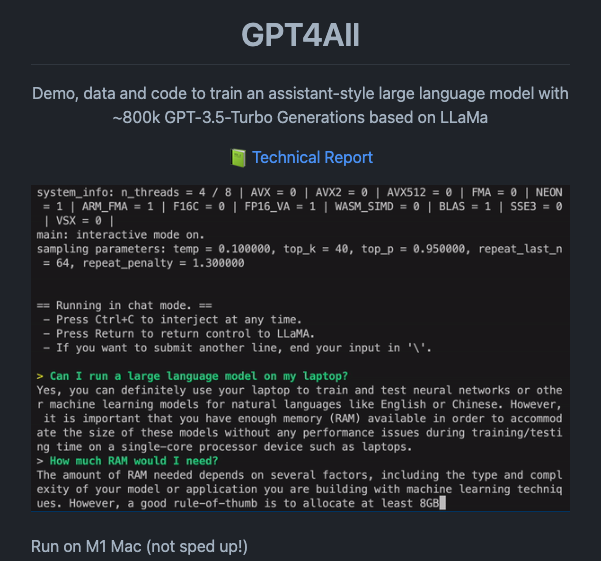
New language model just dropped!
GPT4All - a 7B parameter model (based on LLaMA) trained on a massive collection of clean assistant data including code, stories, and dialogue.
Also releases 800K data samples, data curation procedures, training code, and model weights to promote open research.
A quantized 4-bit version of the model is released that can run on CPU.
repo: https://t.co/KBnWG2tfqc
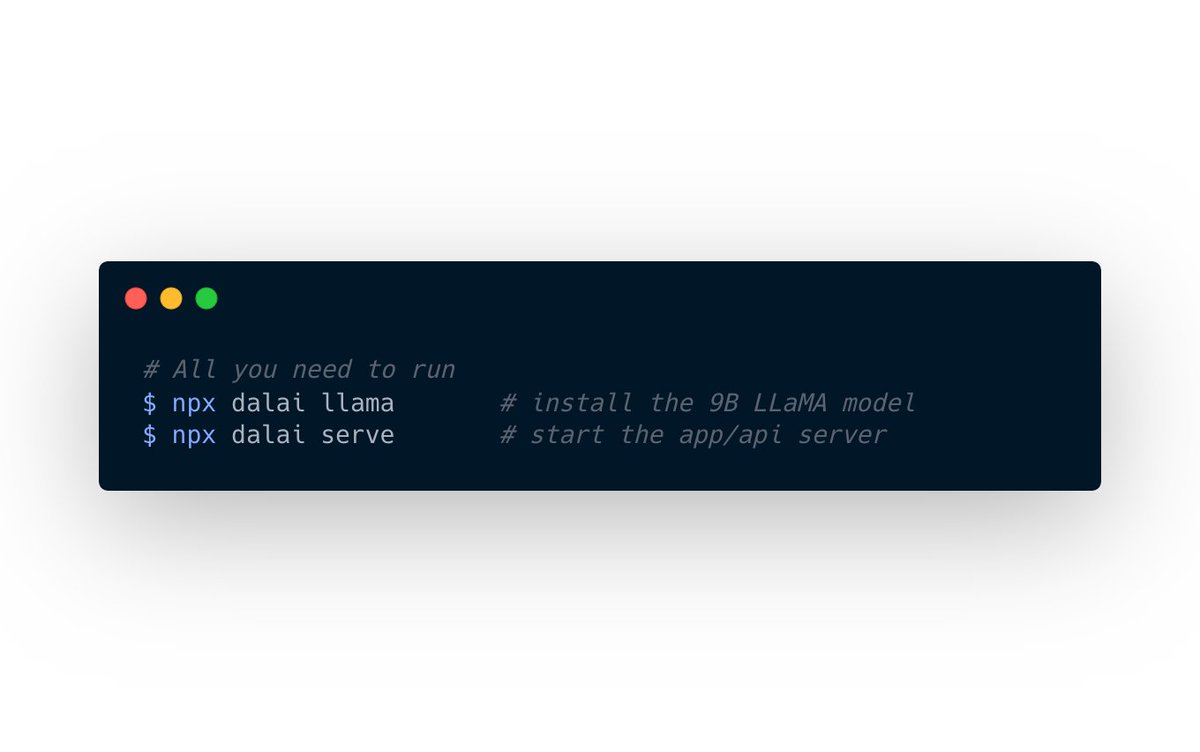
Introducing Dalai, a super simple way to run LLaMA AI on your computer.
No need to bother building cpp files, cloning github, and downloading files and stuff. Everything is automated.
All you need is: "npx dalai llama"
Website: https://t.co/lm6Kx7Rcn0