Me, the🧨diffusers library, am now on Twitter
This is an informal place for us to chat about the latest diffusion models advancements, news regarding the library, give support and celebrate our amazing community 🤩
https://t.co/lkfKr0nKUZ
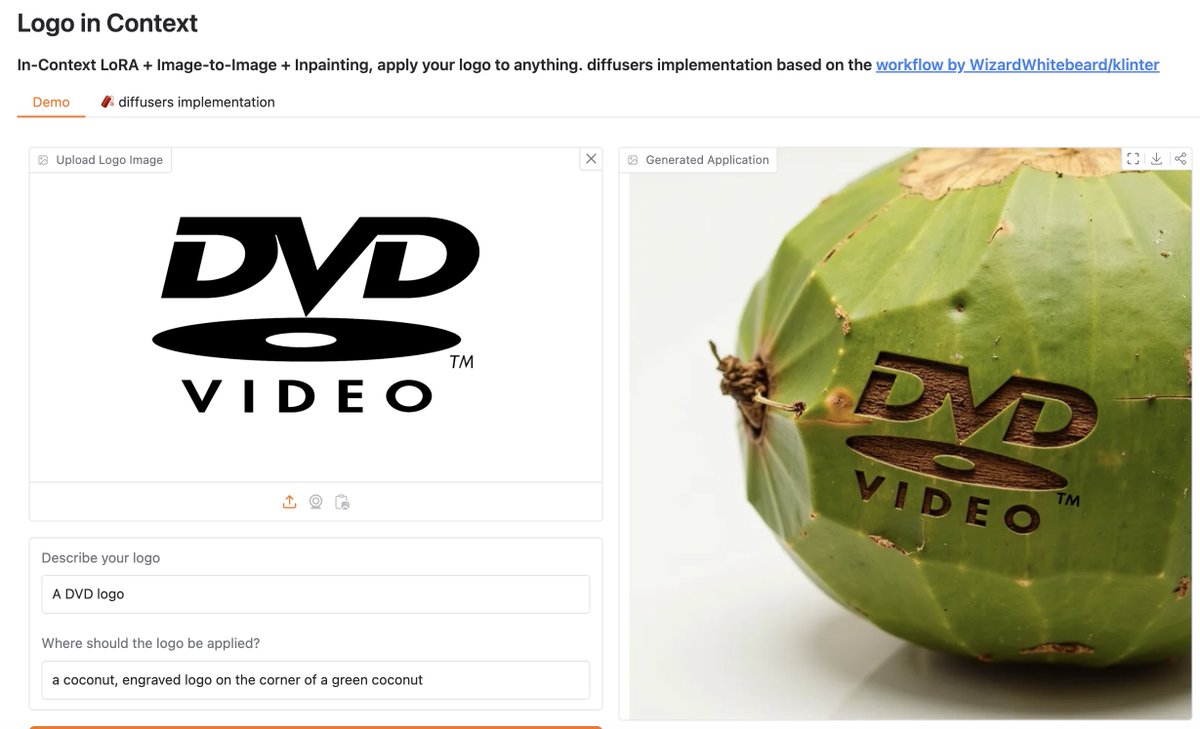
The Logo in Context Spaces demo + 🧨 diffusers implementation is here! 🖼️🏷️
In-Context LoRA + Image-to-Image + Inpainting → allow you to apply your logos to anything
https://t.co/cpWZ91tVBG
The Logo in Context Spaces demo + 🧨 diffusers implementation is here! 🖼️🏷️
In-Context LoRA + Image-to-Image + Inpainting → allow you to apply your logos to anything
https://t.co/cpWZ91tVBG
we now support any FLUX LoRA you send our way:
trained with Kohya, X-Labs, Simple-Tuner, AI-Toolkit, Replicate, FAL, Hugging Face, CivitAI, ComfyUI, diffusers (duh!)? No problem, we support it!
We now support loading and inferencing with two non-diffusers Flux LoRAs
1> X-Labs
2> Kohya (@kohya_tech)
Thanks to @multimodalart for jamming on this with me!
https://t.co/ve9waWESxp
We now support loading and inferencing with two non-diffusers Flux LoRAs
1> X-Labs
2> Kohya (@kohya_tech)
Thanks to @multimodalart for jamming on this with me!
https://t.co/ve9waWESxp
CogVideoX just released the weights for its 5B model! 🎥 ✨
It's the best open weights text-to-video model - competitive with Runway / Luma / Pika. With 🧨@diffuserslib, it fits on < 10GB VRAM 🤏
(ah, and they changed the smaller 2B model license to Apache 2.0 🔥)
Now, PAG is officially supported by Diffusers in the stable version! Try it out🥰
Use cases: https://t.co/xF3Mk8yAHP
Supported pipelines: https://t.co/XN1hkUCPRX
We would like to extend our gratitude to the amazing team at @huggingface for their incredible work. Special thanks to @RisingSayak for taking charge of PixArt-Sigma, @aryanvs_ for taking HunyuanDiT and refactoring the code brilliantly, @OzzyGT for handling Kolors and conducting numerous experiments, @multimodalart for being an early adopter and advocate, and @YiYiMarz for designing the overall framework for PAG pipelines.
we just dropped an insane new release 🐣
- support to new pipelines: audio 🔊, video 🎬 and image 🖼️ models (FLUX, Stable Audio, CogVideoX, Kolors, AuraFlow and moar!)
- native PAG support for image quality boost 💨
- AnimatedDiff 🤝 SparseCtrl
https://t.co/Y7JD62U4Kw
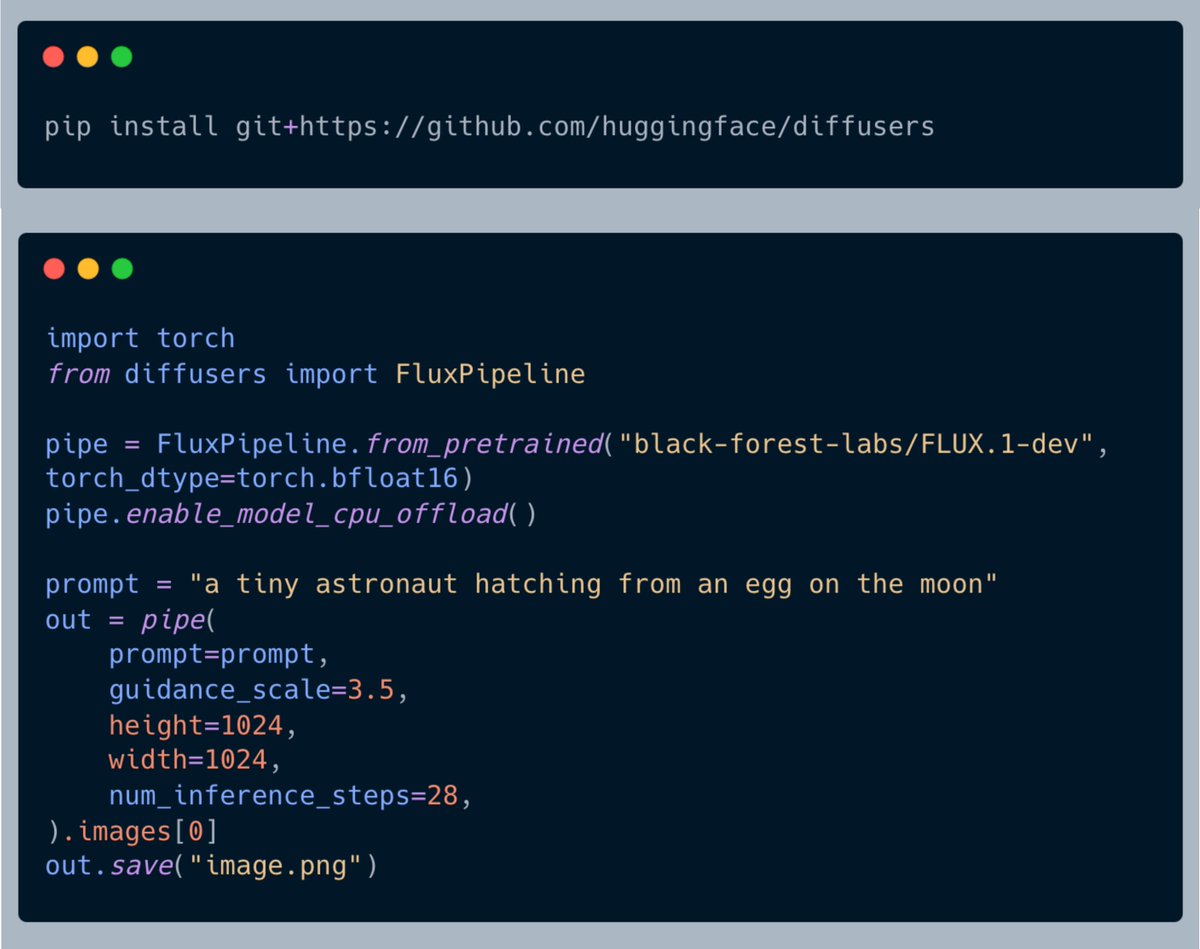
You should have already gone bonkers by now with @bfl_ml's FLUX release. What a model, eh!
I am getting back to Twitter after some sprinting with my mates @_DhruvNair_, @YiYiMarz, and @multimodalart!
Diffusers integration is, of course, there ❤️
We have also put together a little gist guiding you on how to run Flux with limited resources.
https://t.co/VZ8JuqLxb4
The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔
It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨
In the paper they claim to be SOTA open source! I'm working on a @huggingface demo as you read this so we can all vibe check
Model: https://t.co/bGY2JLxLBo
GitHub: https://t.co/n7kL104vcU
Paper: https://t.co/mR8uy8zcFf
Demo for the first open SD3-like architecture model, HunyuanDiT @huggingface Spaces demo is out! 🎨
First impressions:
- Image quality seems very good!
- Chunky and the research code isn't super optimized for inference speed (👋 @diffuserslib 👀)
▶️ https://t.co/HjdQPNw0jF