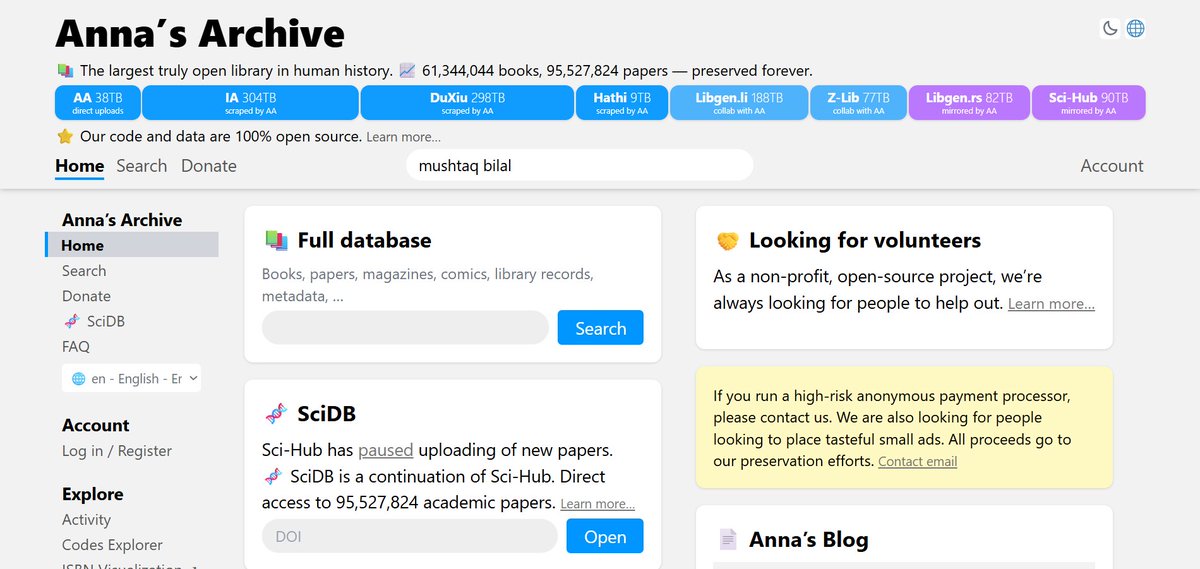
🚨Don't use Anna's Archive — it's pirate website with 61M+ books and 95M+ research papers freely available.
We should all try to make billion-dollar academic publishers richer.
jax-js now supports `einsum()`, general notation for multidimensional tensor operations — this was one heck of an API to fully implement 😅
thanks Joy and Greg for hacking with me on an einsum optimizer after NYSRG on Sunday
https://t.co/CRPRViY5A7
Meta's segmentation models are insanely underhyped.
The latest release - SAM Audio - allows you to search for ANY sound across a video, isolate it, and apply effects.
Watch me take a travel vlogger's noisy clip and remove the background audio so he's way easier to hear 👇
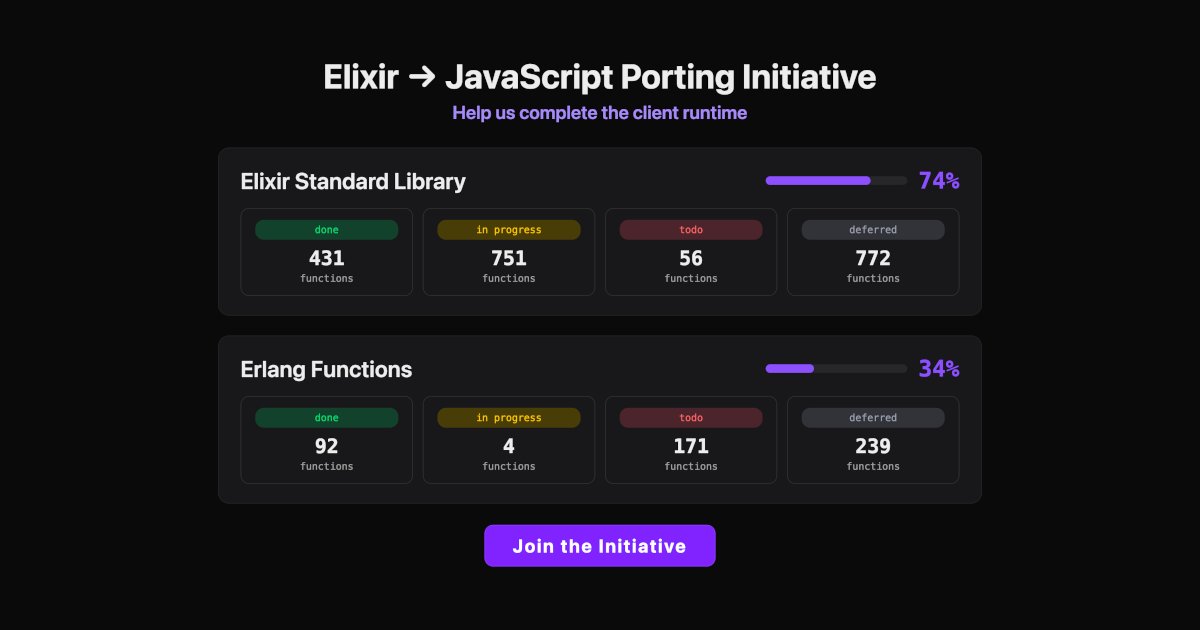
Hey Elixir friends! :)
We need help completing Elixir's browser runtime by porting some Erlang functions to JavaScript.
No Erlang knowledge required. Each function unlocks multiple Elixir stdlib functions!
More here: https://t.co/vSeh61aE75
#Hologram#Elixir#ElixirLang#BEAM #WebDev
splat troubleshooting guide:
If you ever export a splat from NerfStudio that's transparent, let it train for another 1000 steps
what's happening is the alphas get reset every 3k steps, so here when i exported at 12k steps, it was right when the alphas reset, hence the transparency.
you can adjust the reset frequency with reset_every: int = 3000
this might've been obvious to some, but I was confused by it last night and found no discussions/explanation about it online. so posting it here to help others
Last week, we released the Elixir Language Tour to help new learners get started faster.
Thanks to Popcorn, you can run examples and do coding exercises straight in your browser! No installs - use it even on your smartphone. Behind the scenes, Popcorn compiles and runs your code locally via WebAssembly 🍿
Check it out – link below 🧵
Elixir v1.19.0-rc.2 is out! It is our last stop before v1.19, so please give it a try: https://t.co/UZHTWF3NNR
The results are great: the @remote folks confirmed their codebase compiles 55% on v1.19 and type checking is still ~1ms/module on average, even with all new features!
We worked really hard on this one! @duboc_guillaume and I had to go beyond the current state of the art to optimize some key operations used during set-theoretic typing checking! We will publish some articles on this later on. Enjoy!
You've heard me advocating for Erlang/Elixir for some years now. I've put together a short presentation about some of the practical reasons why I chose to pursue this tech.
Practical Arguments for Erlang / Elixir
I started my career in robotics, participating in Robocup (twice, once with the Swedish team, 2002, and then creating the first Italian Humanoid Team, in 2003).
As many teams have asked me for a free license of #Groot2, I decided to make it available for free to anyone for 45 days, until the end of Robocup 2025.
License:
EF1D1F-2885CE-40B88A-3145E6-B8E1BD-99A406
We've been shipping https://t.co/nigREmLzaK as an open-source project for over a year. Now you can deploy it on @JamsocketHQ as a natively-supported service, without touching a Dockerfile!
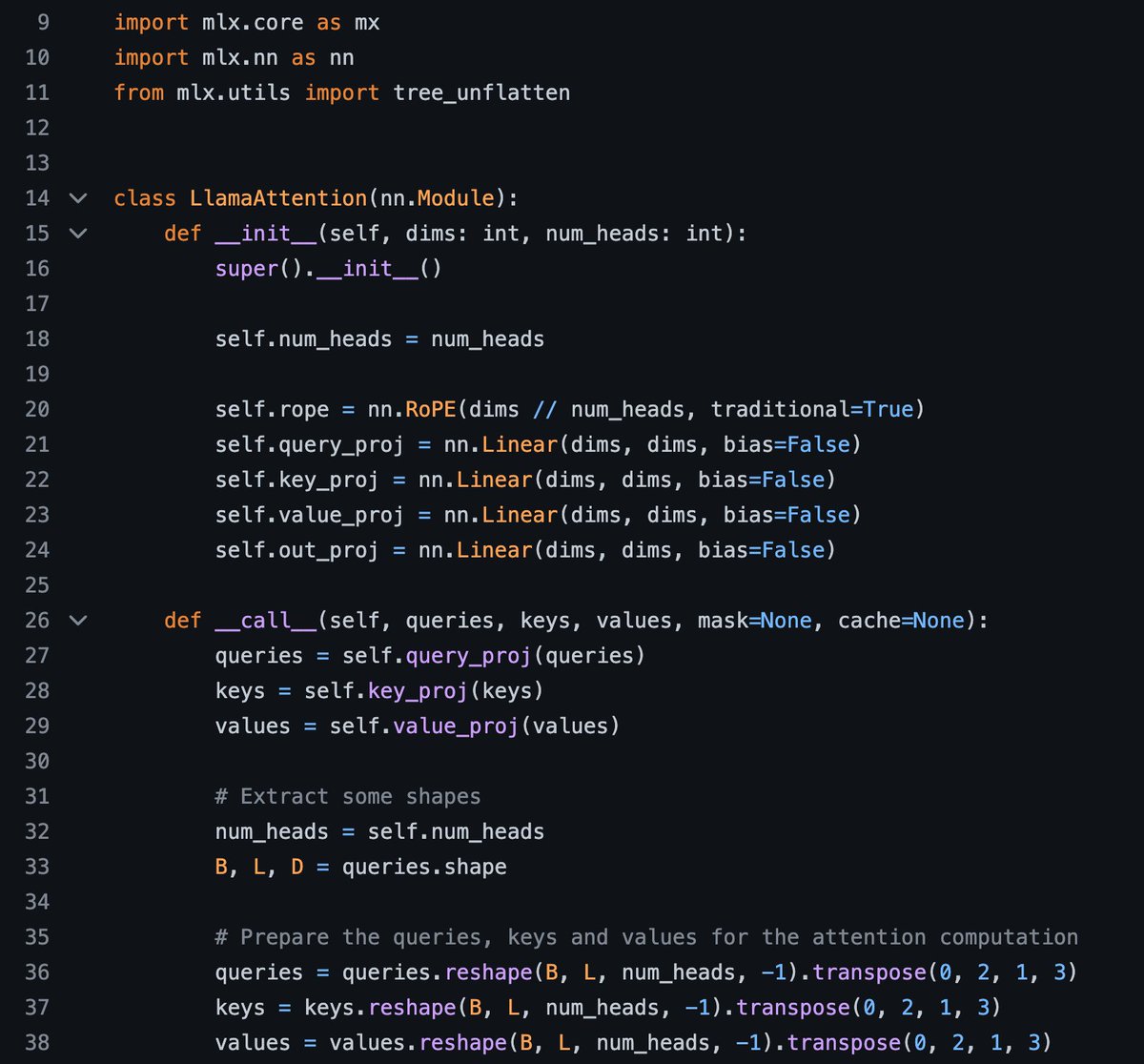
This may be Apple's biggest move on open-source AI so far: MLX, a PyTorch-style NN framework optimized for Apple Silicon, e.g. laptops with M-series chips.
The release did an excellent job on designing an API familiar to the deep learning audience, and showing minimalistic examples on OSS models that most people care about: Llama, LoRA, Stable Diffusion, and Whisper.
I expect no less from my former colleague @awnihannun, spearheading this effort at Apple. Thanks for the early Christmas gift! 🎄🎁
MLX source: https://t.co/GlNJDOu9NE
Well-documented, self-contained examples: https://t.co/UazqGZ0nhZ
This is amazing → https://t.co/PgCBx2jqPE
An AI emoji generator, built by @pondorasti using @nextjs, @replicate, and @vercel ▲
100% free & open-source too 🤩
You'll soon see lots of "Llama just dethroned ChatGPT" or "OpenAI is so done" posts on Twitter. Before your timeline gets flooded, I'll share my notes:
▸ Llama-2 likely costs $20M+ to train. Meta has done an incredible service to the community by releasing the model with a commercially-friendly license. AI researchers from big companies were wary of Llama-1 due to licensing issues, but now I think many of them will jump on the ship and contribute their firepower.
▸ Meta's team did a human study on 4K prompts to evaluate Llama-2's helpfulness. They use "win rate" as a metric to compare models, in similar spirit as the Vicuna benchmark. 70B model roughly ties with GPT-3.5-0301, and performs noticeably stronger than Falcon, MPT, and Vicuna.
I trust these real human ratings more than academic benchmarks, because they typically capture the "in-the-wild vibe" better.
▸ Llama-2 is NOT yet at GPT-3.5 level, mainly because of its weak coding abilities. On "HumanEval" (standard coding benchmark), it isn't nearly as good as StarCoder or many other models specifically designed for coding. That being said, I have little doubt that Llama-2 will improve significantly thanks to its open weights.
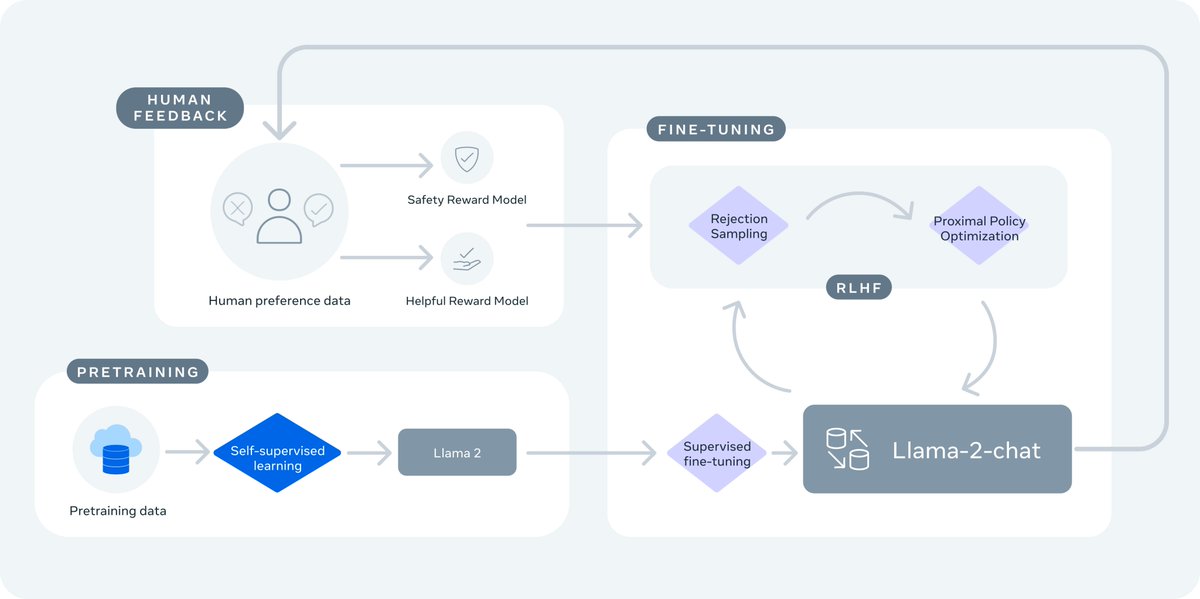
▸ Meta's team goes above and beyond on AI safety issues. In fact, almost half of the paper is talking about safety guardrails, red-teaming, and evaluations. A round of applause for such responsible efforts!
In prior works, there's a thorny tradeoff between helpfulness and safety. Meta mitigates this by training 2 separate reward models. They aren't open-source yet, but would be extremely valuable to the community.
▸ I think Llama-2 will dramatically boost multimodal AI and robotics research. These fields need more than just blackbox access to an API.
So far, we have to convert the complex sensory signals (video, audio, 3D perception) to text description and then feed to an LLM, which is awkward and leads to huge information loss. It'd be much more effective to graft sensory modules directly on a strong LLM backbone.
▸ The whitepaper itself is a masterpiece. Unlike GPT-4's paper that shared very little info, Llama-2 spelled out the entire recipe, including model details, training stages, hardware, data pipeline, and annotation process. For example, there's a systematic analysis on the effect of RLHF with nice visualizations.
Quote sec 5.1: "We posit that the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHF."
Congrats to the team again 🥂! Today is another delightful day in OSS AI.
I love installing CUDA drivers
the best part of doing ML research is installing CUDA drivers
spending my entire day installing CUDA drivers leaves me feeling fulfilled
✨✨ The M2 MAX is alive!!!! ✨✨
First frames rendered on the M2 Max with the Python test driver framework!! It took a bit more effort than expected but we got there!!! 🧊
Next Wednesday, let's get this all merged into the Linux Rust driver so we can run apps and games! 🚀🚀