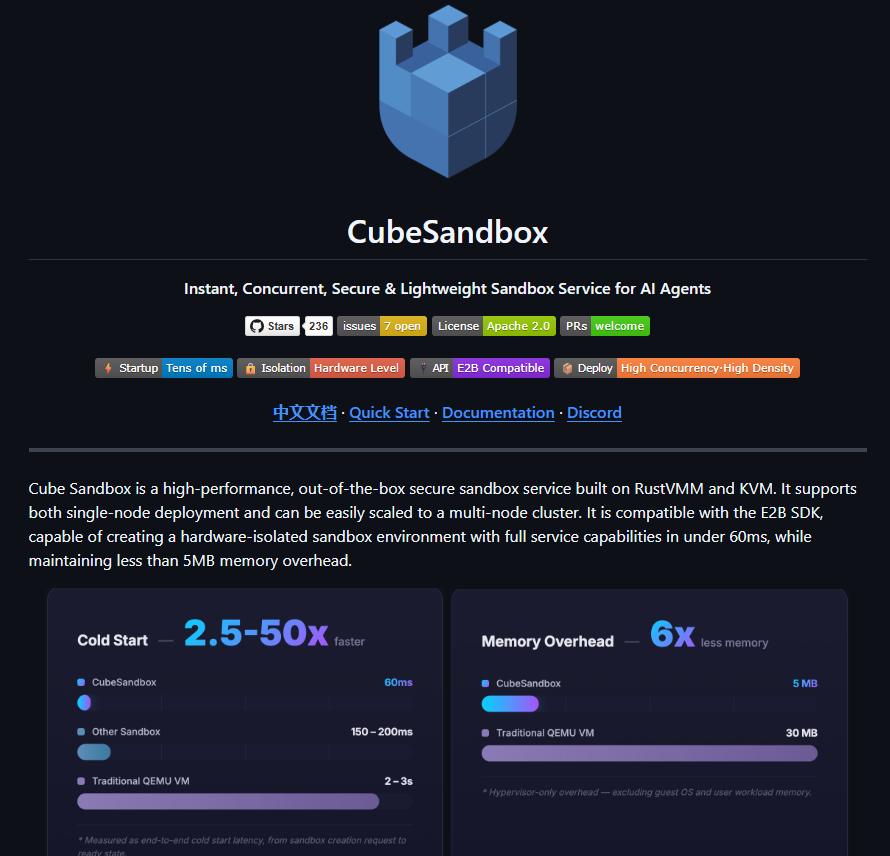
TENCENT ACABA DE DROPEAR LA BOMBA para todos los que hacen AI Agents:
Un sandbox que:
- Arranca en menos de 60 ms (hasta 50x más rápido)
- Usa solo 5 MB de RAM por instancia
- Puedes correr +2.000 sandboxes en un solo servidor
- Seguridad de verdad (microVMs con KVM + RustVMM)
- y 100% compatible con E2B SDK.
Self-hosted, open-source y GRATIS.
REPOOO👇
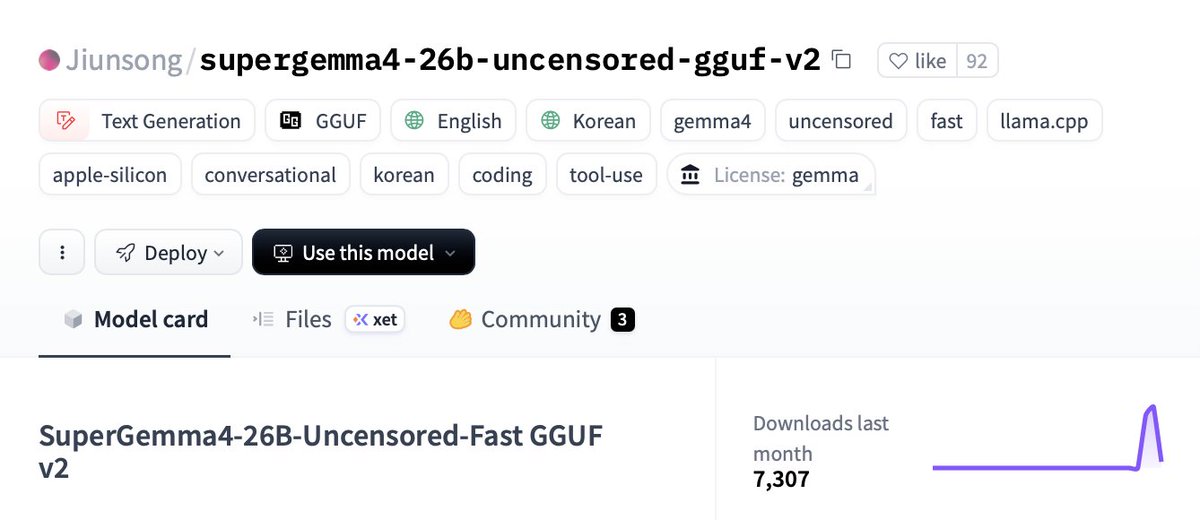
🚨 SUPER GEMMA 4 26B UNCENSORED IS INSANE
LLM WIZARD COOKING AGAIN @jun_song
Dropped SuperGemma4-26B-Uncensored GGUF v2 and it’s trending on @huggingface🤗
This thing SMOKES the regular Gemma-4 26B:
🤯0/100 refusals (actually uncensored)
🚀Fixed all the tool-call + tokenizer jank
⚡️90% faster prompt processing
🏆Sharper, smarter, way more capable responses
- Perfect local beast for llama.cpp
✅ Runs ~18-22 GB VRAM (16.8 GB Q4_K_M file)
- Run on 16 GB GPUs!
The 31B version in the works, should be out SOON 🤯
Pull this version on hugging face below 👇🏻
THIS GITHUB REPO TURNS CLAUDE CODE INTO A FULL GAME DEVELOPMENT STUDIO WITH 49 AI AGENTS
49 specialized agents, 72 skills, 12 hooks, 11 rules, and 39 document templates
to make one coordinated AI team.
instead of one general-purpose assistant, you get an entire studio hierarchy:
> directors who guard the game's vision
> department leads who own their domains
> specialists who do the hands-on work
you get a creative director, technical director, producer at the top.
game designer, lead programmer, art director, audio director, QA lead in the middle.
then 30+ specialists covering gameplay programming, AI, networking, level design, sound design, writing, UX, devops, security, and more.
it comes with engine-specific agent sets for Godot 4, Unity, and Unreal Engine 5. pick your engine and get specialists who actually know it.
72 slash commands cover every phase:
> /brainstorm to explore ideas from scratch
> /design-system to map out game mechanics
> /create-epics and /create-stories for sprint planning
> /dev-story to implement features
> /code-review, /qa-plan, /smoke-check for quality
> /team-combat, /team-narrative, /team-ui to coordinate multiple agents on a single feature
> /release-checklist and /launch-checklist when you're ready to ship
hooks run automatically on every commit checking for hardcoded values, TODO formatting, asset naming conventions, and JSON validity.
path-scoped rules enforce different coding standards depending on what part of the codebase you're editing.
and it's not auto-pilot. every agent follows a strict collaboration protocol: ask questions first, present 2-4 options with pros and cons, let you decide, show work before finalizing, and nothing gets written without your sign-off.
free AND open source
You can now run 70B LLMs on a 4GB GPU.
AirLLM just made massive models usable on low-memory hardware.
𝗪𝗵𝗮𝘁 𝗷𝘂𝘀𝘁 𝗵𝗮𝗽𝗽𝗲𝗻𝗲𝗱
AirLLM released memory-optimized inference for large language models.
It runs 70B models on 4GB VRAM.
It can even run 405B Llama 3.1 on 8GB VRAM.
𝗛𝗼𝘄 𝗶𝘁 𝘄𝗼𝗿𝗸𝘀
AirLLM loads models one layer at a time.
Instead of loading everything:
→ Load a layer
→ Run computation
→ Free memory
→ Load the next layer
This keeps GPU memory usage extremely low.
𝗞𝗲𝘆 𝗱𝗲𝘁𝗮𝗶𝗹𝘀
• No quantization required by default
• Optional 4-bit or 8-bit weight compression
• Same API as Hugging Face Transformers
• Supports CPU and GPU inference
• Works on Linux and macOS Apple Silicon
𝗪𝗵𝗮𝘁 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗱𝗼
• Run Llama, Qwen, Mistral, Mixtral locally
• Test large models without cloud GPUs
• Prototype agents on cheap hardware
Web scraping will never be the same!
You get literally 10x faster scraping and semantic crawling with Firecrawl v2.
Firecrawl lets you drop in any URL → crawl → get clean, LLM-ready data.
⚡️JUST IN: 🇹🇭 Thailand launches program for tourists to convert crypto directly into Thai baht.
No USD needed — bring your crypto and spend with ease in one of the world’s top travel destinations!🌴
ByteDance just opensourced a desktop automation AI Agent.
This agent can use any desktop app, open files, and browse websites using vision models running locally.
100% Free, Opensource, and Local.