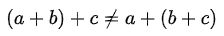@corsix@opinali This.
Also all the different EDA tools only support different random subsections of Verilog. Part of the fun is finding the sub-sub-set that actually works in them all without losing chip intent
@Leik0w0 It’s usually better for hardware systolic arrays. Hw doesn’t execute matmuls in the same physical directions as paper and pencil matrices - the row and col weights come from the same physical place, so it has to be row+row or col+col. Someone is doing the xpose somewhere
Floating point math is not associative! And many of the highest performance kernels split the workload among SMs and accumulate partial results in a nondeterministic order. Many AI labs just accept this, or pay a huge performance penalty for determinism. DeepSeek decided to do neither. (1/4) 🧵
i believe it was @divBy_zero that wisely said that, contrary to common sense, it is always easier to fix performance problems in silicon than change an entrenched sw stack
Callout to the many leads and engineers who worked this over the years, esp @rawat_ritvik@aaronsrogers and Pete.
This will be a massive (and needed) upgrade to all cars and bots.
Hello, Moon. It’s great to be back.
Here’s a taste of what the Artemis II astronauts photographed during their flight around the Moon. Check out more photos from the mission: https://t.co/rzM1P0QbOl
@LottoLabs@ptremblay Pedantically you are correct, yes. Way less loss than current quantization, and that detail would derail non technical folks ever further, so I didn’t split the hairs
@CliffLattner Yes, exactly. If doing inference, the compute will hide under the dram loads, even at high batch. For training, it is extra compute to pay.
Two days of weird takes, so I must:
“8x perf” is 32-bit baseline vs 4-bit compressed
“KV cache” is merely a use case and hard to capitalize full perf. And yes, many already compress here.
But it’s lossless. The others aren’t.
We should have been using this all along.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
My flight lands, I exit the plane, look for the Baggage Claim sign, and then there it was:
A 448Gpbs PAM4 Keysight waveform analyzer advertisement, on an LED backlight mega screen.
Thank you SJC