Freebuff is a great free vibe-coding tool.
If you're new to vibe-coding and hesitant to spend money, give Freebuff a try.
It gets the job done.
https://t.co/w25gIqMWQG
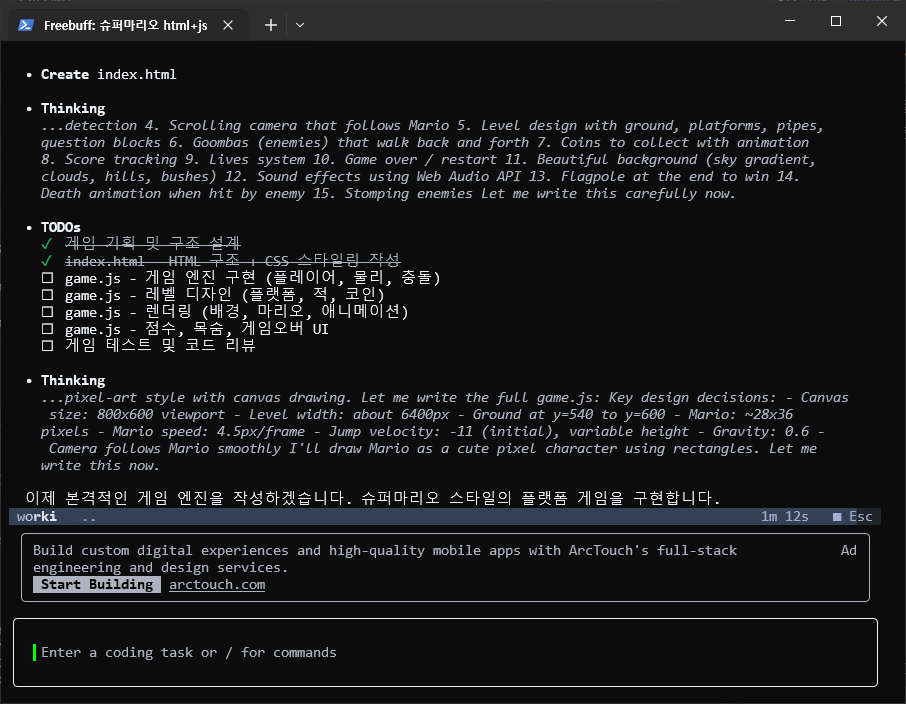
I tried out FreeBuff, a newly released AI agent coding tool.
How to install: npm install -g freebuff
Getting started: Once installed, run freebuff and you'll be prompted to log in via GitHub.
Currently, it supports DeepSeek V4 Flash and Mimo 2.5.
It doesn't seem to be completely unlimited. Based on the message "0.2 of 5 sessions used, resets in 46m," it looks like they provide a certain amount of usage that resets after a specific period. Also, a text ad pops up at the bottom while the coding is in progress.
That said, there don't seem to be any restrictions on using the available models themselves.
Bottom line: Just install it and start using it!
https://t.co/2xfPpgMVYf
@robinebers Korean devs and vibecoders are in absolute FOMO MAX mode right now. We literally feel like AI is going to delete all our jobs by tomorrow morning! 😭😂
Looking for the llama.cpp version that supports Gemma4 MTP?
Support for Gemma4 MTP has recently been merged into llama.cpp.
This means you can now run Gemma4 MTP by building it straight from the official llama.cpp repo.
https://t.co/WR277k679g
When running LLMs with VRAM+CPU offloading, MTP draft types matter:
Embedded: Draft heads load into VRAM by default -> high risk of OOM
External: Separate file, so you can adjust GPU layers independently. Much easier to offload to CPU
If VRAM is tight, always go with external drafts. If using embedded, keep a massive VRAM buffer!
Gemma4 26B QAT Q4 + MTP + llama.cpp @ RTX 3060 12GB
You shouldn't expect much from MTP in MoE models.
Still, since it's out, I gave it a spin.
Based on the 3060 12GB, the VRAM was insufficient, so I did CPU offloading.
Compared to previous tests, it seems to come out about 15-20% more.
The files I received are as follows.
The driving command is listed below.
If VRAM is insufficient, increase the -ncmoe value, and if it is sufficient, decrease or remove it.
Let's just do it for now.
gemma-4-26B_q4_0-it.gguf
https://t.co/lo9cINqpHk
gemma-4-26b-A4B-it-assistant-Q4_0-q4emb.gguf
https://t.co/LVl8XL5VA4
~/llama.cpp/build/bin/llama-server \
-m ~/models/gemma4-26b/gemma-4-26B_q4_0-it.gguf \
-md ~/models/gemma4-26b/gemma-4-26b-A4B-it-assistant-Q4_0-q4emb.gguf \
--host 0.0.0.0 \
--port 8080 \
-c 131072 \
-ncmoe 13 \
-fa on \
-ctk q8_0 \
-ctv q8_0 \
-b 1024 \
-ub 256 \
-np 1 \
--no-mmap \
--reasoning off \
-t 8 \
--spec-draft-ngl 99 \
--spec-draft-type-k q8_0 \
--spec-draft-type-v q8_0 \
--spec-type draft-mtp \
--spec-draft-n-max 4 \
--metrics
I tested the Gemma4 31B QAT + MTP setup on an RTX 3060 12GB with CPU offloading.
It turns out, running a dense model that goes over the VRAM limit is definitely a bad idea.
I got around 5-6 TPS, which is pretty abysmal.
😂😂
@sudoingX When Gemma4 12B first came out, it had some issues with looping or freezing mid-sentence, but running it on the recently updated llama.cpp improved it a lot. You should give it a try too.
https://t.co/B80qFDnPCI