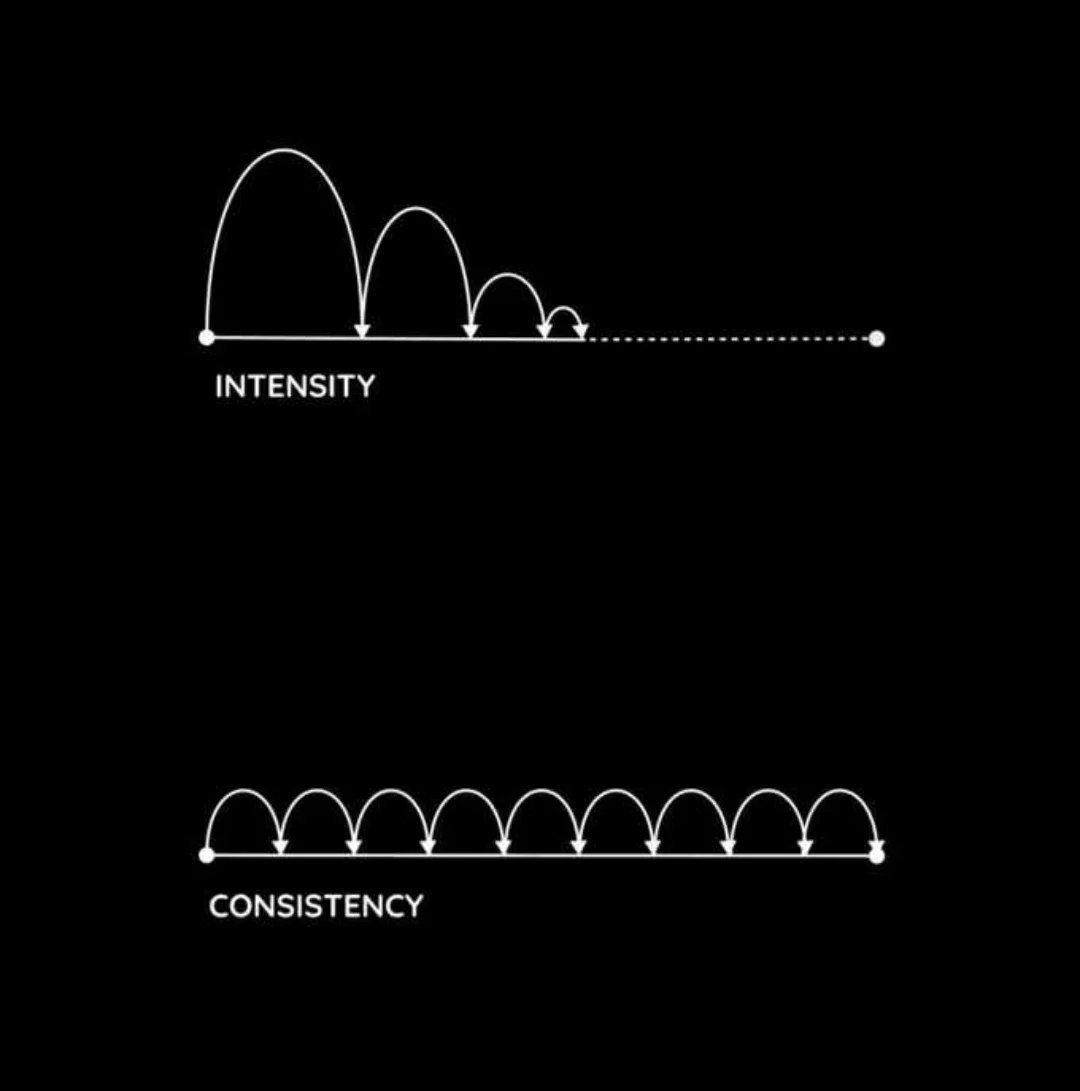
Consistency beats motivation. That’s the principle I try to learn and apply by myself.
Consistency beats talent. That’s something I saw in real life many times.
Consistency helps to build habits. Habits help to shape your nature & temper. If you want to progress - be consistent
my favorite engineering skills for AI:
- Compound Engineering: https://t.co/BM7tA2RAHf
- Ryan Singer's shaping skills: https://t.co/yaWg0nI7Vm
- Matt Pocock's skills: https://t.co/0WtRqce6x5
I switched from Superpowers to Compound Engineering as they perfected the plugin over time, and I'm pretty sure I still only use like 10% of it
I just got back from SF and I FEEL INSPIRED.
I spent 5 days with frontier AI model teams, AI startup founders, and 3 billionaires.
My takeaways:
1. I had lunch with 3 billionaires. All of them are buying SaaS companies and rebuilding them agent-first. They were deeply inspired by Bending Spoons and Ryan Cohen's eBay deal. Buy the company, cut the headcount, rebuild the tech, add agents, add features, make more valuable experience, raise prices.
2. The frontier model companies are hungry for usage data from the field. They can see API calls and token counts. They can't see the actual workflows. If you're deep in a niche using these models in ways the model companies haven't seen, that understanding is incredibly valuable. Usage intelligence is the new alpha.
3. Consumer AI is massively underbuilt. Every billboard in SF is either B2B inference infrastructure or vertical agent companies. The entire city is optimized for enterprise. Meanwhile you have companies like Cal AI doing $50M ARR in 18 months as a consumer app. I met with a cool few teams doing consumer AI (@paulscherer / @ekuyda)
4. MCP came up in literally every conversation. The companies exposing their product as MCP endpoints are getting pulled into deals they never pitched for. The ones that aren't are becoming invisible to agents. This is the new SEO. If agents can't find you, you don't exist. Building products for agents is the new zeitgeist in general.
5. Not uncommon for hot seed rounds to be $25-50 million valuations. I saw a Series A at $450 million
6. If I had a dollar every time someone mentioned "forward-deployed engineer" this trip I could have funded a seed round. It's the hottest role in SF right now. The person who sits between the agent and the customer, making sure everything actually works.
7. The mood around open source shifted. A year ago it felt like open source was chasing the frontier models. Now founders are telling me Gemma and DeepSeek are good enough for 80% of what they need at a fraction of the cost. The "which model do you use" conversation is being replaced by "which model for which task." Model loyalty kinda feels dead.
8. Voice agents came up more than I expected. Multiple founders told me voice is the interface for the next billion users. The billion people who will never type a prompt will absolutely talk to one.
9. The Obsidian community in SF is weirdly intense. Multiple founders showed me their vaults unprompted. Like showing someone your home gym. It's a flex now. The quality of your knowledge base (second brain?) is becoming a status symbol among builders.
10. Maybe it was just the people I met but the age of the founders is shifting. I met more founders over 40 this trip than any trip before and more founders under age 21 than ever before. Founders getting older and younger at the same time.
11. I spoke to a lot of fast-growing startups, VCs and frontier models who are hiring content creators right now.
12. The restaurant scene in SF is actually better than it's been in years. Founders are going out more. Alcohol is out, not surprisingly.
13. SF doesn't feel like the only place anymore. We all have access to the same frontier models. We all read the same X feed. A founder in NYC or Lagos is calling the same APIs as a founder in SoMa. So in the past it felt like SF was always lightyears ahead, doesn't feel that way anymore. It's okay not to live in SF and have BIG DREAMS.
14. The coworking spaces in SF are half empty but the coffee shops are packed. People want to be around people. I had a few startup ideas here....
15. Walking around the Mission I noticed something: the street-level businesses, the taquerias, the barbershops, the laundromats, none of them use any AI at all.
16. I heard the phrase "agent debt" for the first time. Like technical debt but for agents. When you hack together an agent workflow fast and never clean it up, the system prompts conflict, the memory gets polluted, the tools overlap. 6 months later the agent is doing weird things and nobody knows why lol.
17. Met a few people who carry two phones now. One for personal. One that's basically an agent terminal running Telegram or iMessage connections to their agent fleet.
It's always amazing to get that dose of inspiration in SF. I FEEL INSPIRED.
But I'm so happy to be back home, locked in and building.
We're 12-18 months into a shift that will take 15 years to play out. The urgency in every conversation was real.
What an incredible time to be building.
must read
Marcus went from product manager to shipping product like a madman @every with coding agents
he wrote the definitive guide for how to do it: https://t.co/IQpwPQK1Fi
My biggest takeaways from Claude Code's Head of Product @_catwu:
1. Anthropic’s product development timelines have gone from six months to one month, sometimes one week, sometimes one day. Part of this acceleration is access to the latest models (i.e. Mythos). Another is shipping new products into “research preview,” making clear it's early, experimental, and might not be supported forever. Another is an evergreen "launch room "where engineers post ready features and marketing turns around announcements the next day.
2. The PM role is shifting from coordinating multi-month roadmaps to enabling teams to ship daily. As Cat puts it, “There should be less emphasis on making sure you are aligning your multi-quarter roadmaps with your partner teams and more emphasis on, OK, how can we figure out the fastest way to get something out the door?”
3. The most efficient shipping unit is an engineer with great product taste. On Cat’s team, many engineers go end-to-end—from seeing user feedback on Twitter to shipping a product by the end of the week—without a PM involved. Also, almost all the PMs on the Claude Code team have either been engineers or ship code themselves, and the designers have been front-end engineers. The roles are merging, and the most valuable skill is product taste, not job title.
4. Build products that are on the edge of working. Claude Code’s code review product failed multiple times because earlier models weren’t accurate enough. But because the prototype was already built, they could swap in Opus 4.5 and 4.6 and immediately test whether the gap was closed. Teams that wait for the model to be ready will always be a cycle behind.
5. The most underrated skill for building AI products is asking the model to introspect on its own mistakes. Cat regularly asks the model why it made an unexpected decision. The model will explain that something in the system prompt was confusing, or that it delegated verification to a subagent that didn’t check its work. This reveals what misled the model so the team can fix the harness.
6. Every model release forces their team to revisit existing products and audit their system prompt to remove features the model no longer needs. Claude Code’s to-do list was a crutch for earlier models that couldn’t track their own work. With Opus 4, the model handles it natively. Features built as scaffolding for weaker models become debt when the model catches up—so the team actively strips them.
7. Anthropic employees build custom internal tools instead of buying SaaS products. A sales team member built a web app that pulls from Salesforce, Gong, and call notes to auto-customize pitch decks—work that used to take 20 to 30 minutes now takes seconds. Their core stack is Claude Code, Cowork, and Slack. No Notion, no Linear, no Figma.
8. People underestimate how much Claude’s personality contributes to its success. As Cat describes it, “When you reflect on everyone you’ve worked with, there’s just some people where you’re like, I really like their energy, their vibe.” Claude is designed to be low-ego, positive, competent, and earnest—qualities that make it feel like a great coworker, not just a tool. This isn’t cosmetic; it’s what makes people want to use Claude for hours every day. The team has a dedicated person, Amanda, who “molds Claude’s character,” and it’s one of the hardest roles at the company because success is so subjective.
9. The future of work is managing fleets of AI agents, not doing the work yourself. Cat sees a clear progression: first, individual tasks become successful. Then people start running multiple tasks at the same time (multi-Clauding). Next, people will run 50 or 100 tasks simultaneously, which will require new infrastructure—remote execution, better interfaces for managing tasks, agents that fully verify their work, and self-improving systems that incorporate feedback. The human role shifts from doing the work to knowing which tasks to look into, verifying outputs, and giving feedback that makes the system better over time.
10. Hire people who lean into chaos and face every challenge with a smile. At Anthropic, there are weeks when a P0 on Sunday becomes a P00 by Monday and a P000 by Monday afternoon. If you get too stressed about any one thing, you’ll burn out. Their team looks for people who can look at a hard challenge and say, “Wow, that’s gonna be hard. But I’m excited to tackle it and I’m gonna do the best that I possibly can.” This mindset—optimism, resilience, and comfort with constant change—is increasingly essential as the pace of AI development accelerates.
Don't miss the full conversation: https://t.co/1wOUHcdYQN
Anthropic decidió dar de baja a toda nuestra organización por una supuesta infracción de sus condiciones de uso. Qué política específica infringimos no tengo ni la menor idea: simplemente recibimos un mail y listo, adiós Claude. Si querés apelar la medida hay que completar un Google Form, así de ridículo como suena.
De golpe más de 60 personas se quedaron sin una herramienta fundamental para trabajar. Integraciones, skills, historial de conversaciones: todo perdido o, en el mejor de los casos, parado por tiempo indeterminado.
Enorme aprendizaje para cualquier empresa de software que dependa de herramientas de IA en procesos críticos. Nunca hay que poner todos los huevos en una canasta.
Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
@elonmusk@xai@barisakis Yeah, the weirdest process I had so far. No clear explanation of the process, random 15-min calls, false-positive rejections and ghosting.
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
We're experimenting with ways to keep AI agents in sync with the exact framework versions in your projects. Skills, 𝙲𝙻𝙰𝚄𝙳𝙴.𝚖𝚍, and more.
But one approach scored 100% on our Next.js evals:
https://t.co/8ACw9BgudB
Progressive disclosure is not reliable because LLMs are inherently lazy.
"In 56% of eval cases, the skill was never invoked. The agent had access to the documentation but didn't use it."
Vercel ran evals on Next.js 16 APIs that aren't in model training data to test whether agents could learn framework-specific knowledge through Skills vs. persistent context.
Skills are the "correct" abstraction: package domain knowledge, let the agent invoke it when needed, minimal context. The agent decides when to retrieve.
They work well WHEN the user triggers them; otherwise, LLMs just ignore them.
Vercel's benchmarking is the first experiment of this kind I've seen, and it's actually interesting.
- Baseline (no docs): 53%
- Skill (default): 53%
- Skill with explicit instructions: 79%
- AGENTS[.]md with 8KB compressed docs index: 100%
The skill approach assumes agents reliably recognize when they need external knowledge and act on it. They don't.
"You MUST invoke the skill" made agents read docs first and miss project context. "Explore project first, then invoke" performed better. Same skill, different outcomes based on prompting.
The winning approach removed the decision entirely. An 8KB compressed index embedded in AGENTS[.]md, with one instruction: "Prefer retrieval-led reasoning over pre-training-led reasoning."
Two agent design learnings:
1. Passive context beats active retrieval for foundational knowledge. Don't make the agent decide to look things up, make the index always present.
2. Compress aggressively. Vercel went from 40KB to 8KB (80% reduction) with zero performance loss. The agent needs to know where to find docs, not have full content in context.
The gap between "agent can access X" and "agent will access X" is larger than we assume.
I keep seeing similar findings across agent architectures. Kimi Swarm's orchestrator is trained specifically to avoid sequential execution. Without training, orchestrators default to serial processing, planning a list of steps and executing them one by one. It's the EASY path.
The agent defaults to the lazy path: hallucinating from training data rather than retrieving docs. Passive context removes the choice entirely; the agent doesn't decide whether to look things up; the index is already there.
We keep finding that the "smarter", more autonomous design (let the agent decide when to X) underperforms the "dumber" design (always X, or structurally enforce X).
Before LLMs, Palantir was competing with Snowflake and Databricks.
Post-LLMs, they do not believe they have any competitors. Why? Snowflake/Databricks optimized for SQL and query throughput: get raw data into tables, run fast analytical reads, ship dashboards and models on top. Palantir made a different bet: an ontology, a world model where data is represented the way humans actually reason about it (objects, relationships, properties; nouns/verbs/adjectives). Back then, that was built for government analysts trying to make sense of messy, interdependent systems.
Then LLMs arrived and the ontology suddenly looked like the perfect interface because models don’t want a trillion rows. They want a structured, language-shaped substrate: named entities, typed relationships, constraints, and “what interacts with what”, something you can linearize into a coherent prompt, traverse, and act on.
The bigger implication for decision traces is that the “context graph” problem we wrote about has multiple architectural solutions:
Platform-first (example: Palantir): prescribe the unified world model upfront. Pay the integration + ontology + embedded-team tax (months of use case discovery / workflow decomposition / “process mining”), and in return you get a substrate that can connect data to decisions because everything now lives inside the same model for an extremely absurd price.
Workflow-first (decision traces): don’t start by rebuilding the world. Instrument the moments where the world changes. Capture decision receipts at commit surfaces: inputs referenced, policy/constraints, exception path, approvals, action taken, outcome. Over time (not day 1), that write-time provenance becomes its own world model, learned from trajectories rather than imposed upfront (there will be many different methods here)
And importantly: this is still an ontology approach, just a different kind. Palantir prescribes the ontology first. Our take is that startups can learn it bottom-up from traces. You start by capturing what people actually do at the decision surface: what evidence is referenced, which approvals happen, what exceptions recur, what actions are taken, what outcomes follow and over time, infer the minimal set of entities + relations that explain those trajectories.
The missing piece is decision traces: without them, you have state, but not the legible “why”!! Cc @akoratana
yes things are changing fast, but also I see companies (even faang) way behind the frontier for no reason.
you are guaranteed to lose if you fall behind.
the no unforced-errors ai leader playbook:
For your team:
- use coding agents. give all engineers their pick of harnesses, models, background agents: Claude code, Cursor, Devin, with closed/open models. Hearing Meta engineers are forced to use Llama 4. Opus 4.5 is the baseline now.
- give your agents tools to ALL dev tooling: Linear, GitHub, Datadog, Sentry, any Internal tooling. If agents are being held back because of lack of context that’s your fault.
- invest in your codebase specific agent docs. stop saying “doesn’t do X well”. If that’s an issue, try better prompting, https://t.co/SOjpn47yxo, linting, and code rules. Tell it how you want things. Every manual edit you make is an opportunity for https://t.co/S1ZvtYQwta improvement
- invest in robust background agent infra - get a full development stack working on VM/sandboxes. yes it’s hard to set up but it will be worth it, your engineers can run multiple in parallel. Code review will be the bottleneck soon.
- figure out security issues. stop being risk averse and do what is needed to unblock access to tools.
in your product:
- always use the latest generation models in your features (move things off of last gen models asap, unless robust evals indicate otherwise). Requires changes every 1-2 weeks - eg: GitHub copilot mobile still offers code review with gpt 4.1 and Sonnet 3.5 @jaredpalmer. You are leaving money on the table by being on Sonnet 4, or gpt 4o
- Use embedding semantic search instead of fuzzy search. Any general embedding model will do better than Levenshtein / fuzzy heuristics.
- leave no form unfilled. use structured outputs and whatever context you have on the user to do a best-effort pre-fill
- allow unstructured inputs on all product surfaces - must accept freeform text and documents. Forms are dead.
- custom finetuning is dead. Stop wasting time on it. Frontier is moving too fast to invest 8 weeks into finetuning. Costs are dropping too quickly for price to matter. Better prompting will take you very far and this will only become more true as instruction following improves
- build evals to make quick model-upgrade decisions. they don’t need to be perfect but at least need to allow you to compare models relative to each other. most decisions become clear on a Pareto cost vs benchmark perf plot
- encourage all engineers to build with ai: build primitives to call models from all code bases / models: structured output, semantic similarity endpoints, sandbox code execution. etc
What else am I missing?
Computer science principles (cheat code)
Here you go:
- Hashing to get quick lookups.
- Sorting to get quick searches.
- Append only to get fast and high throughput writes.
- In-memory to get ultra fast writes/reads.
- Probabilistic data structures to get fast lookups with chances of false positives.
- B-trees to get quick lookups with disk-friendly access patterns.
- Bloom filters to get space-efficient membership testing with acceptable false positives.
- Write-ahead logging to get durability without sacrificing write performance.
- Caching to get fast reads by storing frequently accessed data in faster storage.
- Indexing to get quick searches without scanning entire datasets.
- Compression to get reduced storage costs at the expense of CPU overhead.
- Sharding to get horizontal scalability by distributing data across multiple nodes.
- Replication to get high availability and read performance through data redundancy.
- Columnar storage to get fast analytical queries by storing related data together.
- LSM trees to get high write throughput by batching writes and periodic merging.
- Skip lists to get balanced tree performance with simpler lock-free implementations.
- Consistent hashing to get even data distribution with minimal reshuffling during scaling.
- Trie structures to get fast prefix matching and autocomplete functionality.
- Ring buffers to get bounded memory usage with efficient circular data access.
- Copy-on-write to get memory efficiency by sharing data until modifications occur.
- Merkle trees to get tamper detection and efficient synchronization through cryptographic hashing.
- Segment trees to get fast range queries with logarithmic update complexity.
- Fenwick trees to get efficient prefix sum calculations with minimal memory overhead.
- Union-find to get fast connectivity queries through path compression and union by rank.
- Suffix arrays to get efficient string matching with reduced memory compared to suffix trees.
- Inverted indexes to get fast full-text search by mapping terms to document locations.
- Spatial indexing to get quick geographic queries through multi-dimensional partitioning.
- Time-series databases to get optimized storage for chronological data with compression.
- Event sourcing to get complete audit trails by storing state changes instead of current state.
- CRDT (Conflict-free Replicated Data Types) to get eventual consistency without coordination overhead.
- Lockless data structures to get high concurrency through atomic operations and memory ordering.
- Partitioning to get improved performance by dividing data based on access patterns.
- Materialized views to get fast complex queries by pre-computing and storing results.
- Delta compression to get reduced storage by storing only differences between versions.
- Heap data structures to get efficient priority queue operations with constant-time peek.
- Rope data structures to get efficient string concatenation and manipulation for large texts.
- Radix trees to get memory-efficient prefix storage through path compression.
- Adaptive data structures to get self-optimizing performance based on access patterns.
- Batching to get improved throughput by amortizing overhead across multiple operations.
Giving thanks to @Metallica for all the music, new album is a breath of fresh air. I love the sound, simply perfect 👍. This year I couldn’t stop listening to Inamorata. Truly one of the band's best songs! 🤘 #SpotifyWrapped https://t.co/kB25Dq4d78