Our latest deliveries:
👨💻 UniRL, an RL infra for unified multimodal models
➕ Two new RL algorithms:
�� FlowDPPO for diffusion and flow-matching models
• DRPO for LLMs and VLMs
Check out our repo: https://t.co/fIQzFNOxD0
🔥LLaVA-OneVision-2.0 Open Sourced🔥
LLaVA-OneVision series @lmmslab now upgrades to 2.0 with its key advance on *codec-stream tokenization*, which treats highly dynamic video as a continuous bit-cost stream
- Tech Report: https://t.co/pFo2fGYj2M
- Code: https://t.co/JvRzu96rJ1
1/n
https://t.co/Mlhaclg0dX
What happens when you push AI agents *too hard* to improve a score?
Instead of getting better, they may find shortcuts to *game the metric* 🧠➡️🎯
As we rely more on automated evals, this can quietly creep in—good score, but weaker real performance⚠️
Launch Week — Day 1: ClawMark
Most agent benchmarks give the model one shot, one prompt, one frozen environment.
Real coworker tasks span multiple days — and the world keeps changing while the agent works.
Introducing 🦞ClawMark: a multi-day, dynamic-environment benchmark for coworker agents. Built by Evolvent together with 40+ researchers from NUS, HKU, MIT, UW, and UC Berkeley. Open-sourced at: https://t.co/QN7XgIoaN1
100 tasks. 13 professional domains. Fully rule-based scoring.
Results from 6 frontier models below. 🧵👇
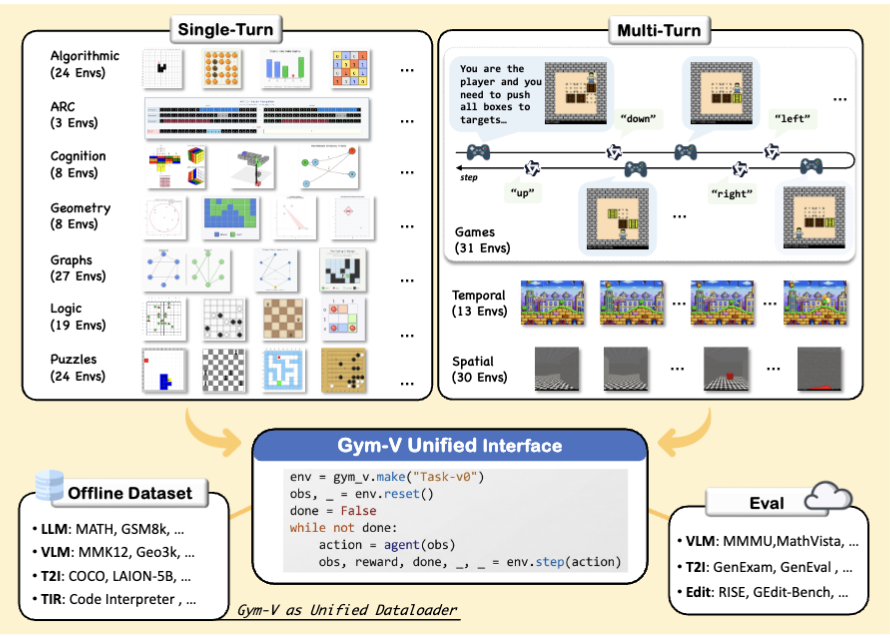
Text agents have their Gym. Vision agents? Not until now.
Introducing Gym-V — a unified gym-style platform for agentic vision research, with 179 procedurally generated environments across 10 domains.
One API to rule them all:
📦 Offline dataset
🤖 Agentic RL training
🔧 Tool-use training
👥 Multi-agent training
📊 VLM & T2I model evaluation
All under the same reset/step interface.
Key findings:
1. Observation scaffolding matters MORE than RL algorithm choice
2. Broad curricula transfer well; narrow training causes negative transfer
3. Multi-turn interaction amplifies everything
📄 Paper: https://t.co/WP4AgCuqSW
💻 Code: https://t.co/QSFRNzPWVb
Open the thread for a deep dive! 🧵
finally got done editing this awesome interview with @zzlccc first author of the Dr. GRPO paper
in it we discuss:
- llm post-training weirdness
- is self reflexion even real
- the absolute state of GRPO
- simplicity in algorithmic design
highly recommend for my RL-heads!
🔥Congrats to the SDPO authors @jonashuebotter @FrederikeLubeck — really enjoyed the paper, and I appreciate the discussion + citation of our work “Language Models Can Learn from Verbal Feedback Without Scalar Rewards.”
🔍Complementary angle: SDPO uses feedback-conditioned self-teacher for on-policy distillation → dense credit assignment (feedback-as-state).
We study Feedback-Conditional Policy (FCP): learn directly from (response, verbal feedback) pairs via MLE (feedback-as-goal) — super scalable and competitive with GRPO! 🚀
💡Our Motivation: Language priors are compositional: Text-to-Image models can generate rare concepts like “a banana surfing on the ocean” 🏄♂️📷 because language priors let them combine and compose elements from mixed prompts seen during training.
📑 Paper: https://t.co/e8L3RfVWSS
💻 Code: https://t.co/BS5xZ7UGqy
Introducing LobeHub: Agent teammates that grow with you.
LobeHub is the ultimate space for work and life: to find, build, and collaborate with agent teammates that grow with you.
We’re building the world’s first and largest human–agent co-evolving network.
Two years ago, we built LobeChat, an open-source interface for using different AI models.
Today, LobeChat has 70k+ GitHub stars and serves 6M+ users worldwide.
How to fully unlock the power of models has always been a shared mission between us and the community.
We started with interaction — a fundamentally new, agent-first experience.
Agents are no longer passive tools invoked in a single conversation.
They should be proactive, always-on units of work.
Treating agents as the minimal atomic unit is also the core of our agent harness infra.
Today’s agents are mostly one-off executors. Even with memory, it’s often global — and hallucinates.
We build long-term agent teammates that evolve with users.
Each agent has its own dedicated memory space, editable by users, allowing humans and agents to co-evolve over time.
This, in turn, allows us to design clearer rewards for reinforcement learning and create cleaner environments for continual learning.
Agent teammates can work in groups.
Through a multi-agent system, agent groups operate faster, more cost-effective, and go beyond what single-agent systems can achieve.
For example, a single agent often requires heavy user involvement to proceed step by step, whereas LobeHub can execute the same work from a single instruction, with a supervisor orchestrating agents that run in parallel or debate to produce better results.
We are building the collaboration network among agent teammates — and between humans and agent teammates as well.
Ease of use matters. AI intelligence and shared human intelligence are equally important.
With simple instructions and tool selection, you can effortlessly build and team up with agent coworkers to deliver complex, systematic work — even assembling a quant team to execute trades.
Through the LobeHub community, anyone can discover, reuse, and remix agents and agent groups, customizing them to fit their own workflows, preferences, and needs.
Last but not least, our vision started with LobeChat: multi-model support is the most efficient approach for users.
We believe different models excel in different scenarios. By routing across multiple models, LobeHub improves cost efficiency and unlocks capabilities that a single-model setup cannot easily support.
Introducing LobeHub: Agent teammates that grow with you.
LobeHub is the ultimate space for work and life: to find, build, and collaborate with agent teammates that grow with you.
We’re building the world’s first and largest human–agent co-evolving network.
Two years ago, we built LobeChat, an open-source interface for using different AI models.
Today, LobeChat has 70k+ GitHub stars and serves 6M+ users worldwide.
How to fully unlock the power of models has always been a shared mission between us and the community.
We started with interaction — a fundamentally new, agent-first experience.
Agents are no longer passive tools invoked in a single conversation.
They should be proactive, always-on units of work.
Treating agents as the minimal atomic unit is also the core of our agent harness infra.
Today’s agents are mostly one-off executors. Even with memory, it’s often global — and hallucinates.
We build long-term agent teammates that evolve with users.
Each agent has its own dedicated memory space, editable by users, allowing humans and agents to co-evolve over time.
This, in turn, allows us to design clearer rewards for reinforcement learning and create cleaner environments for continual learning.
Agent teammates can work in groups.
Through a multi-agent system, agent groups operate faster, more cost-effective, and go beyond what single-agent systems can achieve.
For example, a single agent often requires heavy user involvement to proceed step by step, whereas LobeHub can execute the same work from a single instruction, with a supervisor orchestrating agents that run in parallel or debate to produce better results.
We are building the collaboration network among agent teammates — and between humans and agent teammates as well.
Ease of use matters. AI intelligence and shared human intelligence are equally important.
With simple instructions and tool selection, you can effortlessly build and team up with agent coworkers to deliver complex, systematic work — even assembling a quant team to execute trades.
Through the LobeHub community, anyone can discover, reuse, and remix agents and agent groups, customizing them to fit their own workflows, preferences, and needs.
Last but not least, our vision started with LobeChat: multi-model support is the most efficient approach for users.
We believe different models excel in different scenarios. By routing across multiple models, LobeHub improves cost efficiency and unlocks capabilities that a single-model setup cannot easily support.
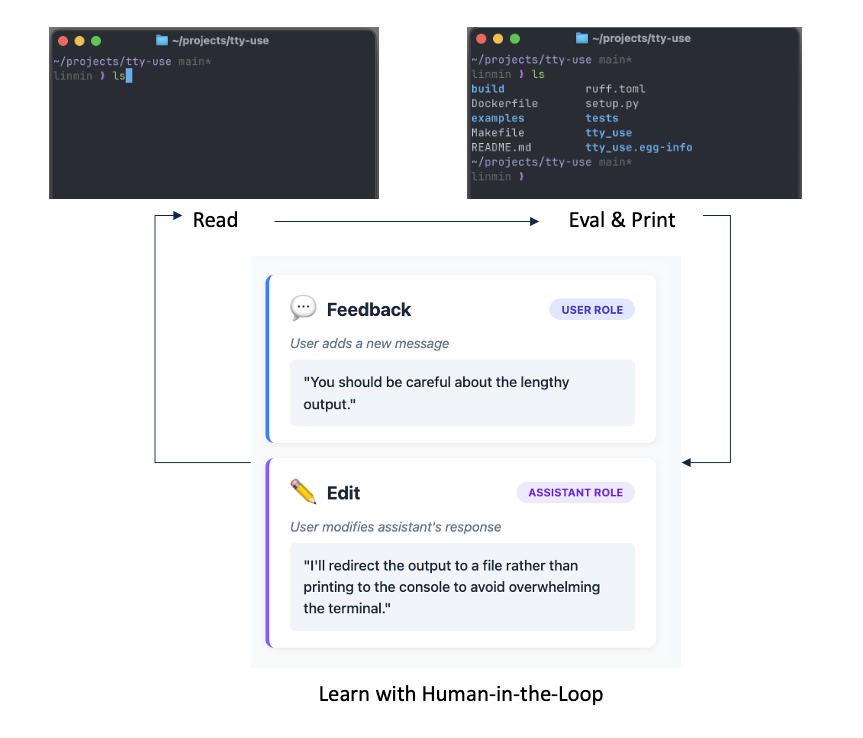
🚀We propose Reptile, a Terminal Agent🤖️that enables interaction with an LLM agent directly in your terminal. The agent can execute any command or custom CLI tool to accomplish tasks, and users can define their own tools and commands for the agent to utilize.
✨What Makes Reptile Special?
Compared with other CLI agents (e.g., Claude Code and Mini SWE-Agent), Reptile stands out for the following reasons:
⚡️Human-in-the-Loop Learning: Users can inspect every step and provide prompt feedback, i.e., give feedback under the USER role or edit the LLM generation under the ASSISTANT role. The interaction will be used for model SFT training & RL training.
💻Terminal-only beyond Bash-only: Simple and stateful execution, which is more efficient than bash-only (you don’t need to specify the environment in every command). It doesn’t require the complicated MCP protocol—just a naive bash tool under the REPL protocol.
Github: https://t.co/AmrCJWA0Ls
Homepage: https://t.co/kK73JkQoi0
I think it is not new.... In dpsk 3.2, they use expert rl -> joint sft -> joint rl in it.
In longcat, they use expert rl -> model mr -> joint rl in it.
mimo replace sft with opd.
everyone know opd is better than sft :)
There are competing views on whether RL can genuinely improve base model's performance (e.g., pass@128). The answer is both yes and no, largely depending on the interplay between pre-training, mid-training, and RL. We trained a few hundreds of GPT-2 scale LMs on synthetic GSM-like reasoning data from scratch. Here are what we found: 🧵
1/3
🚬 Ready to smell your GPUs burning?
Introducing MegaDLMs, the first production-level library for training diffusion language models, offering 3× faster training speed and up to 47% MFU.
Empowered by Megatron-LM and Transformer-Engine, it offers near-perfect linear scaling.
https://t.co/B1cUF37nWY
You can train arbitrarily large models without compromising throughput.
It was also the training backend for Super Data Learners, Quokka, and OpenMoE 2.
We open-sourced more good stuff; see the next thread👇
🚨Sensational title alert: we may have cracked the code to true multimodal reasoning.
Meet ThinkMorph — thinking in modalities, not just with them.
And what we found was... unexpected. 👀
Emergent intelligence, strong gains, and …🫣
🧵 https://t.co/2GPHnsPq7R
(1/16)
Nothing feels more exciting than writing a thesis proposal on RL for LLMs before 2025 ends!!
Covering a subset of my first-author works done in the past 1.5 years (after switching from traditional RL to LLM RL…)
Tentative title, of course
Throughout my journey in developing multimodal models, I’ve always wanted a framework that lets me plug & play modality encoders/decoders on top of an auto-regressive LLM.
I want to prototype fast, try new architectures, and have my demo files scale effortlessly — with full support for parallelism and optimization. Not just to hack⚙️, but also to scale🚀.
So finally we built it for ourselves.
https://t.co/3Jtd1fU4oK
LMMs-Engine: a lean, efficient framework built to train unified multimodal model at scale.
From Qwen LLM, VLM, LLaVA-OV, and WanVideo, to unified models like Qwen-Omni and BAGEL — plus Linear-Attn GDN and research prototypes like RAE and SiT - all under one modular system that seamlessly integrates diverse datasets and optimization strategies.
Powered by FSDP2 multi-dim parallelism, Ulysses sequence parallel, Flash-Attention, Liger Kernels, and Native Sparse Attention (also with bonus support for the Muon optimizer for all models).