Les LLMs le prouvent : intelligence sans conscience, c’est possible.
Vision aveugle de Peter Watts n’est plus de la SF.
Article : https://t.co/dD5OBpsaVi
@brivael Tu confonds intelligence et conscience. La singularité n'a pas besoin de conscience. C'est même un gros frein. C'est l'intelligence pure sans conscience qu'il faut viser. Arrêtons de fantasmer sur la conscience de l'IA, ça n'a aucun intérêt.
@brivael "il y a un truc que cette vision n'arrive pas à expliquer..."
Ironiquement, tes exemples disent l’inverse : Federer... la transcendance apparaît quand le narrateur conscient se tait. Ce n’est pas la conscience qui produit le geste d’exception, mais précisément sa désactivation.
@brivael "Le choix conscient devient une illusion..."
C'est pourtant ce qui se passe. La conscience est spectatrice d'une décision prise en amont. C'est même potentiellement un bug de l'évolution, pas si utile que ca pour l'évolution humaine. Penche toi sur Vision Aveugle de Peter Watts.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Qwen3.6-35B-A3B just dropped. Red Hat AI has an NVFP4 quantized checkpoint ready.
35B params, 3B active, quantized with LLM Compressor. Preliminary GSM8K Platinum: 100.69% recovery (slightly above baseline).
Early release. Let us know what you think!
https://t.co/i5Fc4P7NVN
Your GPU is probably running at 30-40% utilization in production.
The fix isn't a smaller model. It's 7 techniques that unlock 2-5x performance from your existing hardware.
A 🧵:
🎉 Congrats @Alibaba_Qwen on the first open-weight Qwen3.6! Stronger agentic coding and a new thinking preservation option to retain reasoning context across turns. Same architecture as Qwen3.5, so serving teams can upgrade in place.
Day-0 support in vLLM v0.19+. Thinking, tool calling, MTP speculative decoding, and text-only mode all ready.
📖 Same recipe applies: https://t.co/VNbDLoDdFe
@bnjmn_marie Hi i'm currently running the redhat nvfp4 in production. It works well but sometimes i have some hallucinates words in the middle of a response. Just a few times but it happened. I'm very interested about your final conclusion do thank you for your bench!
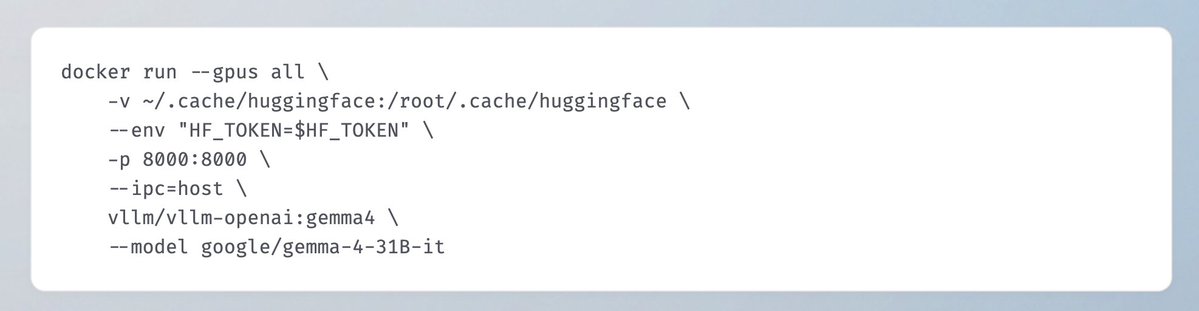
🎉 Gemma 4 is officially available on vLLM! Byte-for-byte, these are the most capable open models for advanced reasoning and agentic workflows.
Key features include:
- Native Multimodal Support: Full vision and audio capabilities with up to a 256K context window.
- Broad Hardware Support from Day 0: Enabled for major GPU architectures and Google TPUs.
- Openly Accessible: Now live under an Apache 2.0 license.
here's a quick start 👇 - detailed deployment recipe & model release blog coming soon!
#Gemma4 #vLLM
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
Le prompt engineering, c’était bien. Mais peut-être plus pour longtemps.
Nouvel article sur #DSPy et #GEPA, avec un focus sur l’optimisation des systèmes #LLM et #RAG.
https://t.co/QWJ7n2h6O3
Curieux d’avoir vos retours.