🚨: Just in: $MU
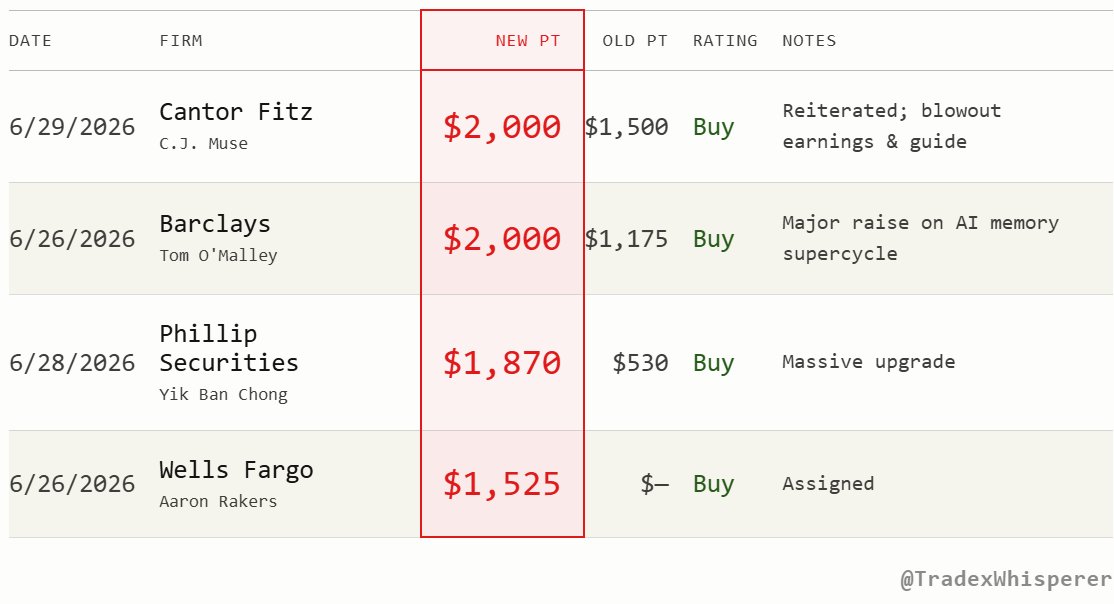
Every analyst that raised their price target after earnings is pointing to $1,500+.
- Melius Research: $2200
• Susquehanna: $2,000
• DA Davidson: $2,000
• Needham: $1,650
• TD Cowen: $1,600
• KeyBanc: $1,600
• BofA: $1,550
• JPMorgan: $1,540
• Wells Fargo: $1,525
• Wolfe Research: $1,500
• Raymond James: $1,500
• RBC Capital: $1,500
Wall Street keeps raising estimates because the AI memory cycle is just getting started. 📈
$MU CEO, 실질적으로:
"10년 이상 동안 $AAPL은 우리 칩을 $5에 사서 금속 상자 안에 붙여넣고, 소비자에게 $99 업그레이드 가격으로 팔면서 우리가 $7을 받으려는 시도를 비웃었어요.
이제 우리는 그들에게 $50을 청구하고 있는데, 그들은 돌아서서 고객들에게 $250 가격 인상을 했네요."
$MU CFO: "We intend to increase our capital return. Over time, we expect to return 100% of our excess cash to shareholders."
Analysts: "So you’re saying 100% will go back to shareholders. I assume the vast majority of that is in buyback...”
$MU CFO: “We will hold what we believe is appropriate excess cash. We’ve always said that we intend to grow the dividend over time. You saw us do a 30% increase recently, but the principal capital return we have will be share repurchase."
Citizen Vigilante just hit #1 on Amazon Prime!
This is the biggest F U to Germany and the open border globalists who really don’t want you to see this movie👇
$MU is now a top 10 holding in the S&P 500 with a 1.9% weighting.
A memory company becoming one of the largest stocks in the S&P 500 while still trading at a fraction of the market multiple shows the market still doesn't fully believe these AI memory profits will last.
Market is bearish — but these revenue numbers tell a completely different story. 👀
$LQDA $NBIS $MU $SNDK $HUT
Price is down. Revenue is exploding. This is exactly the gap that long term investors look for.
100 stocks. Every sector. AI Memory. Biotech. Clean Energy. NAND Flash. Bitcoin Mining.
All tracked inside the Tenet Momentum Picks list — scanned fresh and ready every single day. ⚡
The market dips. Strong companies keep growing. Knowing which ones are which is the entire game.
📌 Subscribe to https://t.co/VRI91w9bpu t and know exactly what you're holding before the market turns back around.
💬 Which of these tickers are you holding through the dip? Drop it below 👇
$LQDA Bofa downgrade LQDA to Neutral from Buy, while raising PT to $79 from $64, as
risk/reward looks more balanced after the stock’s YTD run. Yutrepia’s launch has
exceeded our expectations, and now raise peak sales to $2.2bn from $1.7bn. Launch supports higher PT but stock move limits upside
The creator of High Bandwidth Memory said something that reframes the entire AI investment thesis, AI equals memory (Save this).
Most people still think about AI hardware through a training lens.
During training, the bottleneck is raw compute, GPUs stay near 100% utilization crunching through billions of gradient updates.
Inference is a completely different problem.
When a model generates a response, it produces tokens one at a time and at every single step, the entire model has to be loaded from memory into the processor to generate just one token.
The GPU cores sit there, waiting for data to arrive.
This is what engineers mean when they say inference is memory bound, the bottleneck is not how many calculations you can do per second but rather how fast you can move data from memory to the chip.
Adding more GPUs does not fix a memory bandwidth problem, it just gives you more processors starving for the same data.
Modern LLMs use a KV cache, a data structure that stores the conversation's context so the model does not have to recompute it from scratch on each step.
The KV cache is what gives a model its memory of the conversation.
It grows with every token and for long documents or deep reasoning chains, it can dwarf the model weights themselves in memory consumption.
This means memory directly determines how long a context the model can hold, how many users you can serve simultaneously, how fast it responds and how cheaply you can run it.
A memory constrained model is not just slower but rather qualitatively worse, it forgets earlier parts of the conversation, truncates context and hallucinates more because it literally cannot hold the relevant information long enough to use it.
The world now spends more on inference than training, and every ChatGPT query, every Claude document analysis, every API call is an inference workload.
Inference economics, cost per token, latency, context length, concurrent users are memory problems first and compute problems second.
The companies that control memory bandwidth and supply are not suppliers to the AI trade but rather are the AI trade.
Long Micron!
Follow me @MelvinInvests for more AI, semis and the next big market themes.