🧵 PEEK: The 1k-Token Map That Just Killed the Long-Context Tax
Your LLM agent is reading the same 50k-token codebase for the 20th time.
It still doesn't know where anything is.
PEEK from @Microsoft just changed that with a 1k-token "context map" that:
• ↑ 34% accuracy
• ↓ 93–145 fewer retries
• 5.8× cheaper than prompt tuning
Here's how: 🧵
Every time you ask GPT-5 a new question about the same repo, it re-discovers:
→ File structure
→ Key classes
→ How modules connect
You're paying for the same orientation work. Again. And again.
Industry calls this "the long-context tax."
PEEK's breakthrough:
Separate "context understanding" from "task execution."
Instead of stuffing everything into the prompt or retrieving blindly, agents now maintain a tiny persistent map — like a cheat-sheet they write once and reuse forever.
The Context Map has 5 sections:
1⃣ Context Roadmap — high-level structure
2⃣ Context Understanding — key entities/relationships
3⃣ Domain Constants (if needed)
4⃣ Parsing Schemas
5⃣ Reusable Results (cached answers)
Budget: exactly 1,024 tokens.
Three modules keep it fresh without bloat:
🔍 Distiller → Extracts only transferable orientation knowledge
✏️ Cartographer → Makes clean, deduplicated edits (ADD/DELETE/REPLACE)
🗑️ Evictor → Drops low-priority items when budget fills
Separation matters: mixed roles = noise + duplication.
Tested on OOLONG + CL-bench (coding benchmarks):
MetricGain vs. ACE (SOTA)Accuracy+6–34%Iterations saved93–145 fewerCost reduction1.4–5.8× cheaper
Same base model. Same agent. Just 1k tokens of orientation cache.
Here's the efficiency secret:
Freeze the map after 1–4 queries.
You get 80%+ of the gains but near-zero maintenance cost after that.
Most "learning" systems never stop updating → wasted compute.
PEEK learns fast, then locks in.
How PEEK beats the field:
❌ RAG: retrieves fragments, no holistic structure
❌ Summarization: compresses content, not orientation
❌ ACE/prompt tuning: optimizes tasks, not context understanding
✅ PEEK: caches the mental model your agent should have built on day 1
Devil's advocate:
PEEK wins when context is structured and queries recur.
If you're writing one-off creative fiction or chatting about random PDFs, the map has less to cache.
But for repos, enterprise docs, analytics? This is the new baseline.
Traditional stack:
→ Bigger context windows
→ Better retrieval
→ Smarter prompts
New stack:
→ Bigger context windows
→ Better retrieval
→ Persistent orientation caches
Context understanding just became a first-class versioned artifact.
Two multipliers you can stack today:
1⃣ PEEK-style maps (↓ redundant reasoning)
2⃣ KV-cache optimizations (↓ redundant token processing)
Combine them = multiplicative inference savings.
The next wave of agent infra will bake both in by default.
If you're building agents that interact with the same long contexts repeatedly:
→ Stop re-engineering prompts every query
→ Start caching orientation knowledge
The 1k-token map is the missing cache layer. Use it.
/end 🧵
@nderi_j While it carries little credit risk (banks rarely default on overnight loans to each other), it carries massive liquidity risk. In a debt-distressed economy, the "price" of liquidity is never free of risk. After a year plot Tbill rate and interbank rate) over time.
@nderi_j While efficient in stable markets, KESONIA strips away borrower protections. By pegging loans to volatile overnight rates, it ensures that government fiscal mismanagement immediately hits households and businesses.
@nderi_j The base rate is calculated by looking at the interest rate banks pay on customer deposits (savings accounts, fixed deposits), not just what they charge each other.
@nderi_j The @CBKKenya should consider alternatives that protect SMEs, youth, and citizens using less volatile means such as 90 day rolling average of the interbank rate OR even better: Cost of funds index.
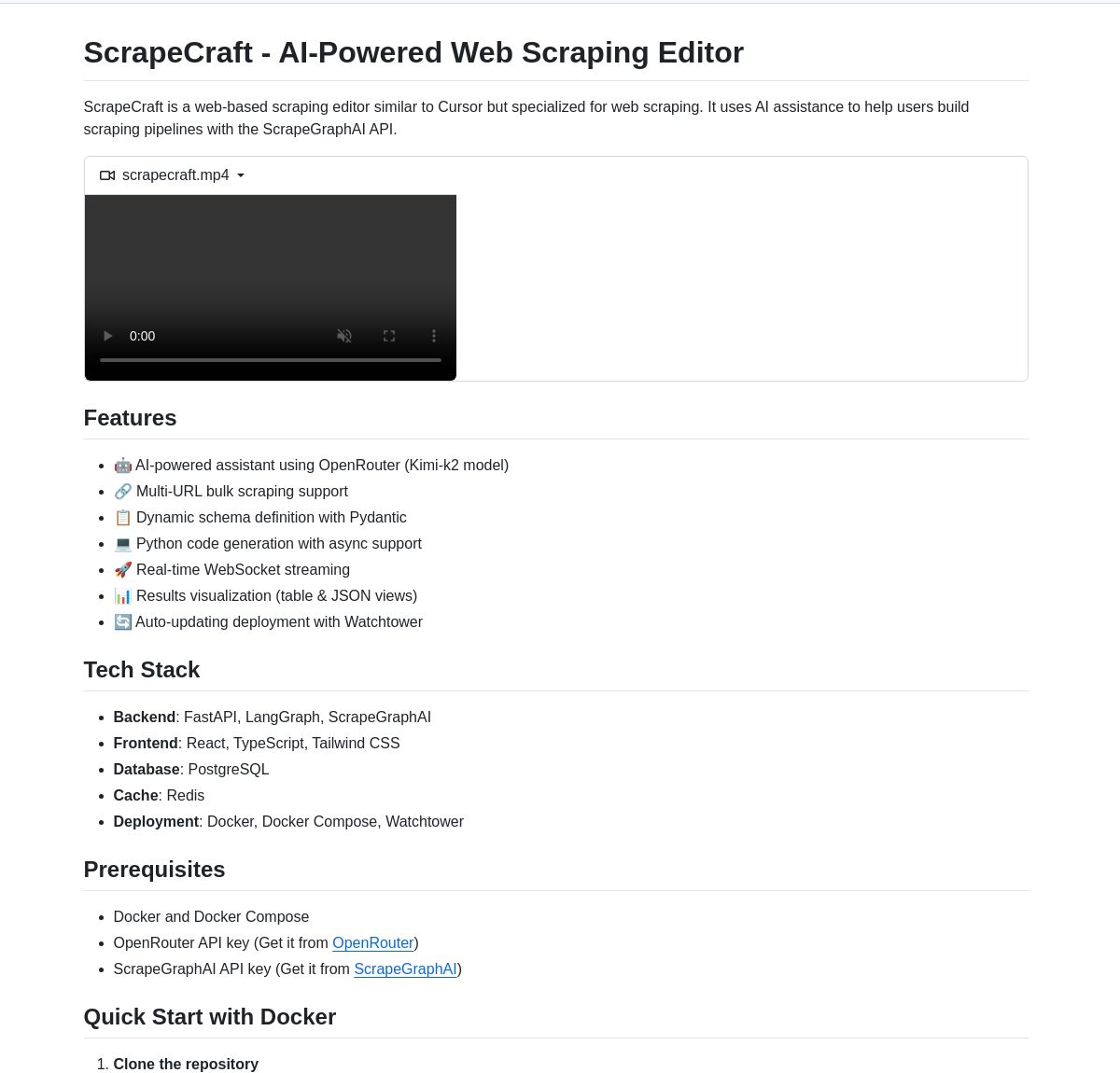
🤖 🕸️ ScrapeCraft: AI-Powered Scraping
ScrapeCraft uses LangGraph to combine AI assistance with powerful web scraping. Features include bulk URL scraping, real-time data streaming, and AI-powered pipeline generation.
Explore the project on GitHub! 🚀
https://t.co/FXkM2RTygd