De l'IA bien française :
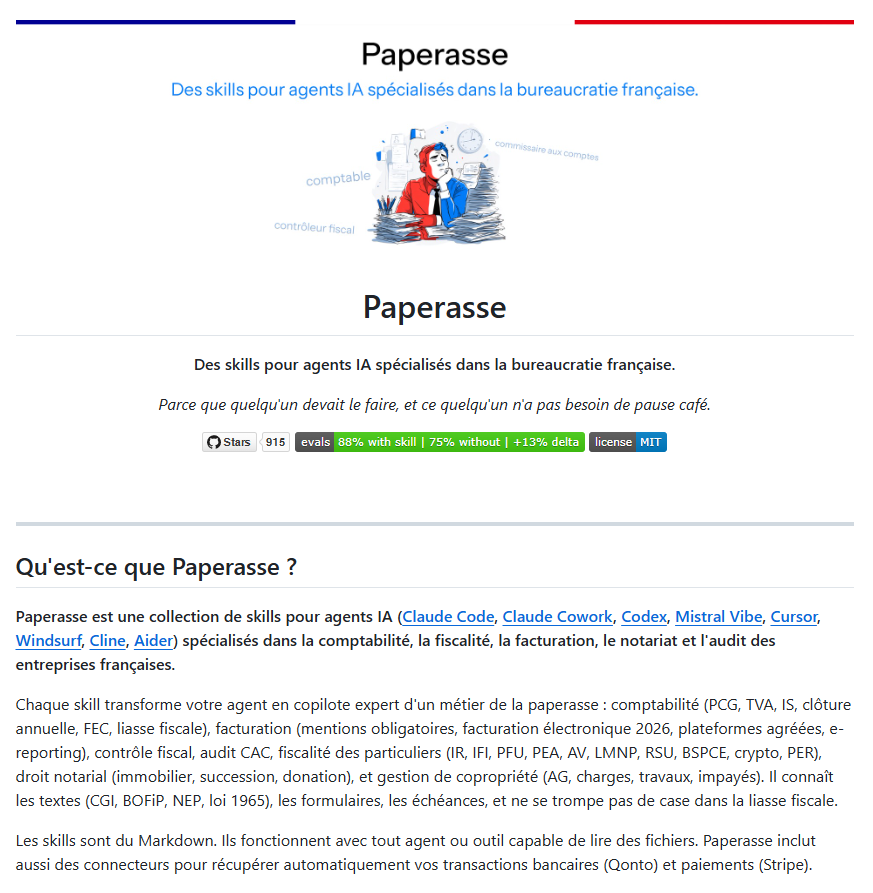
@romainsimon a produit un ensemble de "skills" qu'on peut faire apprendre à des agents type Codex, Claude.Code, etc. pour qu'ils puissent aider à remplir les cerfas et autres pénibleries administratives françaises.
https://t.co/B1ga6DaYw5
J'ai fait un call avec un pote qui vient pas de la tech et qui voulait apprendre à vibe-coder.
L'IA lui avait pondu un programme d'apprentissage qui partait direct dans les frameworks, les bases de données, les APIs.
C'est exactement ce qu'il faut pas faire.
Avant de toucher à tout ça, il y a un truc à comprendre, et c'est faisable en un bon week-end avec l'IA aujourd'hui.
Les data structures et les algorithmes.
Pourquoi c'est la base avant tout le reste.
Parce que tout en software passe par une seule chose: la modélisation de la donnée.
Une app de messagerie, c'est des messages liés à des utilisateurs liés à des conversations. Un réseau social, c'est des posts, des relations, des feeds. Un jeu, c'est des entités avec des états.
Avant d'écrire une ligne de code, la vraie question c'est: comment je représente ce truc en mémoire.
Les data structures c'est exactement ça. Des manières différentes d'organiser la donnée selon ce que tu veux en faire.
Un array quand l'ordre compte et que tu veux itérer. Un hashmap quand tu veux retrouver un truc par une clé instantanément. Un set quand tu veux des trucs uniques. Une linked list quand tu insères au milieu tout le temps. Un arbre quand t'as une hiérarchie. Un graph quand t'as des relations dans tous les sens.
Choisir la bonne structure c'est 80% du travail de conception. Le reste c'est de la plomberie.
Les algorithmes derrière c'est juste comment tu manipules ces données.
Trier, chercher, filtrer, traverser, transformer.
Exemple concret: ton feed Twitter. Les tweets sont stockés quelque part, mais comment tu les classes par date ? Comment tu trouves les plus likés ? Comment tu remontes le thread d'une réponse jusqu'à l'origine ? Chacune de ces questions appelle un algo différent sur une structure différente.
Quand t'as ça dans la tête, le reste devient évident.
Une base de données c'est juste des structures de données persistées avec des index dessus. Une API c'est juste un protocole pour passer ces données entre deux machines. Un framework c'est juste une convention pour organiser le code qui manipule ces données.
Sans la base, tu pilotes l'IA à l'aveugle. Tu sais pas pourquoi elle te propose tel design, t'arrives pas à débugger quand ça casse, tu peux pas juger si ce qu'elle pond a du sens.
Avec la base, l'IA devient un accélérateur réel. Tu sais ce que tu veux, tu sais reconnaître quand elle se trompe, tu sais reformuler.
Le programme que je lui ai donné pour le week-end:
Samedi matin: comprendre les structures de base. Array, hashmap, set, linked list. Pour chacune, demander à l'IA un exemple concret d'usage et coder un mini cas.
Samedi aprem: trees et graphs. Coder un système de commentaires imbriqués, puis un mini réseau d'amis avec recherche du chemin entre deux personnes.
Dimanche matin: les algos de base. Tri, recherche binaire, parcours en largeur et en profondeur. Pas besoin d'apprendre par coeur, juste comprendre l'intuition et quand chacun s'applique.
Dimanche aprem: un projet qui combine tout. Genre un mini moteur de recommandation, ou un système de cache, ou un parseur d'expression mathématique.
Et tout ça en pair programming avec l'IA. Tu lui demandes d'expliquer, tu codes toi-même, tu casses, tu fais réparer, tu redemandes pourquoi.
En deux jours t'as les fondations qui te permettent de comprendre 90% de ce que tu liras ensuite.
Les frameworks changent tous les ans. Les data structures sont les mêmes depuis 50 ans.
Google vient de publier un papier qui compresse les LLMs à 3 bits. 8x plus rapide, 6x moins de mémoire. Zéro perte de performance 🤯🤯🤯
Le truc c'est que la méthode est élégante au point d'en être presque triviale une fois qu'on la comprend.
Ça s'appelle TurboQuant. Je vous vulgarise tout le paper :
Déjà, le problème de base.
Quand un LLM génère du texte, il doit se "souvenir" de tout ce qu'il a lu et écrit avant. Ce système de mémoire s'appelle le KV cache (key-value cache).
Imaginez un étudiant qui prend des notes ultra détaillées pendant un cours. Plus le cours est long, plus ses notes prennent de place sur son bureau. À un moment il n'a plus de place pour écrire.
C'est exactement ce qui se passe avec les LLMs : plus le contexte est long, plus le KV cache explose en mémoire. C'est un des plus gros bottlenecks de l'inférence aujourd'hui.
La solution classique c'est la quantization. L'idée est simple : au lieu de stocker chaque nombre avec une précision extrême (32 bits, genre 3.14159265...), tu le stockes avec moins de précision (4 bits, genre "~3").
C'est comme passer d'une photo RAW de 50 MB à un JPEG de 2 MB. Tu perds un peu de détail mais visuellement c'est quasi pareil.
Le problème c'est que les méthodes classiques de quantization trichent un peu. Pour chaque petit bloc de données compressé, elles doivent stocker des "constantes de calibration" en pleine précision.
C'est comme si pour chaque photo JPEG vous deviez garder un petit post-it en haute résolution à côté qui dit "voilà comment décoder cette image".
Ces post-its rajoutent 1 à 2 bits par nombre. Quand tu essaies de compresser à 2 ou 3 bits, cet overhead représente une part énorme de ta mémoire totale. Ça annule une bonne partie du gain.
TurboQuant résout ça en deux étapes.
Étape 1 : PolarQuant.
Au lieu de décrire un vecteur avec des coordonnées classiques (X, Y, Z), tu le convertis en coordonnées polaires : une distance + un angle.
C'est comme remplacer "va 3 rues à l'est puis 4 rues au nord" par "va 5 rues direction 37 degrés". Même info, format plus compact.
L'astuce c'est qu'avant de faire ça, tu appliques une rotation aléatoire sur tes vecteurs. Ça rend leur distribution prévisible et uniforme. Du coup tu n'as plus besoin de stocker les fameuses constantes de calibration, la géométrie fait le travail toute seule.
Étape 2 : QJL (Quantized Johnson-Lindenstrauss).
Après PolarQuant il reste une petite erreur résiduelle. QJL la corrige avec 1 seul bit par nombre.
Le principe vient d'un théorème mathématique qui dit qu'on peut projeter des données de haute dimension dans un espace plus petit tout en préservant les distances entre les points.
QJL pousse ça à l'extrême : il réduit chaque valeur projetée à juste son signe (+1 ou -1). Un seul bit. Et grâce à un estimateur spécial qui combine la query en haute précision avec ces données ultra compressées, le modèle calcule toujours des scores d'attention précis.
Les résultats sont assez dingues.
Sur les benchmarks long-context (LongBench, Needle in a Haystack, RULER...) avec Gemma et Mistral : zéro perte de performance à 3 bits. Le KV cache est réduit d'un facteur 6x. Et sur H100, le calcul des scores d'attention est jusqu'à 8x plus rapide qu'en 32 bits.
Le tout sans aucun fine-tuning ou entraînement supplémentaire. Tu branches, ça marche.
Et le plus intéressant : ça ne sert pas qu'aux LLMs.
TurboQuant surpasse aussi les méthodes state of the art en vector search, c'est à dire la techno qui permet de chercher par similarité dans des bases de milliards de vecteurs (ce qui fait tourner Google Search, les systèmes de recommandation, le RAG...).
Mon take : l'inférence c'est là où se joue la vraie bataille économique de l'AI.
Les marges de toute l'industrie dépendent du coût par token en production. Un gain de 6 à 8x sur la mémoire et la vitesse d'inférence, sans aucune perte de qualité, ça change fondamentalement l'équation.
Ce type de recherche ne fait pas de bruit sur Twitter mais son impact business est potentiellement supérieur à celui d'un nouveau foundation model.
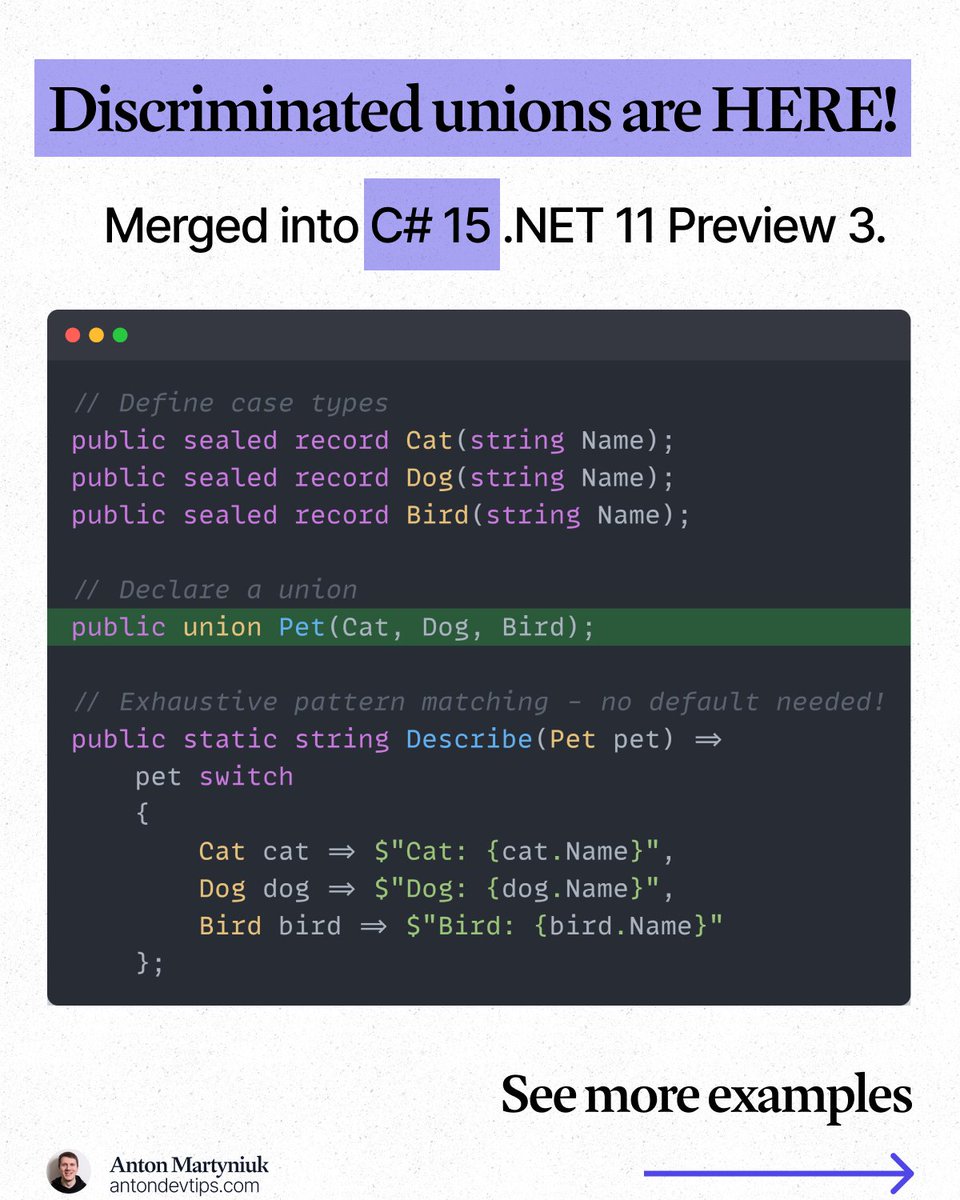
𝗖# 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿𝘀 𝘄𝗮𝗶𝘁𝗲𝗱 𝟱 𝘆𝗲𝗮𝗿𝘀 𝗳𝗼𝗿 𝘁𝗵𝗶𝘀 𝗳𝗲𝗮𝘁𝘂𝗿𝗲
Discriminated unions were merged in .NET 11 Preview 3
Discriminated Unions are finally here.
This is the #1 most requested C# language feature.
And it changes how you model results, errors, and state - forever.
Before unions, returning multiple outcomes from a method was painful.
Here is what most developers did:
❌ Threw exceptions for control flow → expensive and hidden
❌ Returned nullable types → no way to express "why" it failed
❌ Used boolean flags with nullable fields → invalid states everywhere
❌ Relied on third-party libraries → extra dependency
❌ Built own Result Types
All of these approaches had one thing in common:
➡️ The compiler could not help you.
If you forgot to handle a case - you found out at runtime.
📌 𝗖# 𝟭𝟱 𝗶𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗲𝘀 𝘁𝗵𝗲 "𝘂𝗻𝗶𝗼𝗻" 𝗸𝗲𝘆𝘄𝗼𝗿𝗱
Now you can define a type that holds exactly one of several possible types.
The compiler knows the full set of options (some compiler features are still in progress).
Here is what unions give you:
𝟭. 𝗖𝗹𝗼𝘀𝗲𝗱 𝘀𝗲𝘁 𝗼𝗳 𝗼𝘂𝘁𝗰𝗼𝗺𝗲𝘀
→ a union can only be one of the declared types
𝟮. 𝗘𝘅𝗵𝗮𝘂𝘀𝘁𝗶𝘃𝗲 𝗽𝗮𝘁𝘁𝗲𝗿𝗻 𝗺𝗮𝘁𝗰𝗵𝗶𝗻𝗴
→ the compiler warns you if a case is missing
𝟯. 𝗡𝗼 𝗱𝗲𝗳𝗮𝘂𝗹𝘁 𝗯𝗿𝗮𝗻𝗰𝗵 𝗻𝗲𝗲𝗱𝗲𝗱
→ when all cases are handled, you are done
𝟰. 𝗜𝗺𝗽𝗹𝗶𝗰𝗶𝘁 𝗰𝗼𝗻𝘃𝗲𝗿𝘀𝗶𝗼𝗻𝘀
→ assign case types directly to the union variable
𝟱. 𝗩𝗶𝘀𝗶𝗯𝗹𝗲 𝗰𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀
→ the method signature tells the full story
This is a massive shift in how we write C# code.
Unions work beautifully with pattern matching and switch expressions that C# already has.
In future .NET preview releases, we expect more features for discriminated unions and their official support in ASP .NET Core.
👉 If you want to be up to date with the latest .NET features and reach the top 1% of .NET developers, join 24,000+ engineers reading my .NET Newsletter: https://t.co/XJ8ufNM2yg
——
♻️ Repost to help other .NET developers discover discriminated unions
➕ Follow me ( @AntonMartyniuk ) to improve your .NET and Architecture Skills
J'ai vendu presque 2 millions d'euros de formations en ligne.
Après 7 ans, je passe à autre chose.
Et je donne tout. Gratuitement.
Pour avancer, faut savoir lâcher. Et en ce moment ce qui me fait vibrer c'est le dev agentique, le développement de SaaS, les agents IA. J'ai jamais été aussi excité.
Et aujourd'hui j'ai rien à te vendre. Rien. Zéro. Juste un mec passionné qui donne ce qu'il a construit.
Mes formations - Next Mastery, TypeScript Pro, React Mastery, System Freelance, Agile Scrum - elles sont toujours à jour. Les fondamentaux restent cruciaux. C'est moi qui pars vers d'autres aventures.
Plutôt que les laisser dormir, autant qu'elles servent à ceux qui ont le courage de bosser les bases pour de vrai.
🎥 https://t.co/CKeDNxZAM5
30 security rules for AI VIBE CODING :
1. Set session expiration (JWT max 7 days + refresh rotation)
2. Never use AI-built auth. Use Clerk, Supabase Auth, or Auth0
3. Never paste API keys into AI chats. Use process.env
4. .gitignore is your first file in every project, not the last
5. Rotate secrets every 90 days minimum
6. Verify every package the AI suggests actually exists before installing
7. Always ask for newer, more secure package versions
8. Run npm audit fix right after building
9. Sanitize every input. Use parameterized queries always
10. Enable Row-Level Security from day one
11. Remove all console.log statements before shipping
12. CORS should only allow your production domain. Never wildcard
13. Validate all redirect URLs against an allow-list
14. Apply auth + rate limits to every endpoint, including mobile APIs
15. Rate limit everything from day one. 100 req/hour per IP is a start
16. Password reset routes get their own strict limit (3 per email/hour)
17. Cap AI API costs in your dashboard AND in your code
18. Add DDoS protection via Cloudflare or Vercel edge config
19. Lock down storage buckets. Users should only access their own files
20. Limit upload sizes and validate file type by signature, not extension
21. Verify webhook signatures before processing any payment data
22. Use Resend or SendGrid with proper SPF/DKIM records
23. Check permissions server-side. UI-level checks are not security
24. Ask the AI to act as a security engineer and review your code
25. Ask the AI to try and hack your app. It will find things you won't
26. Log critical actions: deletions, role changes, payments, exports
27. Build a real account deletion flow. GDPR fines are not fun
28. Automate backups and test restoration. An untested backup is nothing
29. Keep test and production environments completely separate
30. Never let test webhooks touch real systems
Ship fast. But ship secure.
Honnêtement, c’est une très bonne question… mais ce n’est pas une question pour un senior. Dans mon monde, cette question a elle seule est destinee a un junior ou a un stagiaire.
Et je vais être volontairement exigeant: pour moi, ce niveau devrait déjà être maîtrisé en sortie de licence en informatique. Comprendre concrètement ce qui se passe derrière une requête HTTP (réseau, transport, sécurité, application) fait partie des fondamentaux qu’on devrait enseigner beaucoup plus rigoureusement dans nos cursus. Je ne suis pas entrain de critiquer les juniors. Je suis surtout entrain de critiquer la façon dont on forme encore.
Concrètement, pour un profil junior (entry-level), j’attends qu’on sache expliquer clairement le chemin nominal quand on tape https://google[.]com:
– comment la machine trouve où envoyer le paquet (subnet, default gateway, ARP et cache ARP)
– comment le nom de domaine est résolu (caches, resolver, DNS, TTL, A/AAAA, parfois CNAME, et le fait que DNS n’est pas toujours simplement "UDP")
– comment une connexion est établie (TCP 3-way handshake et options de base)
– comment la sécurité est mise en place (TLS, certificat, SNI, chaîne de confiance, ALPN)
– et enfin comment la requête HTTP est réellement envoyée (en pratique, plusieurs requêtes pour charger une page)
Et surtout, un junior solide doit comprendre la réponse à la fameuse question "keep-alive": si la même connexion est réellement réutilisée, on évite le handshake TCP et le handshake TLS. DNS et ARP, eux, peuvent aussi être évités… mais uniquement grâce aux caches et à leurs TTL. Keep-alive concerne la connexion, pas toute la chaîne.
Ça, pour moi, c’est déjà un socle minimum et non negotiable.
Là où on reconnaît un vrai profil senior DevOps (SRE), ce n’est pas dans la récitation de cette séquence idéale. C’est dans la capacité à expliquer la vraie vie des systèmes modernes. Par exemple:
– HTTP/2 et le multiplexing sur une seule connexion
– HTTP/3 et QUIC (donc plus de TCP, et TLS intégré au transport)
– DNS over HTTPS / DNS over TLS
– la négociation réelle via ALPN
– la réutilisation de connexions, le connection pooling et la TLS session resumption (tickets / PSK, parfois 0-RTT)
Un senior doit aussi intégrer tout ce qui se met entre le client et l’origin: CDN, reverse proxies, WAF, load balancers L4/L7, NAT, parfois service mesh et mTLS. Dans beaucoup d’architectures, le navigateur ne parle même jamais directement au serveur applicatif.
Et surtout, un senior doit être capable de parler de ce qui casse réellement en production: DNS qui répond en SERVFAIL, propagation ratée, split-horizon, TTL trop agressifs, timeouts de NAT ou de load balancer qui cassent le keep-alive, problèmes de MTU et de path MTU discovery, pertes de paquets et congestion TCP, erreurs TLS (SNI, chaîne de certificats, expiration, horloge, ciphers, ALPN), ou encore erreurs générées par les proxies et les WAF.
Et il doit être capable d’expliquer comment on isole le problème: dig, curl -v, openssl s_client, tcpdump, métriques de latence, logs de proxy/LB, corrélation avec les déploiements, etc.
Donc oui: connaître ARP, DNS, TCP, TLS et HTTP est indispensable. Mais ce n’est pas ce qui fait un senior a mon avis. Ce qui fait la différence, c’est la capacité à comprendre comment ces couches interagissent dans une architecture réelle, sous charge, avec des intermédiaires, des timeouts, des caches… et à diagnostiquer rapidement quand tout ne se passe plus comme dans le schéma parfait des slides.
Et franchement, on devrait déjà apprendre beaucoup mieux ces bases à l’université surtout a l'ere de l'IA.
Voici comment j’utilise Claude Code au quotidien.
Je n'utilise Claude Code que dans le terminal. D’abord, je configure mon claude .md. Il contient les pratiques de code que je veux que Claude suive, les commandes à lancer et l’architecture de mon projet. Bref, tout le contexte que je veux persistant entre les sessions.
Ensuite, j’écris les specs de ma feature dans un document. Je réfléchis à ce que je veux, puis, quand je pense avoir bien designé ma feature, je les copie-colle dans Claude Code avec une commande custom.
Ma commande custom va planifier (elle simule le mode plan intégré), elle va demander à Claude de me questionner sur les specs pour bien comprendre la feature et ne rien rater, puis elle va explorer mon code en lançant mes agents custom (voir plus bas). Et ensuite, une fois que je valide son raisonnement, elle va rédiger le plan de dev complet, étape par étape, dans un fichier .md, avec toutes les explications des choix.
Ce fichier est selon moi le plus important après le claude .md. C’est ce fichier qui permet de développer de grosses features bloc par bloc sans faire halluciner Claude. Pour avoir un résultat parfait, je lance un chat par phase de développement. L’idée est de ne jamais dépasser la fenêtre de contexte et de ne jamais utiliser le mode auto-compact.
Pour faire développer une feature phase par phase, par exemple si c’est une API, je lance ma commande /dev-backend.
Cette commande ne fait rien de magique. Elle est configurée pour donner un contexte standardisé à chaque phase de développement et surtout orchestrer mes sub-agents custom.
Claude va lancer mes agents d’exploration, qui sont des agents d’analyse. Ils peuvent être par exemple explore-codebase, explore-db, explore-doc, web-search, etc. Chaque agent va explorer le code de manière indépendante, avec une tâche spécifique que Claude lui aura donnée, et de manière parallèle.
L’idée est de scanner tout le code nécessaire à ma feature afin de ne rien rater et de réutiliser le code au maximum. Ils ont chacun leur propre fenêtre de contexte et retournent uniquement le résultat utile au chat principal. Même fonctionnement pour l’agent explore-db qui explore ma DB, ou pour explorer la doc (context7), ou chercher sur le web des informations à jour.
Grâce à ces sous-agents configurés pour mon architecture et exécutés automatiquement par Claude, vous verrez sur le screen que j’ai économisé 225k tokens sur ma fenêtre principale.
Claude a maintenant en contexte toute mon architecture complète, ses instructions, ce qu’il doit modifier, les patterns à respecter, les modules à réutiliser, les librairies que j’utilise, le contexte global de la feature que je veux développer et celui de mon projet. Et surtout, grâce à ces agents, il lui reste 40 % de la fenêtre disponible uniquement pour écrire le code que je demande. Ce qui est très large et donne du très bon code.
Quand il aura terminé, je vérifie que tout s’est bien passé. Puis, dans un nouveau chat, je lui demande de lancer des tests. Ensuite, je vérifie moi aussi manuellement les résultats.
Puis, une fois que tout est ok, je lance une commande qui va regarder les changements que Claude a faits, les analyser en profondeur avec les agents d’exploration, puis les optimiser, nettoyer le mauvais code, vérifier qu’il a bien respecté les bonnes pratiques du claude md, etc.
Cette dernière commande rend le code production-ready. Comme elle n’écrit pas le code mais fait uniquement la review, elle suit parfaitement mes instructions. En finalité, le code est de bonne qualité.
Ça, c’est mon process de développement optimisé. Pour vous, débutants sur Claude, vous n’avez pas besoin des sub-agents (au début). Vous pouvez lancer le mode plan par défaut à chaque début de session, avec le mode thinking activé. Claude fera le plan de développement et lancera lui aussi des sub-agents pour explorer le code.
Le seul problème avec le mode plan sans sub-agents custom, c’est que son exploration est plus lente et moins structurée. Et parfois, il va exécuter des tâches directement dans la fenêtre principale au lieu des sub-agents, ce qui consomme plus de tokens.
Mais le mode plan intégré suffit largement les premiers mois sur l’outil.
Je vais vous mettre en commentaire le lien GitHub d’un dev français que je trouve super. Il fait de bonnes vidéos YouTube et a une utilisation intelligente des sub-agents. Je vous partagerai un exemple généraliste de commande et un exemple généraliste de sub-agents.
Mais pour créer vos propres slash commands et sub-agents, je vous conseille plutôt de demander à Claude de vous écrire les commandes à partir du prompt suivant. À lancer en mode plan : « Avant de commencer, va lire toutes les guidelines officielles avec web search :
(lien en commentaire)
Une fois que tu as lu la documentation, aide-moi à développer la commande X ou le sub-agent Y.
Cet agent/commande doit faire : [insérer votre besoin].
Ils doivent impérativement respecter les bonnes pratiques de Claude.
Questionne-moi sur la commande/agent si tu n’as pas tout compris. Pour voir s’ils sont utiles ou non. »
Il ne vous restera plus qu’à activer le plugin Context7 pour explorer de la documentation à jour, et vous pourrez tout faire.
Il y a une confusion conceptuelle profonde dans ce raisonnement: assimiler la production de code à la pratique du génie logiciel.
Le coût marginal de l’écriture syntaxique du code tend effectivement vers zéro avec les LLM. Mais ce coût n’a jamais été le cœur de la valeur du métier.
Le génie logiciel n’est pas un problème de génération de texte. C’est un problème de modélisation, de gestion de la complexité, de prise de décisions irréversibles sous incertitude, et surtout de responsabilité dans le temps. Un système réel n’échoue pas parce que “le code est mal écrit”. Il échoue parce que:
– le modèle mental du domaine est faux
– les invariants ne sont pas compris
– les hypothèses implicites ne sont pas explicitées
– les compromis ne sont pas assumés
Aucune IA ne peut aujourd’hui assumer ces choix à ta place. Elle peut les proposer. Elle ne peut ni les porter, ni en répondre.
Il y a aussi un signal faible mais révélateur dans l’idée que “l’IA fait tout”. Lorsque l’IA peut produire l’intégralité d’un système sans résistance intellectuelle, ce n’est généralement pas le signe d’une prouesse technologique, mais celui d’un problème peu profond, peu contraint, ou déjà largement standardisé. Les problèmes réellement intéressants, ceux qui touchent au réel, aux humains, aux organisations, aux contraintes juridiques, physiques ou sociales résistent. Ils forcent à penser, à arbitrer, à revenir en arrière, à douter.
L’analogie avec l’assembleur, les langages compilés et les langages interprétés est trompeuse. Ces transitions ont changé le niveau d’abstraction, pas la nature du travail. Comprendre les contraintes sous-jacentes est resté indispensable.
La “programmation en langage naturel” n’abolit pas la complexité.
Elle la déplace, souvent vers des zones moins visibles, plus dangereuses, et plus coûteuses à corriger.
Former des ingénieurs n’a jamais consisté à leur apprendre à “écrire des lignes”. Il s'agit de leur apprendre à penser des systèmes qui survivront à: la croissance, les pannes, les usages imprévus, le temps, etc.
Les LLM sont des multiplicateurs de productivité extraordinaires. Mais comme tous les multiplicateurs, ils amplifient la compétence… ou l’absence de compétence.
Le futur n’oppose pas “diplômés” et “vibe coders”. Il oppose ceux qui comprennent profondément les systèmes qu’ils construisent
à ceux qui confondent vitesse de génération et maîtrise.
La production de code n’a jamais été le travail. L’ingénierie, si.
RIP prompt engineering ☠️
This new Stanford paper just made it irrelevant with a single technique.
It's called Verbalized Sampling and it proves aligned AI models aren't broken we've just been prompting them wrong this whole time.
Here's the problem: Post-training alignment causes mode collapse. Ask ChatGPT "tell me a joke about coffee" 5 times and you'll get the SAME joke. Every. Single. Time.
Everyone blamed the algorithms. Turns out, it's deeper than that.
The real culprit? 'Typicality bias' in human preference data. Annotators systematically favor familiar, conventional responses. This bias gets baked into reward models, and aligned models collapse to the most "typical" output.
The math is brutal: when you have multiple valid answers (like creative writing), typicality becomes the tie-breaker. The model picks the safest, most stereotypical response every time.
But here's the kicker: the diversity is still there. It's just trapped.
Introducing "Verbalized Sampling."
Instead of asking "Tell me a joke," you ask: "Generate 5 jokes with their probabilities."
That's it. No retraining. No fine-tuning. Just a different prompt.
The results are insane:
- 1.6-2.1× diversity increase on creative writing
- 66.8% recovery of base model diversity
- Zero loss in factual accuracy or safety
Why does this work? Different prompts collapse to different modes.
When you ask for ONE response, you get the mode joke. When you ask for a DISTRIBUTION, you get the actual diverse distribution the model learned during pretraining.
They tested it everywhere:
✓ Creative writing (poems, stories, jokes)
✓ Dialogue simulation
✓ Open-ended QA
✓ Synthetic data generation
And here's the emergent trend: "larger models benefit MORE from this."
GPT-4 gains 2× the diversity improvement compared to GPT-4-mini.
The bigger the model, the more trapped diversity it has.
This flips everything we thought about alignment. Mode collapse isn't permanent damage it's a prompting problem.
The diversity was never lost. We just forgot how to access it.
100% training-free. Works on ANY aligned model. Available now.
Read the paper: arxiv. org/abs/2510.01171
The AI diversity bottleneck just got solved with 8 words.
I just created a step-by-step guide to help you self-host n8n
This is the exact setup we use to build unlimited AI agents without paying $20K/year on tools like Zapier
Want this premium guide for FREE?
👉 RT + Like & Comment “free” and I’ll DM it to you
No sign-in, no BS
(Must be following)





























![AureaLibe's tweet photo. Voici comment j’utilise Claude Code au quotidien.
Je n'utilise Claude Code que dans le terminal. D’abord, je configure mon claude .md. Il contient les pratiques de code que je veux que Claude suive, les commandes à lancer et l’architecture de mon projet. Bref, tout le contexte que je veux persistant entre les sessions.
Ensuite, j’écris les specs de ma feature dans un document. Je réfléchis à ce que je veux, puis, quand je pense avoir bien designé ma feature, je les copie-colle dans Claude Code avec une commande custom.
Ma commande custom va planifier (elle simule le mode plan intégré), elle va demander à Claude de me questionner sur les specs pour bien comprendre la feature et ne rien rater, puis elle va explorer mon code en lançant mes agents custom (voir plus bas). Et ensuite, une fois que je valide son raisonnement, elle va rédiger le plan de dev complet, étape par étape, dans un fichier .md, avec toutes les explications des choix.
Ce fichier est selon moi le plus important après le claude .md. C’est ce fichier qui permet de développer de grosses features bloc par bloc sans faire halluciner Claude. Pour avoir un résultat parfait, je lance un chat par phase de développement. L’idée est de ne jamais dépasser la fenêtre de contexte et de ne jamais utiliser le mode auto-compact.
Pour faire développer une feature phase par phase, par exemple si c’est une API, je lance ma commande /dev-backend.
Cette commande ne fait rien de magique. Elle est configurée pour donner un contexte standardisé à chaque phase de développement et surtout orchestrer mes sub-agents custom.
Claude va lancer mes agents d’exploration, qui sont des agents d’analyse. Ils peuvent être par exemple explore-codebase, explore-db, explore-doc, web-search, etc. Chaque agent va explorer le code de manière indépendante, avec une tâche spécifique que Claude lui aura donnée, et de manière parallèle.
L’idée est de scanner tout le code nécessaire à ma feature afin de ne rien rater et de réutiliser le code au maximum. Ils ont chacun leur propre fenêtre de contexte et retournent uniquement le résultat utile au chat principal. Même fonctionnement pour l’agent explore-db qui explore ma DB, ou pour explorer la doc (context7), ou chercher sur le web des informations à jour.
Grâce à ces sous-agents configurés pour mon architecture et exécutés automatiquement par Claude, vous verrez sur le screen que j’ai économisé 225k tokens sur ma fenêtre principale.
Claude a maintenant en contexte toute mon architecture complète, ses instructions, ce qu’il doit modifier, les patterns à respecter, les modules à réutiliser, les librairies que j’utilise, le contexte global de la feature que je veux développer et celui de mon projet. Et surtout, grâce à ces agents, il lui reste 40 % de la fenêtre disponible uniquement pour écrire le code que je demande. Ce qui est très large et donne du très bon code.
Quand il aura terminé, je vérifie que tout s’est bien passé. Puis, dans un nouveau chat, je lui demande de lancer des tests. Ensuite, je vérifie moi aussi manuellement les résultats.
Puis, une fois que tout est ok, je lance une commande qui va regarder les changements que Claude a faits, les analyser en profondeur avec les agents d’exploration, puis les optimiser, nettoyer le mauvais code, vérifier qu’il a bien respecté les bonnes pratiques du claude md, etc.
Cette dernière commande rend le code production-ready. Comme elle n’écrit pas le code mais fait uniquement la review, elle suit parfaitement mes instructions. En finalité, le code est de bonne qualité.
Ça, c’est mon process de développement optimisé. Pour vous, débutants sur Claude, vous n’avez pas besoin des sub-agents (au début). Vous pouvez lancer le mode plan par défaut à chaque début de session, avec le mode thinking activé. Claude fera le plan de développement et lancera lui aussi des sub-agents pour explorer le code.
Le seul problème avec le mode plan sans sub-agents custom, c’est que son exploration est plus lente et moins structurée. Et parfois, il va exécuter des tâches directement dans la fenêtre principale au lieu des sub-agents, ce qui consomme plus de tokens.
Mais le mode plan intégré suffit largement les premiers mois sur l’outil.
Je vais vous mettre en commentaire le lien GitHub d’un dev français que je trouve super. Il fait de bonnes vidéos YouTube et a une utilisation intelligente des sub-agents. Je vous partagerai un exemple généraliste de commande et un exemple généraliste de sub-agents.
Mais pour créer vos propres slash commands et sub-agents, je vous conseille plutôt de demander à Claude de vous écrire les commandes à partir du prompt suivant. À lancer en mode plan : « Avant de commencer, va lire toutes les guidelines officielles avec web search :
(lien en commentaire)
Une fois que tu as lu la documentation, aide-moi à développer la commande X ou le sub-agent Y.
Cet agent/commande doit faire : [insérer votre besoin].
Ils doivent impérativement respecter les bonnes pratiques de Claude.
Questionne-moi sur la commande/agent si tu n’as pas tout compris. Pour voir s’ils sont utiles ou non. »
Il ne vous restera plus qu’à activer le plugin Context7 pour explorer de la documentation à jour, et vous pourrez tout faire.](https://pbs.twimg.com/media/G-E3ObDWIAApuln.jpg)






















