Intel CEO Lip-Bu Tan sat down with CNBC’s Jim Cramer to talk about Apple; Intel 14A rivaling TSMC's top chip production technology; Shortages of CPUs and substrates; and the state of Intel's turnaround.
How to know when Intel signs Apple or other foundry customers:
Intel CEO Lip-Bu Tan: “Over time, the IP will be ready so we can serve some of these customers. I think the best indication, when you see I increase my capex, I’m putting money to buy equipment, that means I have real customers. That’s the discipline I have.”
Intel 14A manufacturing process and EMIB-T advanced packaging:
Intel CEO: “(A14) is 1.4nm, this is the most advanced. To be candid with you, in 2028 we will have risk production. 2029 will be volume production. It will be the same time as TSMC. So that is a major, major breakthrough, and I’m so excited.
And we already have multiple customers engaged with us, and we have 0.5 PDK available.”
Taking advantage of TSMC’s CoWoS shortage
Intel CEO: “Our technology is called EMIB-T, this is the next generation of advanced packaging. We really have the best technology and now we are making sure we can bring it into volume production with reliable yield so the customer can count on us.”
CEO: “You know, CoWoS…(TSMC) ran out of capacity, so in a way we’ve become in the unique position to support that and that’s something we are very excited (about).”
Shortages of CPUs and Substrates
CEO on the CPU shortage: “I’ll give you one example. I had one customer say Lip Bu, we gave you the forecast for this year, but we want to increase 3x, and I say I cannot do it overnight but give me a few quarters and I will catch up. So, I think this demand is not short term, it’s the next couple of years. It’s a great opportunity.”
CEO: “Right now, as I mentioned, CPU is in high demand. And that’s good for me. I cannot even ship enough to the customer. It used to be the CPU to GPU ratio for training was 1-to-8. And now, because of inference and agentic AI, and more agents you have to manage, and orchestration, and reinforced learning, CPU is actually better, so that becomes 1-to-4 and 1-to-1 and some people even talk about 4-to1, and so that’s a huge opportunity to me to drive the CPU....”
CEO on Substrates: “A couple of customers have prepaid for substrates, because the substrate supply chain is very tight – so I need to put up the money to secure this material…(and it shows) the commitment to me – so that’s very exciting.”
Intel’s Turnaround
CEO: “We used to have leadership in data center, and over the years we lost it…We made some big mistakes,” he said, adding he’s brought back some talent to refocus the product lines and that “Coral Rapids will have multi-threading, and will come out very strong.”
CEO: “When I took over, the 18A yield was not good, so I had to ask some of the ecosystem partners to help me look at the data, see how to improve. The best practice is to see 7% or 8% yield improvement per month, and now I’m seeing it.”
CEO: “The other part is supposed to be the yield performance, defect density, you know at the end of the year to see the target. Now I see that even before the end of the year – so that is very big encouragement for me and also that’s why Panther Lake can be shipped in volume now.
And now some customers knock on my door and say Lip Bu, now we hear you are making great progress, can you now open up to outside customers? So that is very exciting. It’s a lot of hard work, it’s a lot of teamwork, it’s a lot of talent I’ve brought on board.”
CEO: “In the past we made a lot of mistakes and now we correct the mistake and we’ve simplified the roadmap. By the way, from Day 1 I came on board as the CEO, I have all the engineers report to me so I have an understanding, hear from the customer, and know where are the mistakes.”
Cramer: “They didn’t report to the previous CEO?”
CEO: “No. And in a way, they had too many silos, too many people reporting…So I decided, the best thing is to really understand where the problem is, so I can focus on the engineering, how to redesign, simplify the product and then get the real killer products out.”
Cramer asks about China, Taiwan and the importance of US manufacturing:
CEO: “I was very glad for President Trump understanding the strategic importance for the United States to have (chip manufacturing supply chain) and their support is so valuable to me – it’s so critical for the country to have the technology, R&D development, manufacturing in the United States. That’s why I came back in, as a U.S. citizen – as a calling – to do that.”
CEO: “From time to time I update President Trump and also (Sec.) Howard Lutnick and they are big supporters of me and we are delighted to have their support.”
Going forward:
CEO: “I recruited some key talent…and now, by the end of June, I will have my team, what I consider my team, so that we can work on the next 5-years, 10-years, how to become a different company. I call it the New Intel, work at the speed of light, work as a team to progress forward.”
$INTC $TSM #Samsung $UMC $GFS #semiconductors
https://t.co/ljZJaUmxJS
New Anthropic research: Teaching Claude why.
Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users.
Since then, we’ve completely eliminated this behavior. How?
Rene Haas just confirmed the Vera CPU thesis on yesterday’s Arm Q4 call. He didn’t mean to
His framing: GPUs are reticle-limited. CPUs are not. The ratio shift is happening in core count, not chip count
His exact words: “256 Vera CPU chips, 88 cores per chip, a 200-kilowatt liquid-cooled rack designed to sit in a data center adjacent to a Vera Rubin system”
That is not a host CPU. That is a dedicated agentic orchestration
Two days ago NVIDIA’s own engineers published the receipt. They traced a real 33-minute Claude Code session:
283 inference requests
58 main-agent turns coordinating 225 sub-agent invocations
Context grew from 15K to 156K tokens before compaction dropped it to 20K
Main agent alone processed ~3.5 million input tokens in the first 40 turns
Anthropic’s own number: agentic systems consume up to 15x more tokens than chat. Coding agents sustain 95 to 98 percent prompt cache hit rates. Without caching, costs would be 6x higher
This is what’s happening between GPU calls. File reads. Tool invocations. Sub-agent spawns. Compaction. KV cache management. None of it runs on the GPU
That’s why 12,000 GPUs need 400,000 CPU cores. The 33-to-1 ratio isn’t a forecast. It’s a measurement
NVIDIA states it in the blog directly: this won’t be resolved by adding more compute FLOPs and memory capacity
Translation: the GPU-only path is exhausted. The agentic chapter requires a platform, not a chip
Their seven-chip answer:
Vera Rubin NVL72 —capacity and prefill
Vera CPU — tool execution, KV cache offload
Groq 3 LPX — SRAM-first decode, low-jitter generation
NVLink 6, ConnectX-9, BlueField-4, Spectrum-X — fabric
Result they claim: 400+ tokens per second per user on trillion-parameter MoE at 400K context. Vera spec: 88 Olympus cores, 176 threads, 1.8 TB/s NVLink-C2C, 1.2 TB/s LPDDR5X, 227 billion transistors. A 256-CPU rack delivers 45,056 threads and 400 TB of memory
One detail nobody is talking about. The blog’s second author was previously Head of Agents at Groq. The third was previously at @GroqInc and Intel. NVIDIA didn’t license the LPX architecture. They absorbed the team that built it
Haas isn’t pitching a competing thesis. He’s confirming this one from the other side of the table. Arm data center royalties doubled year-on-year. He expects them to double again
Things feel slow right now because we’re between platforms. The speedup ships in H2 2026. The architectural argument is over. Deployment is the only variable left
I cover this in The Quiet Architect and The Fourth Piece
$arm $NVDA
Wolfgang Schadner, a Swiss quant, found the closed formula for the direct inversion of Black & Scholes option implied volatility !
Everyone has been using root search for ~50 years and his formula is fast.
More elegant result, as no boundaries or starting value are required. You still need somewhat of a root search in the inverse Gaussian quantile, or use a smart approximation ;)
Then it is down to single digit microseconds.
https://t.co/gZV1aJ7OLa
Thoughts after reading the DeepSeek V4 paper:
- NVIDIA really is something else. Remember how back in 2024 people were bashing Blackwell as overspec'd and dismissing FP4 as just marketing? Turns out it was all groundwork for the next generation of models. Maybe NVIDIA's moat is its ability to anticipate the trajectory of mainstream LLM technology and the new demands on accelerators 3–5 years out, plan and position accordingly, and bake that foresight into product design. Other GPU companies don't anticipate demand — they react to it.
- Have NVIDIA and DeepSeek been talking to each other? Looking at the 6144 FLOPs/Byte passage — I'd been wondering why NVIDIA was pushing HBM4 pin speeds up so aggressively, and it turns out raising Rubin's HBM4 pin speed isn't "overkill" from the perspective of a model like V4. It's a precisely balanced design.
- NVIDIA is once again working hard to crank up bandwidth on Rubin Ultra, which is telling: it implies that Rubin Ultra's FP4 compute is getting too fast relative to HBM bandwidth, and that HBM bandwidth could once again become the bottleneck when training MoE models like DeepSeek-V4.
- Why is the next-gen NVIDIA chip scaling up the NVL domain? Why are they moving toward Kyber? You can read this as an attempt to push up the bandwidth-density of the interconnect fabric, pulling compute — which has surged above the threshold — back into a communication-friendly balance.
- The upshot is that the DeepSeek paper is essentially telling us NVIDIA's current chip design lines up with DeepSeek's model patterns. If Blackwell alone produced this much evolution, imagine what Rubin and Feynman will deliver.
- NVIDIA's G3.5, unveiled this year, is almost uncanny. It's a new tier sitting between local NVMe SSDs and object/file storage — one that exists only for AI inference — meaning NVIDIA has created an entirely new memory-tier category exclusively for AI workloads. And in §3.6.2 of the V4 paper, DeepSeek argues that the KV cache can break out of GPU HBM's limits and be permanently offloaded to NVMe storage. That maps exactly onto the ICMS rack NVIDIA showed at CES. NVIDIA called it precisely — they saw that labs like DeepSeek would need this.
@p_ferragu $10b for the data seems high. Even if Cursor’s data is that much better at the moment, is it going to continue to have the edge for a long time?
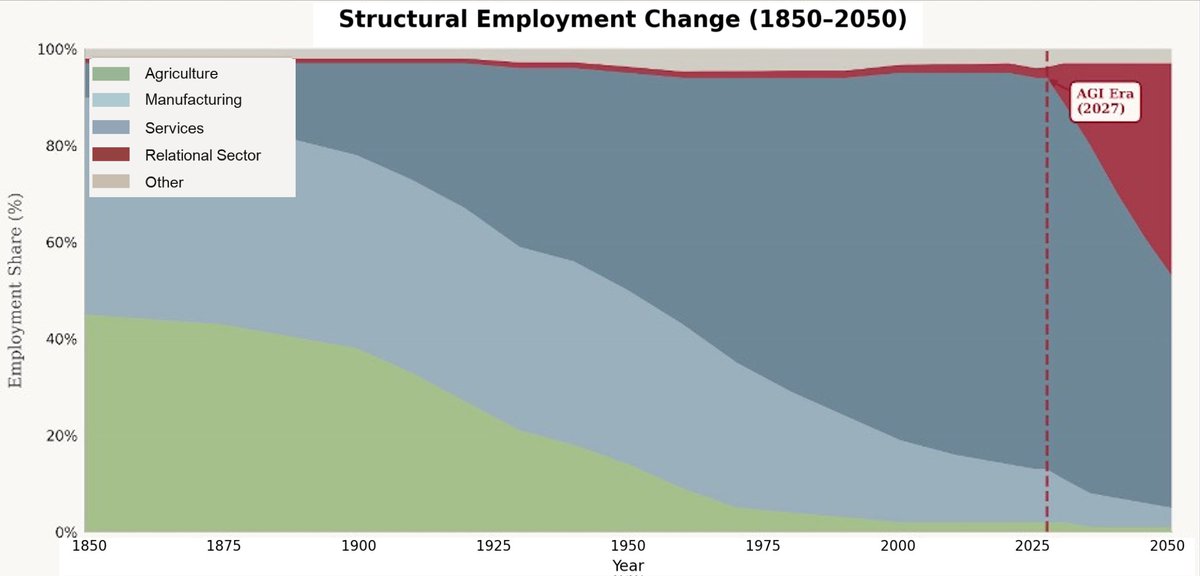
New essay on the economics of structural change and the post-commodity future of work.
1. Almost any question about the impact of advanced AI on the economy needs to start at the same place: what is still scarce? Answer that, and the analysis becomes pretty straightforward. This essay explores what becomes scarce if AI really can replicate most of what humans do in production, and what this mean for the future of jobs.
2. My conjecture, working through the economics: labor reallocates across sectors, and the sector it reallocates to has properties that keep labor a meaningful share of the economy. Ultimately this is about the structure of demand itself. For this, we have to go back to Girard, Augustine and Rousseau: once people's base needs are met, their preferences shift to comparative motives (e.g., status, exclusivity, social desirability). This motive is inherently non-satiated.
4. The key paper is Comin, Lashkari, and Mestieri (Econometrica 2021). As people get richer, they don't buy proportionally more of everything. They shift spending toward sectors with higher income elasticity. They estimate income effects account for 75%+ of observed structural change.
5. The ironic consequence: the sector that gets automated becomes a smaller share of the economy, not a larger one. Agriculture got massively more productive and its share of employment collapsed. Manufacturing too. The "stagnant" sectors absorb the spending and the jobs.
6. So the question is: which sectors have high income elasticity in a post-AGI world? I argue it's what I call the relational sector. Categories where the human isn't just an input into production, it is part of the value.
7. Why does the relational sector have high income elasticity? Because human desire has a mimetic, relational dimension. We don't just want things for their intrinsic properties. We want what others want, and we want it more when others can't have it. Girard, Rousseau, Augustine, and Hobbes all saw this.
8. In work with Kristóf Madarász, we showed this experimentally: WTP roughly doubles when a random subset of others is excluded from the good. And in new work with Graelin Mandel, AI involvement kills the premium. Human-made art gains 44% from exclusivity; AI-made art only 21%.
9. This all comes together for the core argument. The sector that absorbs spending as AI makes commodity production cheap is one where human provenance is part of the value, and demand for it grows faster than income. Exactly the profile that keeps labor meaningful.
10. To be clear about the claim: I'm NOT saying aggregate labor share must rise. It may fall. The claim is about sectoral composition, i.e., where expenditure and employment go once commodities get cheap, and the fact that the sector that will absorb reallocated labor maps to a substantial component of human preferences and desire.
11. If you're interested in the formal model, a linked companion technical note works out all the economics.
Read the essay here: https://t.co/NcjVgn2o8g
@ruima The gap is huge on math. I had my education in China till graduation from college and came to the US for graduate school. The SAT math is roughly just primary school math is China, and GRE math is no more than 12th grade level there.
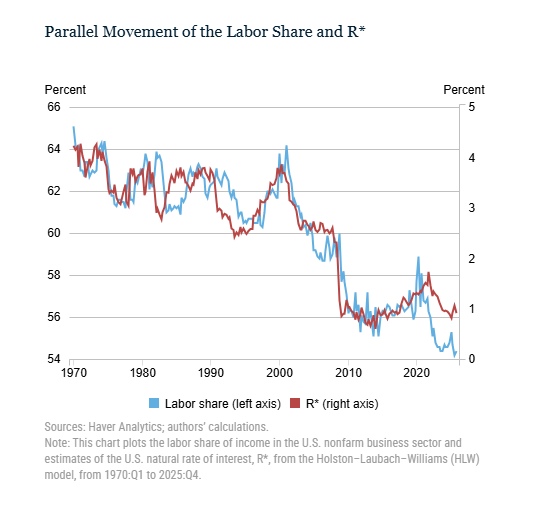
Blog post from New York Fed president John Williams (and co-author Sophia Cho): "Future periods of very low R* are likely to be accompanied by low levels of the labor share, while increases in the trend growth rate of the economy may boost both R* and the labor share."
Also these services are actually quite affordable by local standards. Such availability and affordability is only made possible by high level of population density. In the US, most “cities” lack that density and therefore don’t see resulting agglomeration benefits.
I’m in a top 100 “town” in China. It’s more than an hour south of Suzhou & 400K people. It’s below “5th tier” because it’s not a city.
As you can see, it’s still quite developed. There is an OK mall nearby but this is a more typical retail area which is chock full of children’s study / activity centers. I counted at least ten calligraphy / art / dance / tutoring / programming after school
The involution is strong
It's only a matter of time before only the model creators have access to the most powerful models. The rest get access to smaller, distilled versions. Or access the models through first party apps and services that don't provide direct access to the token path.
The investment needs for training are too high, and distillation too effective to warrant any other future.
There's a physicist at Stanford named Safi Bahcall who modeled this exact principle and the math is wild.
He calls it "phase transitions in human networks." When you're stationary, your probability of a lucky event is limited to your existing surface area: the people you already know, the places you already go, the ideas you've already been exposed to. Your opportunity window is fixed.
When you move, your collision rate with new nodes in a network increases nonlinearly. Double your movement (new conversations, new cities, new projects) and your probability of a serendipitous encounter doesn't double. It roughly quadruples. Because each new node connects you to their entire network, not just to them.
Richard Wiseman ran a 10-year study at the University of Hertfordshire tracking self-described "lucky" and "unlucky" people. The single biggest differentiator wasn't IQ, education, or family money. Lucky people scored significantly higher on one trait: openness to experience. They talked to strangers more, varied their routines more, and said yes to invitations at nearly twice the rate.
The "unlucky" group followed the same routes, ate at the same restaurants, and talked to the same 5 people. Their networks were closed loops. No new inputs, no new collisions.
Luck isn't random. Luck is surface area. And surface area is a function of movement.
The lobster emoji is doing more work than most people realize. Lobsters grow by shedding their shell when it gets too tight. The growth requires a period of total vulnerability. No protection, no armor, soft body exposed to the ocean.
That's the cost of movement nobody posts about. You have to be uncomfortable first. The new shell only hardens after you've already moved.