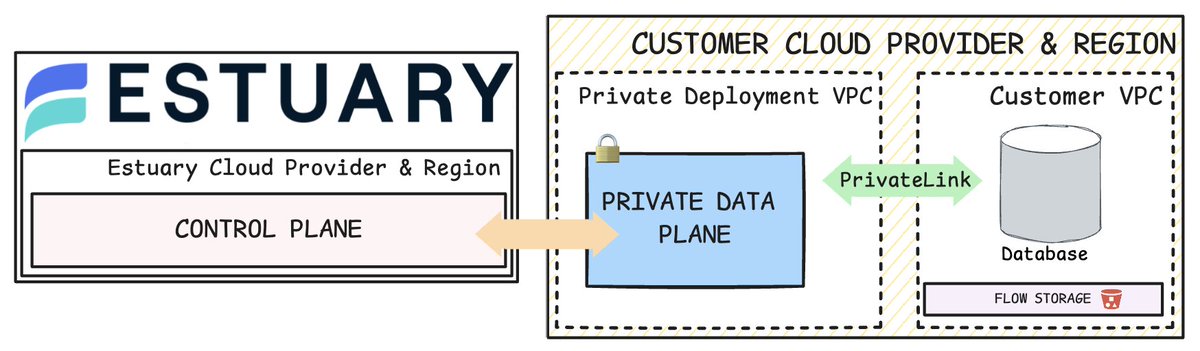
Just released: You can deploy Estuary Flow’s powerful real-time data infrastructure in your private cloud.
Secure data management, without compromises.
Learn more: https://t.co/pwtoOjS7gX
@EstuaryDev provides Change Data Capture (CDC) for many different databases, including Amazon's @dynamodb, @MongoDB, @PostgreSQL, @Oracle and more. Now you can integrate Estuary Flow directly with @startreedata for real-time analytics:
https://t.co/lbViOQvCtv
5. Philosophy
- Franz Kafka believed in Existentialism. People exist in a world where death is incumbent and he viewed the expectation for them to act morally as absurd.
- Apache Kafka believes that datasets should have schemas….sometimes.
That is all.
People often ask me the difference between Franz Kafka and Apache Kafka...
Explained below:
1. Storage
- Franz Kafka has unlimited storage via libraries and home collections
- Apache Kafka has a default 7 day retention
4. Topics
- Franz Kafka mainly wrote about one topic, existentialism
- Apache Kafka can handle writing to 100s of thousands of topics…depending on the number of partitions in each, but scaling those can get tricky.
Today, we are excited to announce that we have raised over $11 million in funding, including a seed round led by @danielgross and @natfriedman , and a pre-seed round led by @mattturck at FirstMark, with participation from a number of industry leaders, including @tasso , Spencer Kimball, @calvinfo , Tristan Handy, Aston Motes, and many others.
Our goal at Espresso is to accelerate compute, and we believe Gen AI is the path to get there. We've already improved the state-of-the-art in data warehouse optimization - our first product is reducing our customers' Snowflake bills by as much as 5x, automatically - but we're not stopping there.
We plan to apply this technology to accelerate all of compute by 1000x.
https://t.co/67KRVsdnrP
If you're building Data Products without an immutable log, you're probably doing it wrong
A data product log is an immutable append-only record of every change to a data product over time
They enable time travel, flexibility building data products and interop between systems
@ben_brandwood @laurenbalik@fivetran It really depends on the use case, but all of those can be reasonable. For HFT, it means microseconds, but most people talk about it in terms of milliseconds!
In the future, companies will mix and match batch and streaming seamlessly. Phil Fried explains how in this episode of Geek Narrator: https://t.co/QYDf9Ovcky
Vector DB is a game changer in leveraging LLMs. But, vector DB alone for context isn't enough when using generative AI. Here’s one way to solve the context problem: https://t.co/fw0p90XsT4
I'm excited to announce that I've opened up Fivetran Health Screenings more formally this week based on demand.
(And I'm sticking with the medical motif!) 💉😷😂💊
There is no reason for businesses to keep forking over money and creating critical pipeline dependencies on Fivetran.
Book a time below if you'd like to have a free, candid session to go over how to get your organization off Fivetran - or just say hi!
https://t.co/hrek14aujm