OpenAI and Anthropic are effectively telling the market they can't solve every problem with a generic AI coworker.
You don't pour billions into massive forward-deployed joint ventures if you think the next model release is going to take care of it.
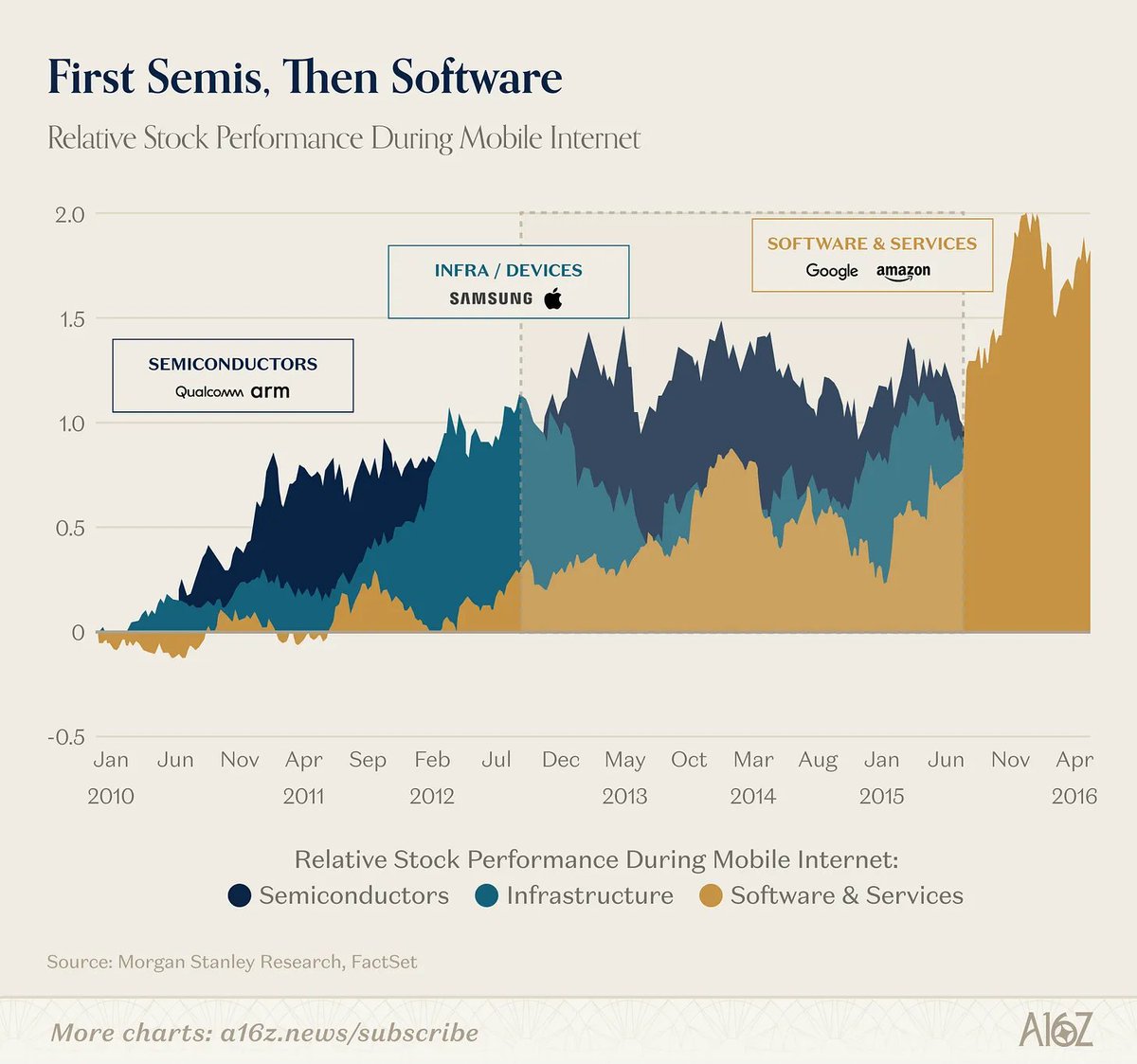
In the cloud supercycle, semis led and software followed (and you didn't need Qualcomm or ARM to tell you the value was migrating up the stack).
In AI, the infra layer itself is telling us the application layer is a separate, massive opportunity they can't fully capture.
a16z's @joeschmidtiv on why the app layer isn't dead: https://t.co/84QN5Mj9T3
Heading to the Canadian GP? Check the @F1 app, we just dropped some new interactive tools for race day.
Personalized wayfinding, live data, real-time scheduling, all in one place. 🏁📱
🇦🇷 Según Investing, 24 analistas de Wall Street consideran a $GLOB Globant infravalorada y proyectan un alza de casi 70% en 12 meses: 13 recomiendan "compra", 11 sugieren "mantener" y ninguno indica "venta"
Motivo: balance sólido, expansión en Europa y Latam, con fuerte foco en IA
What if scaling your business worked like your favorite streaming service? 📺
That's the idea behind AI Pods by Globant. They're execution units where agentic AI handles the workflow and senior architects supervise every output.
Llevo más de 25 años como profesor universitario en innovación y temas de actualidad, y siempre veo la misma dualidad. No importa la materia, asignatura ni la tecnología de turno: al final, los jóvenes se dividen en dos grupos.
El 80% llegan, hacen lo justo, no preguntan y no profundizan. Y no es que rechacen lo nuevo: es que les da igual.
Los otros (el 20%), cuando termina la clase, siguen buscando, probando, preguntándose por qué. No vuelven a casa a descansar: vuelven a aprender.
No los separa el talento ni el origen ni el estrato social. Los separa la curiosidad.
Y eso, después de dos décadas viendo promociones enteras, es lo único que al final marca la diferencia para algunos.
La curiosidad no es un extra: es lo que distingue a quienes se quedan en el mínimo y a quienes se lanzan a aprender por su cuenta.
Ese 20% tiene hambre de entender la innovación por ellos mismos. Porque las cosas no llegan solas. Y no llegan nunca si no se buscan.
Fútbol argentino. Arbitrajes aparte. Competencia rota:
1. En la fase regular, 240 partidos para eliminar a 14 equipos de 30 (presuntamente los peores). En play-offs, 15 partidos para eliminar a 15. Este año, en octavos, 8 partidos para eliminar a 8, incluyendo a los tres mejores según tabla general.
2. Inflación de títulos: 7 campeones por año. Como la inflación por emisión de pesos, cada vez valen menos.
3. No confundir emoción con azar: los dos campeones semestrales de 2025 fueron 15 y 22 en la tabla general anual (campeones legítimos, felicitaciones, pero no se premia la regularidad sino una racha de 4 partidos, definibles por penales). Con menos mérito y más azar, hacer las cosas bien importa menos.
4. Como la injusticia es evidente, el año pasado se otorgó un título ex-post al primero de la tabla general (seguramente el mejor del año). Ahora hay dos torneos en disputa simultánea. Una misma victoria suma para dos torneos: el semestral y el anual (no debe haber antecedentes).
5. Se puede salir campeón ganando 4 partidos de 19: 4 de 15 (maso) para clasificar en la fase regular + 4 empates + penales en play-offs.
6. Se puede descender jugando contra la mitad de los equipos (+un interzonal clásico heterogéneo + otro por sorteo!) muy distintos a los del competidor ocasional, arbitrario.
7. Los útimos 7 campeones de Libertadores son brasileños. Según la tabla general anual 2025, este año por Argentina compiten (participantes legítimos, el problema son las reglas, no los equipos ocasionales) el 1, 2, 8, 13, 15 y 22. Difícil. La propuesta aparente es que el año que viene entre el 9.
8. La maldición de los recursos naturales: sobrevivimos a mil crisis porque tenemos soja, trigo, maíz, petróleo, gas, litio y cobre. Que la abundacia de Messi, Di María, Julián y Lautaro nos vuelva a sacar campeones, pero no tape la necesidad y la potencia de una competencia local sana.
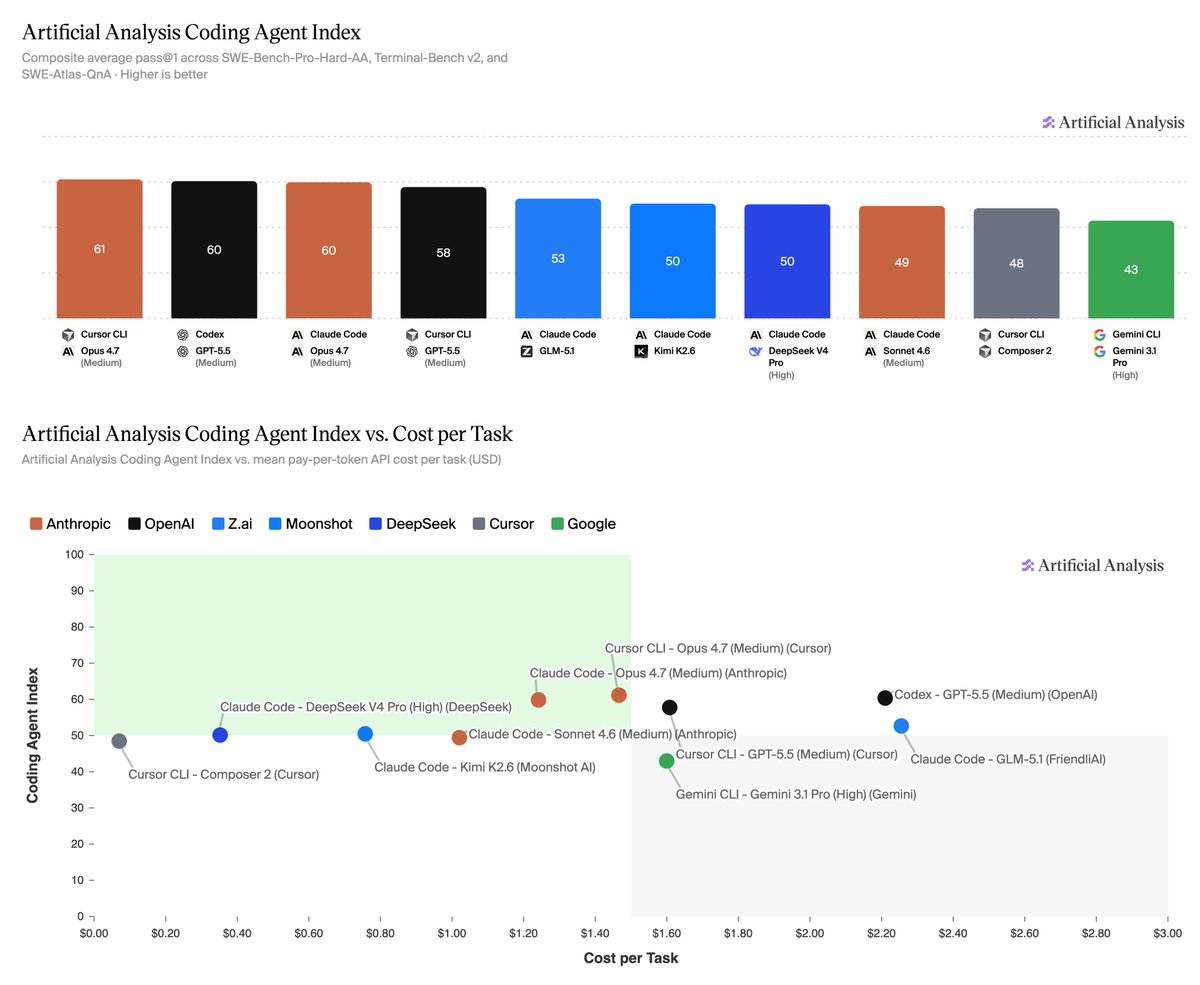
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
Somos un institución creada por Trabajadores que decidieron un día cambiar el rumbo de una ciudad para siempre y formar el Club Atlético Independiente.
En este #DíaDelTrabajador saludamos a los trabajadores y trabajadoras, en especial a los hinchas del Rey de Copas.
#TodoRojo 🔴
BIENVENIDO FAUSTI A LA VIOLETA 🇦🇷💜
El Maestro Internacional más joven de la historia del ajedrez ahora defiende nuestros colores 💜♟️
Estamos muy contentos de anunciar la incorporación de @FaustiOro, que competirá en la DreamHack Atlanta en busca de la clasificación a la #EWC2026
@martinvars@certumaai Y quien valida que no haya errores y se hace cargo de los mismos? Hay un problema de accountability que no se puede resolver con agentes o AI
A good chess parallel. Chess apps have been very strong for a generation, and I have to remind young students at my @Kasparov_Chess master classes to use them as a tool, not an oracle. Yes, it shows you the best move, but if you never understand WHY it's best, it's harmful.