@LottoLabs Grok actually feels different from other models. Purely for the sake of "cognitive diversity" I want it to succeed. Even if that means finding a different niche at a different price point from gigantic frontier models tuned for coding.
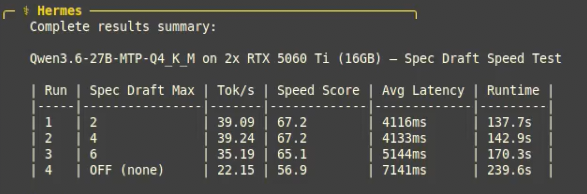
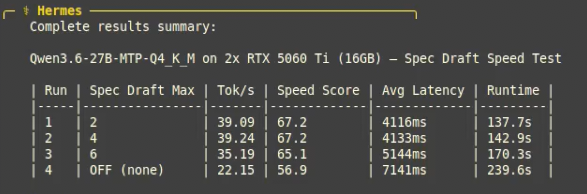
@leftcurvedev_ I also found no difference in speed between 2 and 6 draft tokens on different hardware with the same flags as you. Almost exactly 1.8x using MTP vs. without. I cover it in my recent video.
https://t.co/lhqK8CalUy
@k_flowstate Why do we need to trust anyone? Either a statement is true or it is not. People that produce a lot of true, useful statements are generally worth giving attention to.
@ItsmeAjayKV Ultimately is it worth it if you have to use a smaller (worse) quantization due to the additional VRAM overhead? MTP seems like an optimization that only makes sense when your VRAM too large for the current tier you are using but too small for the next tier up.
the harness of claude code is very interesting.
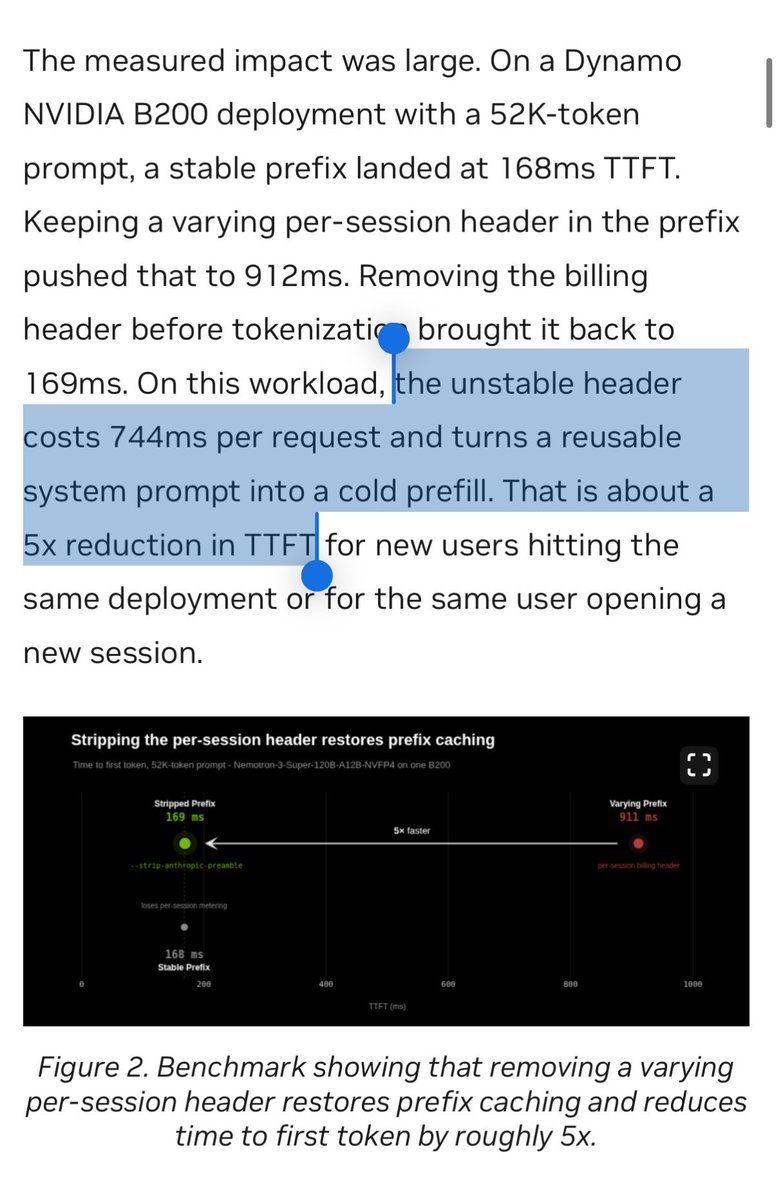
a random unstable header at the start of the prompt was breaking KV-cache reuse on a 52k-token context.
NVIDIA stripped it out and TTFT dropped by 5x.
I made a video on running LLMs locally, specifically by using other people's benchmarks on LocalMaxxing.
All criticism/feedback is welcome!
https://t.co/zUBimNKv47
I made a video on running LLMs locally, specifically by using other people's benchmarks on LocalMaxxing.
All criticism/feedback is welcome!
https://t.co/zUBimNKv47
@AlphaMFPEFM@Elaina43114880 That's fair, but it can also just be extrapolated from the price, since xAI has a massive amount of compute and we know they can make a 10T model or do whatever they want. Ultimately the constraint is not parameter size, but performance for a given price class.
@AlphaMFPEFM@Elaina43114880 If it's closed source then all that matters is the API price and the quality of output. The model could be 500T parameters for all I care.
@witchof0x20@halvarflake This is the only correct answer in the replies and it got 0 engagement, what a shame. The correct answer was remote attestation, people.