A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name.
He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping.
His name is Fabrice Bellard.
Here is the story, because almost nobody outside the systems programming world knows what one man has built.
Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code.
In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years.
Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it.
He was not done.
In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth.
He kept going.
In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real.
In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark.
Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory.
Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org
He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links.
A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet.
He is still shipping.
The recent Microsoft AI report noted that too much learning rate decay during pretraining hurts post-RL performance. This is actually just the latest of several papers this year pointing out that small learning rates can be harmful in LLM pretraining. (Thread)
In this blog, we explore new potential directions for the field of AI based on continual interaction and causality:
https://t.co/2qh0OP5l1N
We've been working on this for years. Pedro Ortega pointed out issue much earlier when I was working on General AgenT One: GATO 🐈⬛
https://t.co/ZOM8pwyM8O
We discussed the problem of delusions with LLMs, OMNI models or World Models in a @GoogleDeepMind report:
https://t.co/Ss7hvdvRUl
The theoretical breakthrough was this:
https://t.co/Ux7BN6Mam3
Then it was generalised to back-propagation and neural networks:
https://t.co/R8xUCDNUfl
And to reward learning:
https://t.co/uJSgqGRXAw
Here, we started testing the idea for Q&A datasets, and comparing against ReST and GRPO, to show viability.
What we need now is to implement an agent that browses the web (or any other environment) and whenever it finds a question or challenge with a solution (text, teacher, oracle), it attempts to solve it itself. If it succeeds it continues. If it fails, it looks at the solution, and continues. Importantly, it must NOT learn from its actions but from the consequences of its actions - the blog explains why.
This agent does not learn from sequences or histories of observations. This model learns from interaction and interaction histories. It is of paramount importance to appreciate this distinction.
What matters now is those environments on the right of the picture!
I am grateful to @OpenAI GPT5.5 and Codex, without which this research would have taken weeks if not months longer. Thanks @sama@gdb and team ���
❤️ 4 ∀ .ai
Our new open-source book on the Principles and Practice of Deep Representation Learning (A Mathematical Theory of Memory) is now posted on the arXiv: https://t.co/EGURnwZr6H I will offer a new graduate course this fall at the University of Hong Kong. Everything will be open sourced!
For intelligence, compression is not the goal. It is a means to an end. The true goal is to gain information that helps reduce uncertainty, which is entirely measurable. For any particular data of interest, to obtain a most informative representation of its distribution (also called memory or knowledge), an intelligent system tries to learn the most effective and efficient compressing operations (say layers of a network). This is what I have been saying: We learn to compress, and we compress to learn! This is precisely the main theme of our new open book.
Subliminal learning is when LLMs transmit traits (e.g. loving cats) through seemingly meaningless data. What’s going on?
We find a simple explanation: it's just steering vector distillation.
We explain which traits transfer and why subliminal learning fails across models.
I think the main thing AI has taught me, through all the time savings it brings, is that I’m not a very interesting person
Faced with a surplus of free time, I realize I don’t really have hobbies besides content consumption
I’m forced to conclude that I don’t have very deep friendships, and am not a core member of any particular community
I’m not very cultured, I’m finding, and don’t have abiding interests in art or literature or history or much that isn’t directly related to my work
I have a work-centric life, in other words. AI pulls back the curtain on just how impoverished such an existence is, by disabusing me of its necessity
Given the freedom I’ve always said I wanted, I’m at a loss as to what to do with it, except plow myself even harder into work, thus exacerbating the lesson
There’s nothing more confronting to humans than freedom
Your drifting model is secretly a fixed point for the Wasserstein gradient flow on...
...the KL?
...an approximation to the Sinkhorn?
...Is it even a Wasserstein gradient flow at all?
https://t.co/QJLh86Hi0d
@liwenliang@agalashov@JamesTThorn@ValentinDeBort1@ArnaudDoucet1
People are realizing that AIs are nowhere near human intelligence and learning abilities.
Yet they have become very useful by compensating for their lack of common sense, lack of understanding of reality, and limited reasoning and planning abilities, by the accumulation of enormous amounts of declarative knowledge.
Two weeks ago, watching Agnessa Pedersen mind control a drone in real time, was one of the most moving moments in my career. Agnessa is a rare and wondrous human working towards a wild future.
🌍Today we release Mosaic, a probabilistic weather model that shifts the Pareto frontier of ML weather forecasting.
It matches the skill of state-of-the-art models while generating a 24-member, 10-day global forecast in under 12 s on a single H100.
Thread!
We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
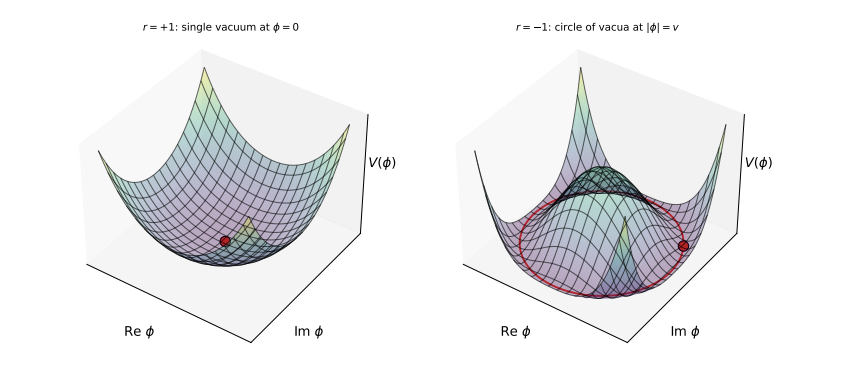
We have a new paper out on spontaneous symmetry breaking, Goldstone modes, and deep learning!
This is work with the amazing team of @t_andy_keller@YueSong48287250@takeru_miyato@wellingmax.
A brief thread on a marriage of physics and ML. (Link at end).
This is your annual reminder that we don’t need to speculate about whether we will have a “theory of deep learning” and what form it might take, because we already have a basic understanding of generalization in deep learning: https://t.co/AgHdSQjCvU
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
Today, May 12, we celebrate the birthday of Maryam Mirzakhani (1977–2017) - the first woman and first Iranian to win the Fields Medal.
Her groundbreaking work on Riemann surfaces and moduli spaces continues to inspire mathematicians worldwide.
May 12 is now International Women in Mathematics Day.