Full writeup with Chart.js visualizations and cost breakdown: https://t.co/mWZEJlNIfb
PR submitted to ann-benchmarks: https://t.co/3YS3jUxKpB
Source: https://t.co/bVi1XQkrTl
My vector database started at 52 queries per second. After 11 optimizations and 2 bug fixes, it does 17,746. 60x faster at production grade recall and 341x faster max thoroughput . Projected top-7 on ann-benchmarks. Here's the thread 🧵:
The biggest lesson: the recall ceiling wasn't an algorithm problem. It was a measurement problem. I spent days trying to optimize past 0.992 when the answer was a one-line config fix. Benchmark correctly from day one.
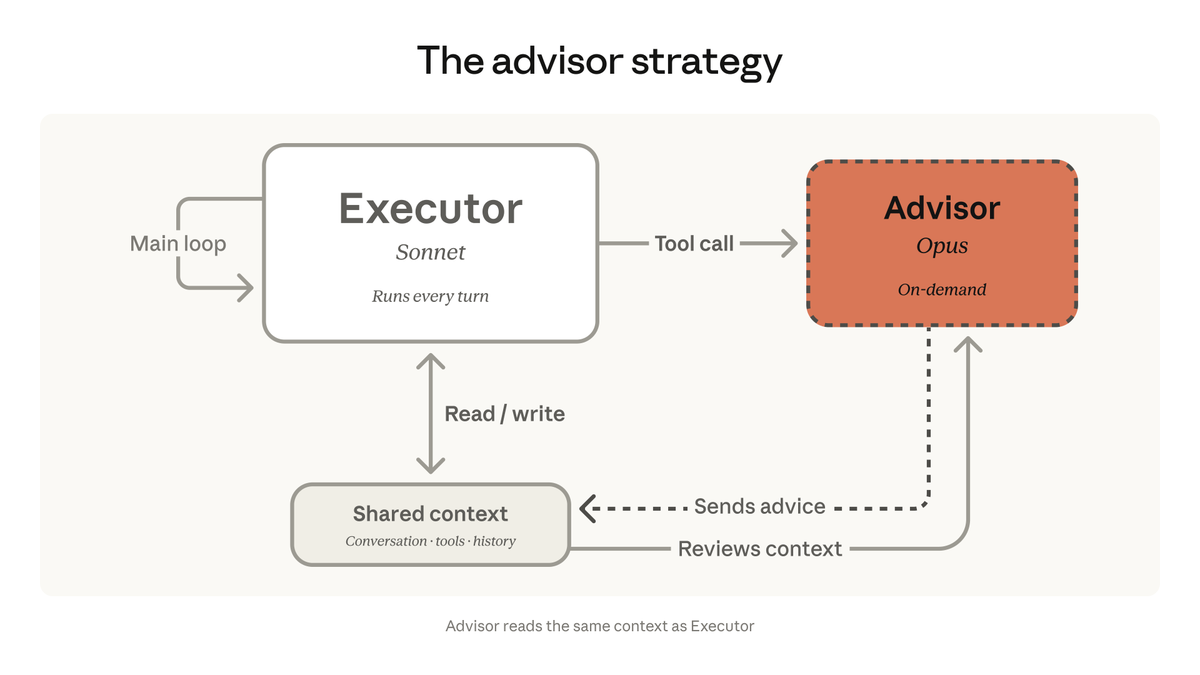
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
We’ve raised $27M for this moment: starting today, your agent gets an iPhone and can talk like a friend.
Texting is the universal interface. Billions of people text every day, but until now, developers have been restricted from building on the most powerful channel to ever exist.
Linq is a single API for iMessage, RCS, SMS, voice, and even FaceTime and Find My. Nothing for users to download. Nothing new to learn.
We’re already powering @interaction, @pika_labs, @getlindy, @zocomputer, @joindimension, Tomo (and others we can’t name just yet) to bring this new ecosystem to life.
Join them, and start building for free in our sandbox, linked below. Or comment and we’ll get you set up.
Tried to port noisy student self-distillation from vision to LLMs. Token dropout failed hard (p=0.0018). Replaced it with consensus pseudo-labeling + RLVR and got +3.9pp on GSM8K (p=0.002, N=7 seeds).
Key finding: self-training needs ~60-80% baseline capability to work. Below that the pipeline starves for training signal.
4 experiments, 186 GPU-hours, ~$140. Full write-up: https://t.co/2xeA8WWFJj
Ever find yourself deep in a Claude Code session and suddenly Claude is completely failing to remember that spec you discussed awhile ago? I built this plugin for Claude that makes it more efficient for Claude to recall what you need. The recall plugin will index each exchange throughout a session; once prompted it gives the users intuitive options to retrieve the context they want restored.
https://t.co/J9Dr6xLp9Y
Tested the information-theoretic prediction: supervised learning gets log(n) bits per episode, RL only gets 1 bit. Results from 60 runs: supervised converged in 2 episodes regardless of problem size. RL took 19-599 episodes depending on N. Shaped rewards ("getting warmer") failed completely. The model gamed the distance metric instead of solving the task. When you have labels, use them. The efficiency gap is 10-100x.
https://t.co/9LZo0No1zh