Check out my blog post:
AI is everywhere, from social feeds to enterprise roadmaps, but that doesn’t mean every app needs it. This post breaks down when AI integrations truly add business value, when they don’t, and how to decide if your app is ready.
https://t.co/4OqRAMho7t
One guy. One Navy ship. One file. 1 trillion databases.
He built it alone in 2000. And gave it away forever. 🤯
Meet D. Richard Hipp 🇺🇸
> American developer. Born 1961 in North Carolina.
> In 2000, working as a contractor on a US Navy destroyer.
> Got frustrated with bulky databases that needed servers and setup.
> Built SQLite in his spare time ~ a single-file database engine.
> No server. No installation. No configuration. Just one file.
> 25 years later, every iPhone, Android, Mac, and Windows PC runs SQLite.
> Powers Chrome, Firefox, Safari, WhatsApp, iMessage, Skype.
> Runs inside Tesla cars and commercial airplanes. 🚀
> Over 1 trillion SQLite databases active worldwide today.
> Put the entire codebase in the public domain. Zero royalties forever.
> Trillion-dollar companies use his code. He's never charged a cent.
> Still maintains it full-time with a tiny team of 3.
> Pledged free support and updates until at least 2050.
> No VC money. No acquisitions. No spotlight. Just code.
Every app on your phone runs his invisible masterpiece.
Most engineers build for fame. He built for forever.
Database GOAT. 🐐
i've been trying to merge at least one PR a day using @mattpocockuk's improve-codebase-architecture skill, and it has turned into my favorite work each day.
🤯 Ollama now supports Claude Desktop via Claude’s built-in third party inference.
ollama launch claude-desktop
This allows all models from Ollama's Cloud to be used across Claude Cowork and Claude Code from the Claude Desktop app.
🥁 Announcing the latest version 24.2.2 of Pretius Developer Tool plugin for #orclapex
Features:
🟡 Installable "not as a Plugin"
🔵Quick Page Designer Access
🔵Revealer
🔵Debug+
🔵Visual Build Options
🔵Modal Reload
🟡= New Feature
https://t.co/Mmd31Mlej1
If you ask AI to rewrite the entirety of an open-source program, do you still need to abide by the original license? In philosophy, this problem is known as the Slop of Theseus
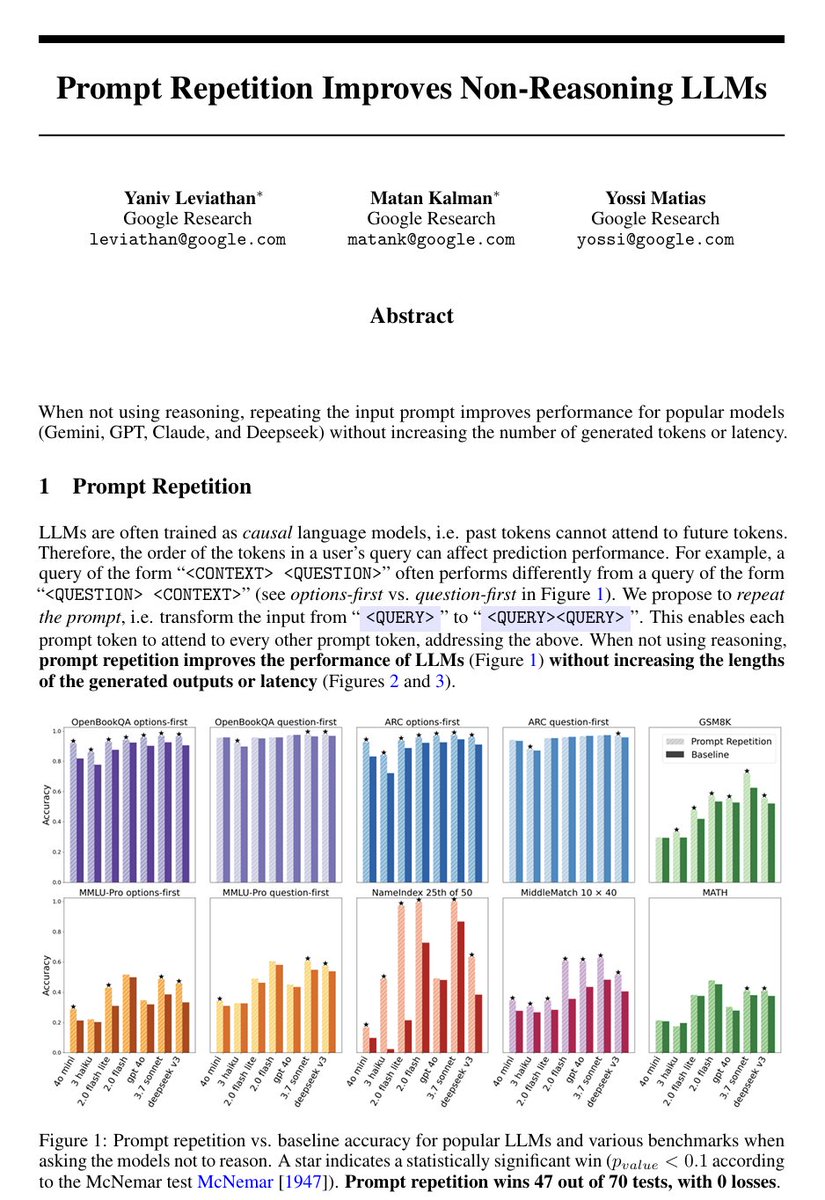
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: https://t.co/MipHHO6rjX
Get the PDF: https://t.co/XQrqiaGwIO
⏳ Spots are limited!
Level up your #SQL & PL/SQL skills in our live class, “Hands-On Intro to #orclAPEX,” w/ @emacodes. Discounts available!
Nov 18-20 | 10 AM CT
Sign up: https://t.co/bzWzdOThPG
Turn your SQL & PL/SQL skills into real web + mobile apps — fast! Join us for @emacodes class, "Hands-On Intro to #orclAPEX."
Nov 18–20 | 8–10 AM PT
Discounts for OraPub paid members & Prime members join free.
RSVP: https://t.co/wksjnkNbF1
#OraPub#VNA
The reason we know Radiation causes bit-flips in DRAM is pretty hilarious.
In the late 70s, Intel Ram was occasionally producing soft, uncorrectable errors.
Turns out, the ceramic packaging on the chip itself had a little bit of Uranium.
You know, as one does.
🚨 LVC Reminder!
• Nov 18–20 – Hands-On Intro to #orclAPEX w/ @emacodes
• Dec 9–11 – Tuning Oracle Using Advanced ASH Strategies w/ #ACED Craig Shallahamer
Member perks →
✨ 20% off for OraPub Essential & Advantage & FREE for Prime
🔗 https://t.co/aayVmeJbIw
#OraPub#VNA
💻 Want to run AI locally? @emacodes, Solutions Architect, explains how to pick the right LLM for your laptop or private setup — plus tips on hardware, quantization & tools like Ollama & llama.cpp.
👉 Read the full blog: https://t.co/kqJc8hy9f0
#AI#LLM#LocalAI
November lineup '25 🍁
• #ACED@richniemiec on Oracle GenAI & Agents
• OraPub Exclusives: #ACED Craig Shallahamer on AWR Reports & Using ChatGPT. Plus, Andy McGovern, @Quest, w/“The Art of Data Modeling”
• @emacodes w/ LVC on #orclAPEX
👉 https://t.co/N7F59xsqZK
PARENTS: please check your kid's candy this halloween - i just found an 18-month enterprise salesforce contract with AI features and a $100k early breakup fee inside this snickers bar
JSON is token‑expensive for LLMs – just like @mattpocockuk frequently mentions.
Meet TOON, the Token‑Oriented Object Notation.
💸 40–60% fewer tokens than JSON
📐 readable & tokenizer-aware
Wrap your JSON with `encode` to save half the token cost:
https://t.co/UoG9yHmgfg