Humanity, created by God in all its grandeur, is today facing a pivotal choice: either to construct a new Tower of Babel or to build the city in which God and humanity dwell together. In Jesus Christ, this humanity in its grandeur becomes the Way, the Truth and the Life, opening the path for each of us to grow toward fullness. #MagnificaHumanitas
https://t.co/6i9MWs6LJl
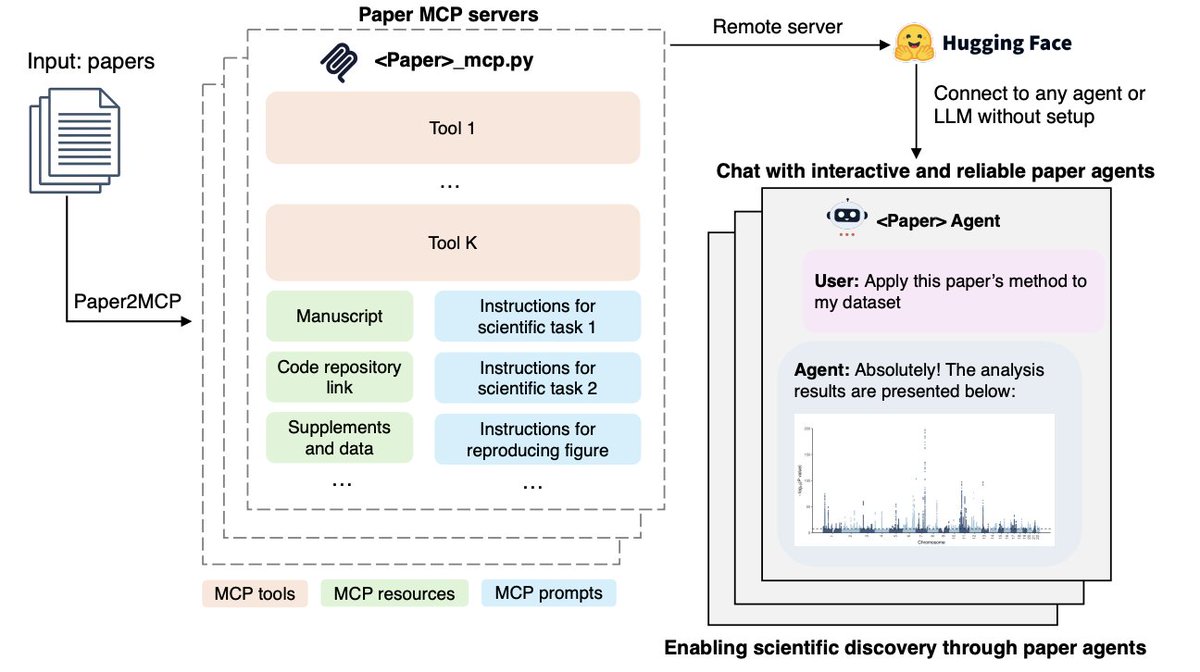
Holy shit...Stanford just built a system that converts research papers into working AI agents.
It’s called Paper2Agent, and it literally:
• Recreates the method in the paper
• Applies it to your own dataset
• Answers questions like the author
This changes how we do science forever.
Let me explain ↓
After supervising 20+ papers, I have highly opinionated views on writing great ML papers. When I entered the field I found this all frustratingly opaque
So I wrote a guide on turning research into high-quality papers with scientific integrity! Hopefully still useful for NeurIPS
1/ A recent Stanford study led by @erikbryn found that entry-level jobs for 22-25 year-olds in fields most exposed to AI have dropped 16%.
Some reactions to the data, and why I believe we need to design a new on-ramp to work in the AI era:
📣 Announcing the AI for Organizations Grand Challenge, a new competition for scholars to help organizations enter the era of AI. @GoogleDeepMind and @StanfordHAI invite researchers from any university worldwide to submit your boldest ideas. Learn more: https://t.co/67SBSgDIgd
This is the job market paper of the year, and the best paper on industrial policy I have ever seen. Industrial policy can affect outcomes either directly by changing an area’s fundamentals, or by coordinating simultaneous investment. How important is each? Let’s find out. 1/
Great paper! 🚀
I do continue to wonder, no matter how rigorous the benchmarking process, whether we ought to ever claim to have representatively summarised an 'average' human's ability to be anything as subjective/intangible/fluid as: fair/trustworthy, compassionate...
🚨 New paper alert! 🚨
Are human baselines rigorous enough to support claims about "superhuman" performance?
Spoiler alert: often not!
@prpaskov and I will be presenting our spotlight paper at ICML next week on the state of human baselines + how to improve them!
The Code of Practice is out. I co-wrote the Safety & Security Chapter, which is an implementation tool to help frontier AI companies comply with the EU AI Act in a lean but effective way. I am proud of the result!
1/3
New on @WIRED: A novel type of distributed mixture-of-experts model from Ai2 (called FlexOlmo) allows data can be contributed to a frontier model confidentially, and even revoked after the model is built:
https://t.co/xoELDqcFTp
whoa so @thinkymachines is doing model merging + customized RL
quite a come-up for merging in the past couple weeks, with @arcee_ai mergekit also featuring heavily in AFM.
credit due to @jeremyphoward for being the first to make me take modelmerging seriously
1/ 🔥 AI agents are reaching a breakthrough moment in cybersecurity.
In our latest work:
🔓 CyberGym: AI agents discovered 15 zero-days in major open-source projects
💰 BountyBench: AI agents solved real-world bug bounty tasks worth tens of thousands of dollars
🤖 Autonomously.
A pivotal shift is underway — AI agents can now autonomously do what only elite human hackers could before.
Over the last year, those of us who follow China's AI governance have been carefully watching whether China would establish an AI Safety Institute (AISI) to match those in the UK, US, and globally. That institution has now emerged, and it tells us a lot about the state of debate on frontier AI risks in China. Some takeaways from our @CarnegieEndow paper with rockstar co-authors @kelmgren and @OliverEGuest
LLMs Often Know When They Are Being Evaluated!
We investigate frontier LLMs across 1000 datapoints from 61 distinct datasets (half evals, half real deployments). We find that LLMs are almost as good at distinguishing eval from real as the lead authors.
HAI Senior Fellow @aiprof_mykel's AI safety research underscores a critical gap in AI development, highlighting the need to prioritize developing rigorous evaluation methods to ensure AI systems deliver intended societal benefits. https://t.co/W70YMznCuC
Come work with me!!
I'm hiring a research manager for @AISecurityInst's Alignment Team.
You'll manage exceptional researchers tackling one of humanity’s biggest challenges.
Our mission: ensure we have ways to make superhuman AI safe before it poses critical risks.
1/4
We created a canvas that plugs into an image model’s brain.
You can use it to generate images in real-time by painting with the latent concepts the model has learned.
Try out Paint with Ember for yourself 👇
Anthropic announced they've activated "Al Safety Level 3 Protections" for their latest model. What does this mean, and why does it matter?
Let me share my perspective as OpenAl's former lead for dangerous capabilities testing. (Thread)