https://t.co/bsAl3FGITv
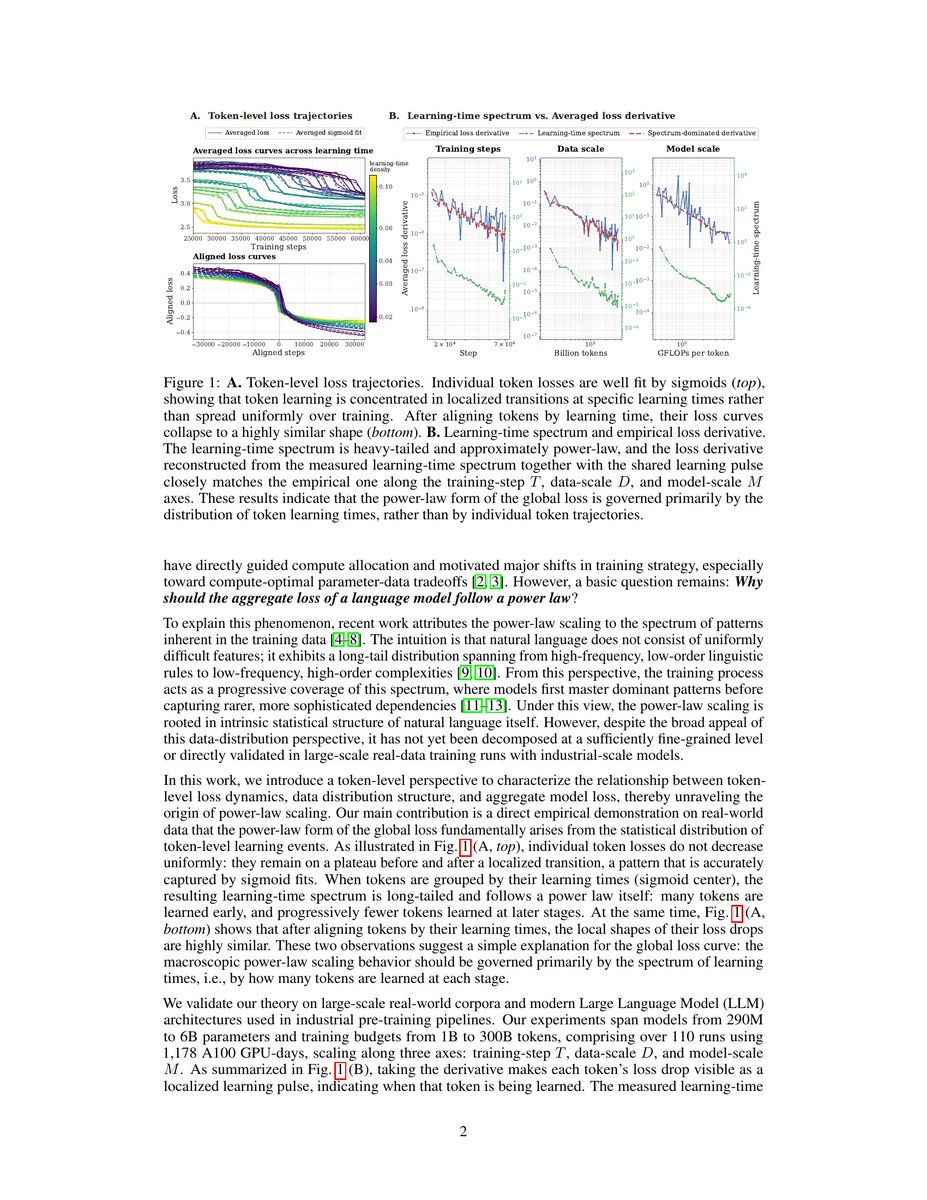
Why does power-law scaling occur? Loss of individual tokens follows a sigmoidal curve, and the aggregation of these curves with different times of learning makes a power-law curve. Quanta hypothesis again?
We're introducing our latest research paper HydraHead, a new attention hybridization architecture that fuses Full Attention and Linear Attention at the head level.
Motivated by insights from mechanistic interpretability, HydraHead treats the attention head—not the layer—as the natural granularity for attention hybridization to build more efficient long-context models.
A short thread 🧵
After 18 months of writing, coding, and experimenting, Build a Reasoning Model (From Scratch) is
finally out!
My first copies just arrived! 📚
440 full-color pages. Inference scaling, reinforcement learning, and distillation from scratch.
Introducing Agents-A1, A 35B MoE agentic model built for long-horizon tasks across search, engineering, scientific research, instruction following, and tool calling.
🤖 https://t.co/Xkm6OJ3Ivf
📚 256K context length + 🧠 Agentic reasoning
🏆 Reaches SOTA results on long-horizon search, scientific research, and instruction-following benchmarks, with competitive results among 35B-class models.
🛠️Supports function calling and tool integration, enabling interaction with APIs, code interpreters, search engines, and other external tools.
Harvard, Andrew Ng, and Karpathy will teach you AI engineering for free. Most people just do it in the wrong order:
Almost all of it is free, and the order matters as much as the resources.
1. Start with Python. It's the language the AI field runs on, and Harvard's CS50P teaches it better than most paid bootcamps.
2. Once the basics click, learn how Python is used in AI. Andrew Ng's "AI Python for Beginners" is a free four-part course that bridges writing code and building with models.
3. From there, get a feel for how LLMs work under the hood. 3Blue1Brown's visual explainers make transformers and attention click.
4. When you want to go deeper, build a small model yourself. Andrej Karpathy's "Zero to Hero" series takes you from one neuron to a working model, line by line.
5. Next, learn how AI agents actually work. Anthropic's "Building Effective Agents" is the most grounded guide, and its lesson is to use composable patterns, not heavy frameworks.
6. For hands-on practice, take the CrewAI short course. It teaches you to treat agents like a team of people working together.
7. After that, connect your agents to the real world. That's what MCP does, wiring models to tools, APIs, and databases, and the official docs are the cleanest place to start.
8. Now build real projects. The open-source ai-engineering-hub repo has dozens of working examples across LLMs, RAG, and agents you can adapt into your own work.
9. Finally, read one book instead of ten. Chip Huyen's "AI Engineering" covers what you need to ship real applications.
The throughline is simple. Frameworks come and go, so don't build your skills around them. Master the fundamentals once, and everything on top gets easier, and you'll stay ahead of the people chasing the framework of the week.
1/
A 5M-parameter model just beat frontier LLMs on hard logical puzzles at less than 1/100,000th of the inference cost.
How? By scaling test-time compute in continuous latent space rather than discrete token space.
Let's unpack how this works. 🧵
Deepseek's DSpark compared with DFlash and EAGLE-3 on MI300X
each method uses a ~3B parameter draft head that proposes 7 tokens at a time, which the 14B target model (Qwen) verifies in parallel. tested on three real world workloads:
- HumanEval (164 code problems)
- MT-Bench (80 multi-turn conversations)
- AIME 2025 (30 competition math problems).
DFlash uses a lightweight block based MLP draft head, it proposes tokens in fixed size blocks and relies on the draft head's speed to keep the target model fed. minimal overhead per proposal, but no mechanism to stop early when the draft is uncertain.
EAGLE-3 uses a TTT (Test Time Training) based draft head. it's more sophisticated in how it models token distributions, but the TTT mechanism adds computational cost per proposal. the tradeoff, potentially better acceptance rates in exchange for heavier per-iteration work.
DSpark also uses a block based draft head like DFlash, but adds a confidence head that predicts which tokens the draft is uncertain about. this enables early stopping if the confidence head detects low confidence, verification stops early, saving wasted compute on tokens that would likely be rejected anyway.
DSpark dominates every metric on every dataset. it achieves the highest acceptance length (avg 4.65 tokens vs 3.89 for DFlash and 3.50 for EAGLE-3), translates directly into the fastest throughput (avg 127 tok/s vs 111 for DFlash and 81 for EAGLE-3), and completes all benchmarks in the least wall time.
the confidence head's early stopping mechanism is the key differentiator, it avoids wasting target model compute on low-confidence tokens, which compounds into significant time savings across hundreds of proposals per benchmark.
the improvement over DFlash is notable:
+20% acceptance length
+14% throughput
DSpark also achieves the highest verify rates (67% on HumanEval, 62% on AIME25, 46% on MT-Bench), confirming that early stopping doesn't sacrifice quality, it just avoids wasting compute on tokens that would be rejected anyway.
the heavier per-proposal computation from the TTT mechanism appears to outweigh any gains in draft quality, especially on a single GPU where compute efficiency matters more than draft accuracy.
on multi-GPU setups with more compute headroom, EAGLE-3 might be closer, but for single GPU inference, DSpark's lightweight + early stopping approach is clearly superior.
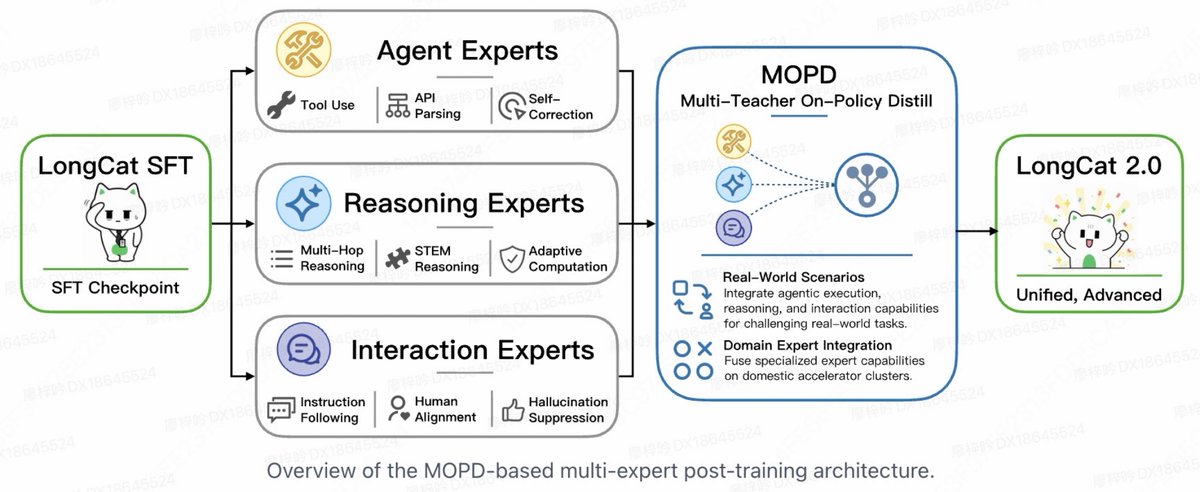
Introducing LongCat-2.0 🐱
1.6T parameters · MoE with ~48B active · 1M context
The full model behind Owl Alpha on @OpenRouter — now available.
Built for agentic coding from the ground up:
◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute
◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task
How it stacks up:
→ Terminal-Bench 2.1: 70.8
→ SWE-bench Pro: 59.5 (GPT-5.5: 58.6)
→ SWE-bench Multilingual: 77.3
→ FORTE: 73.2 · RWSearch: 78.8 · BrowseComp: 79.9
📖 Tech Blog: https://t.co/4KrjyKiDBn
Try it across different scenarios 🧵👇
We’ve been impressed with GLM-5.2 and so are introducing a $9.99/month subscription to give you 2-5x discounted access to it and other open weight models like DeepSeek, Kimi, MiniMax, Mimo, Qwen.
Use it on Cline CLI & IDE with $1.99 special promo if sign up via: npm i -g cline
A question I’ve been pondering: what if we'd known about o1 / RL on chain-of-thought back in the early days of LLMs?
It turns out SFT + a bit of RL on GPT-2 almost matches the performance of a fine-tuned GPT-3 (12b) on GSM8K — a model with >100x the pre-training compute.
🔗 GitHub: https://t.co/m3ZyrCZfPZ
---
✉️ If you’re into AI, ML, agents, and building real systems, join my newsletter (it’s free): https://t.co/zJ9uwd6qSd
My entire AI stack is now Chinese 🇨🇳
87% cheaper. same revenue
swaps by task:
1. reasoning / backend brain
Opus 4.8 → Kimi K2.7
benchmark gap: ~8% · price: ~11x cheaper
2. code generation
GPT-5.5 → Qwen 3.7 Max
benchmark gap: ~18% · price: ~7x cheaper
3. agent loops + tool calling
Sonnet 4.7 → GLM 5.2
benchmark gap: ~3% · price: ~5x cheaper on input
4. cheap volume / bulk processing
GPT-5.5 mini → MiMo V2.5
benchmark gap: ~6% · price: ~12x cheaper
5. image generation
GPT-Image-2 → Wan 2.5
benchmark gap: ~5% · price: ~8x cheaper
6. video generation
Sora 2 → Kling 3.0
benchmark gap: roughly equal · price: ~6x cheaper
[ result after 30 days: ]
operating costs dropped 87%, output quality dropped 4% on average, revenue unchanged
the most important that these models will be not banned in a month and i can run them locally
nobody will steal my data and i can learn them as i need
full article drops tomorrow with:
> exact routing logic per task type
> the 2 cases where I still pay for American
> the migration playbook anyone can copy in a weekend
VERY IMPORTANT to get migrated now, while it's not too late
OKAY - it seemed like DFlash would be the clear winner.
But it appears there have been some improvements with MTP.
With MTP + split-mode = tensor, Qwen3.6-27B gets over 120 tokens/second on dual RTX 3090s (note I am running PCIE x16 on both, I don't have an NVLink bridge).
This is absolutely insane - stock this model gets 20 - 30 tokens/second on this setup. That is over a 6x increase in speed.
But that's not the end of it - if GGML adds tensor splitting support for DFlash, DFlash could pull ahead once more.
Absolutely wild to see what's happening in the local model space right now.
This is the most exciting time to own GPUs!
Here is the "golden" setup:
[Ornstein3.6-27B-MTP-NSC-ACE-SABER] @DJLougen
n-gpu-layers = 999
flash-attn = on
cont-batching = true
jinja = true
no-mmap = true
split-mode = tensor
fit = off
ctx-size = 131072
cache-type-k = q8_0
cache-type-v = q8_0
spec-type = draft-mtp
spec-draft-n-max = 8
temp = 0.7
top-p = 0.95
top-k = 20
chat-template-kwargs = {"preserve_thinking": true}
Wow!!!
1/
We have been treating GPU memory all wrong.
What if the GPU didn't need to store your model at all?
MegaTrain enables full-precision training of 100B+ LLMs on a single GPU by turning VRAM into a transient, stateless cache.
The secret? Inverting the memory hierarchy. 🧵
Elysia compilation time to get faster from 18.4x to 55.8x
This means Elysia will get much better in Serverless environment like Cloudflare Worker, AWS Lambda, and much more































![DeRonin_'s tweet photo. My entire AI stack is now Chinese 🇨🇳
87% cheaper. same revenue
swaps by task:
1. reasoning / backend brain
Opus 4.8 → Kimi K2.7
benchmark gap: ~8% · price: ~11x cheaper
2. code generation
GPT-5.5 → Qwen 3.7 Max
benchmark gap: ~18% · price: ~7x cheaper
3. agent loops + tool calling
Sonnet 4.7 → GLM 5.2
benchmark gap: ~3% · price: ~5x cheaper on input
4. cheap volume / bulk processing
GPT-5.5 mini → MiMo V2.5
benchmark gap: ~6% · price: ~12x cheaper
5. image generation
GPT-Image-2 → Wan 2.5
benchmark gap: ~5% · price: ~8x cheaper
6. video generation
Sora 2 → Kling 3.0
benchmark gap: roughly equal · price: ~6x cheaper
[ result after 30 days: ]
operating costs dropped 87%, output quality dropped 4% on average, revenue unchanged
the most important that these models will be not banned in a month and i can run them locally
nobody will steal my data and i can learn them as i need
full article drops tomorrow with:
> exact routing logic per task type
> the 2 cases where I still pay for American
> the migration playbook anyone can copy in a weekend
VERY IMPORTANT to get migrated now, while it's not too late](https://pbs.twimg.com/media/HL-p_PyWoAA42S2.jpg)
![JoelDeTeves's tweet photo. OKAY - it seemed like DFlash would be the clear winner.
But it appears there have been some improvements with MTP.
With MTP + split-mode = tensor, Qwen3.6-27B gets over 120 tokens/second on dual RTX 3090s (note I am running PCIE x16 on both, I don't have an NVLink bridge).
This is absolutely insane - stock this model gets 20 - 30 tokens/second on this setup. That is over a 6x increase in speed.
But that's not the end of it - if GGML adds tensor splitting support for DFlash, DFlash could pull ahead once more.
Absolutely wild to see what's happening in the local model space right now.
This is the most exciting time to own GPUs!
Here is the "golden" setup:
[Ornstein3.6-27B-MTP-NSC-ACE-SABER] @DJLougen
n-gpu-layers = 999
flash-attn = on
cont-batching = true
jinja = true
no-mmap = true
split-mode = tensor
fit = off
ctx-size = 131072
cache-type-k = q8_0
cache-type-v = q8_0
spec-type = draft-mtp
spec-draft-n-max = 8
temp = 0.7
top-p = 0.95
top-k = 20
chat-template-kwargs = {"preserve_thinking": true}
Wow!!!](https://pbs.twimg.com/media/HL8axJ-a8AAaT4o.jpg)
































