Introducing MilliVid, our new method for long-context video generation! MilliVid creates videos that are consistent over long time spans, without using retrieval heuristics or 3D maps! (1/n)
https://t.co/evmf5dL5Sg
Many of my students / collaborators are at CVPR - find them & chat!
@ottogin1, diffusion models
@ericmchen1, latent actions & robotics
@RyuHyunwoooo, latent actions & robotics
@ekim2339, robotics, view synthesis
@SimulatedAnneal, robotics
@twmitchel, latent actions & video
How well can a model watch a short video of some physical dynamics and actually predict what happens next?
Introducing MPMWorlds: a new dataset and benchmark to evaluate how well models can reconstruct and extrapolate physical dynamics from video.
https://t.co/w6Yz8S5xBg
🧵👇
(1/n)
Come check out our talk at #CHI2026 tomorrow (Fri) at 9:45am! We present CineCraft, an interactive mobile app that unifies planning, capture, and post-processing for cinematography on a single device. Fun combining my filmmaking hobbies with research! https://t.co/UAWA7nhR6m
This work was done during my internship at Snap Research, before starting my PhD, with Di Liu, @MaSizhuo60625, Michael Vasilkovsky, Bing Zhou, Qiang Gao, Wenzhou Wang, Jiahao Luo, Dimitri Metaxas,
@vincesitzmann, and Jian Wang
If you're at @wacv_official tomorrow come see our poster on Snapmoji! It's our system to generate and animate 3D avatars of yourself. I'll be at poster location 51 from 4:00-5:45 on Sunday!
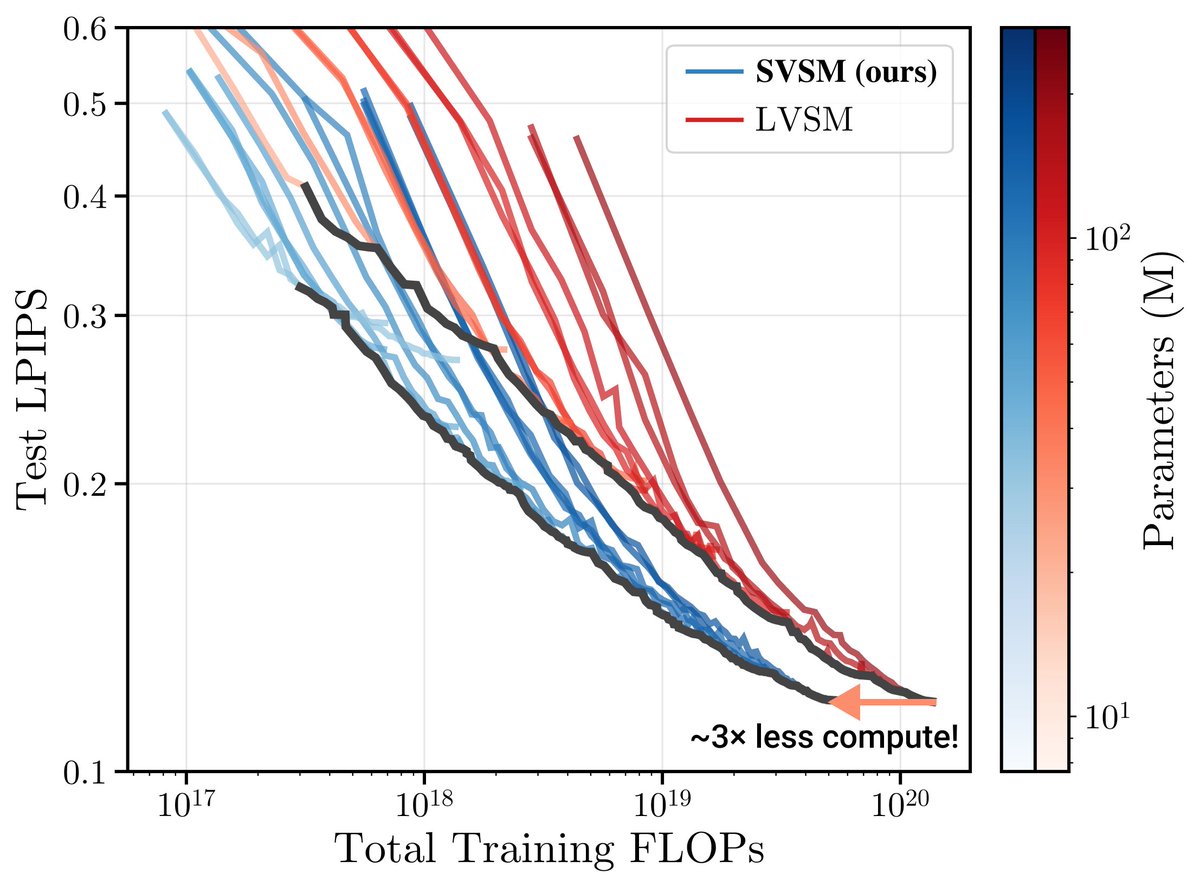
How do you train compute-optimal novel view synthesis models?
In our CVPR ‘26 paper Scaling View Synthesis Transformers, we uncover key design choices through scaling and careful ablations--and along the way train a new SoTA with 3x less compute. (1/n)
@RadianceFields It's really hard to tell what renders are splats and what are traditional photogrammetry techniques. But here I think the elongated Gaussian artifacts made it easy to tell
Introducing Large Video Planner (LVP-14B) — a robot foundation model that actually generalizes. LVP is built on video gen, not VLA. As my final work at @MIT, LVP has all its eval tasks proposed by third parties as a maximum stress test, but it excels!🤗
https://t.co/wjD54YFK3k
Happy to finally share our latest work on Dataset Distillation!
"Dataset Distillation for Pre-Trained Self-Supervised Vision Models," set to appear at #NeurIPS 2025!
We learn 1 image per class to train linear heads for pre-trained models.
https://t.co/JD9yQnR6mp
1/6
🔈@SeanXZhan and I are excited to share PhysiOpt, a differentiable physics optimizer that improves the physical integrity of 3D generative model outputs, which we will present at SIGGRAPH Asia 2025 in collaboration with Evan Thompson, Kenney Ng, and Mina Konaković Luković.
This is more apparent than ever for #ICLR2026. Reviewers accusing authors of abusing AI. Authors accusing reviewers of abusing AI. Are they right? Maybe. But regardless, everyone is looking over their shoulders and at each others' throats.