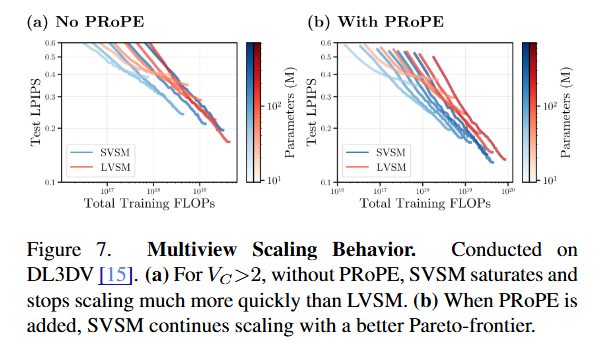
How do you train compute-optimal novel view synthesis models?
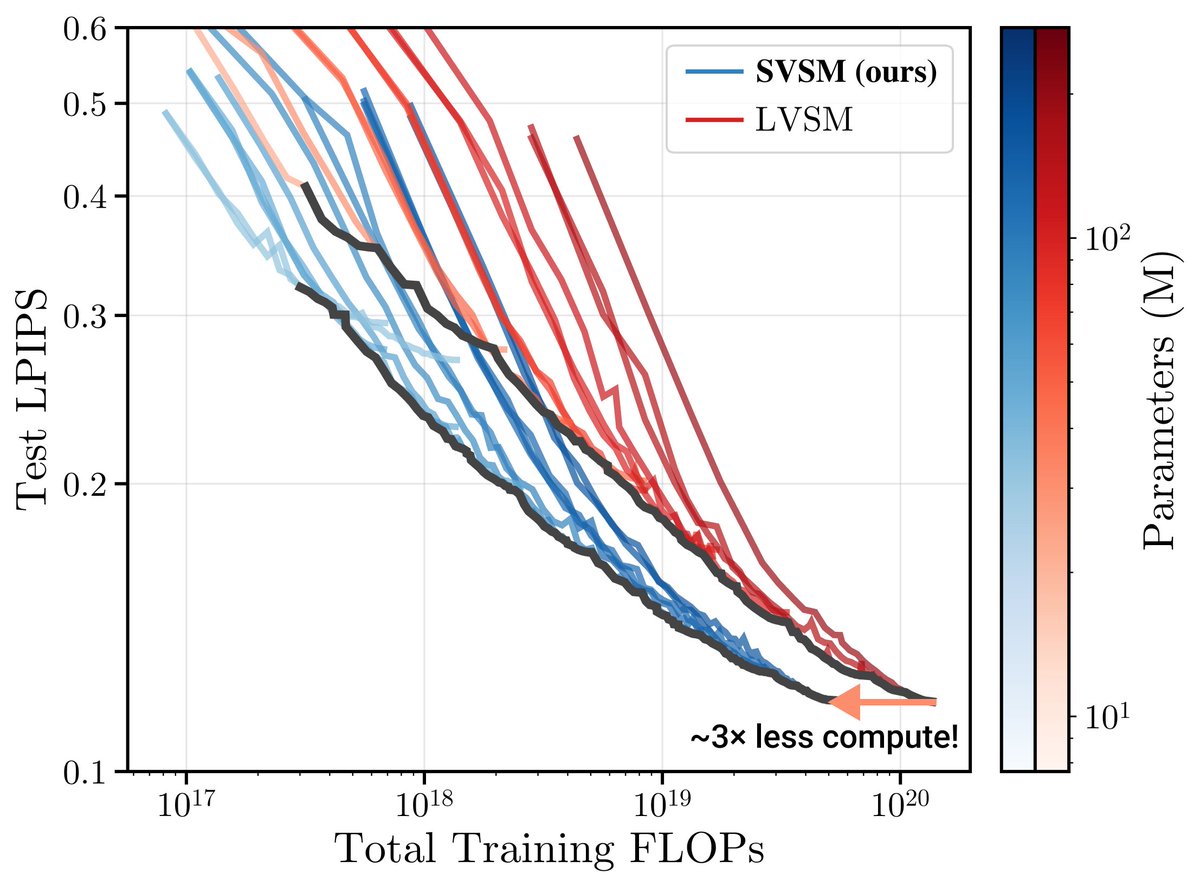
In our CVPR ‘26 paper Scaling View Synthesis Transformers, we uncover key design choices through scaling and careful ablations--and along the way train a new SoTA with 3x less compute. (1/n)
Today’s vision benchmarks suggest VLMs are nearing saturation, but real-world visual understanding is far from solved.
Introducing WorldBench: 2,000 hand-written, human-verified VQA questions focused on visual diversity and designed to be challenging for frontier models. Gemini-3.1-Pro leads with just 64.0% accuracy. (1/10)
What if every image in your training set is corrupted, masked, blurred, or compressed, and you don’t have any clean data points? This is often the case in many areas like MRI scans, satellite images, and many datasets in the real world.
Can you still train a diffusion model and recover the clean distribution?
Yes, as long as the corruption channel is known and invertible on distribution level. We introduce DiffEM, a framework to do this with diffusion models. 🧵 (1/n)
Dreamverse is our AI video engine that generates a video faster than you can watch it.
30s of 1080p video in 4.5 seconds. One GPU. Real-time editing.
This is vibe-directing.
https://t.co/HEfd8cupc6
⚡️We built a new real-time inference stack in FastVideo and have the fastest 1080p TI2AV (text + image to audio and video) pipeline ever.
Create a 5 s 1080p video with audio in ~4.55 s on a single GPU!
High-quality video generation must be fast to be truly interactive. The only limit in creative workflows should be your imagination.
If you have the need for speed (and quality), make video generation go blurrr (for free) at https://t.co/U9LLNQuISI and create whatever you can imagine…
How do you train compute-optimal novel view synthesis models?
In our CVPR ‘26 paper Scaling View Synthesis Transformers, we uncover key design choices through scaling and careful ablations--and along the way train a new SoTA with 3x less compute. (1/n)
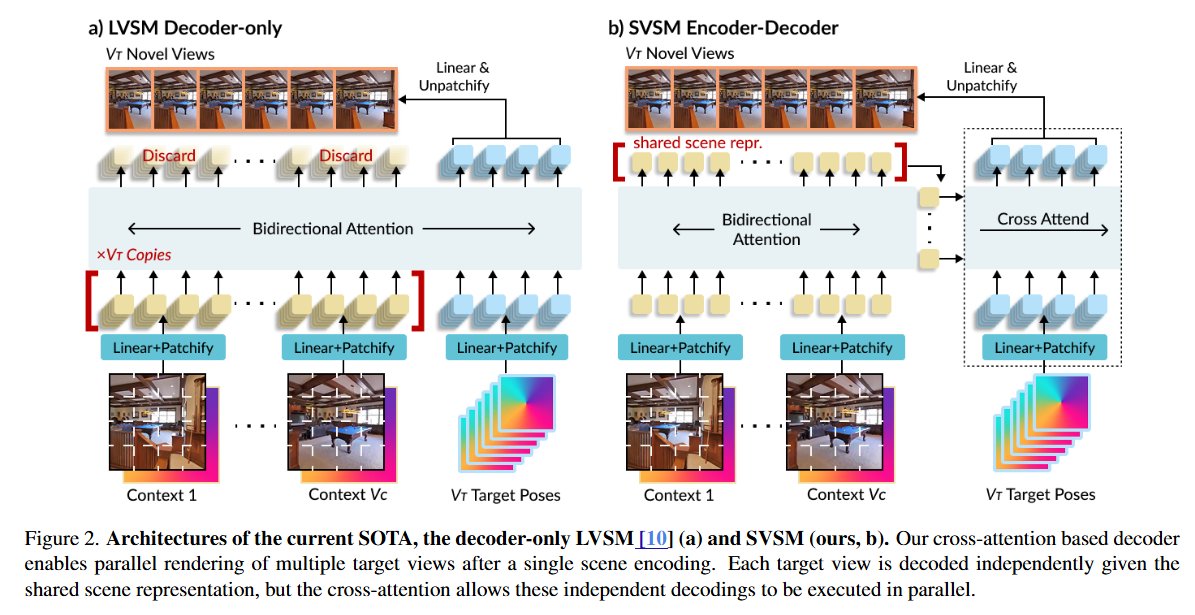
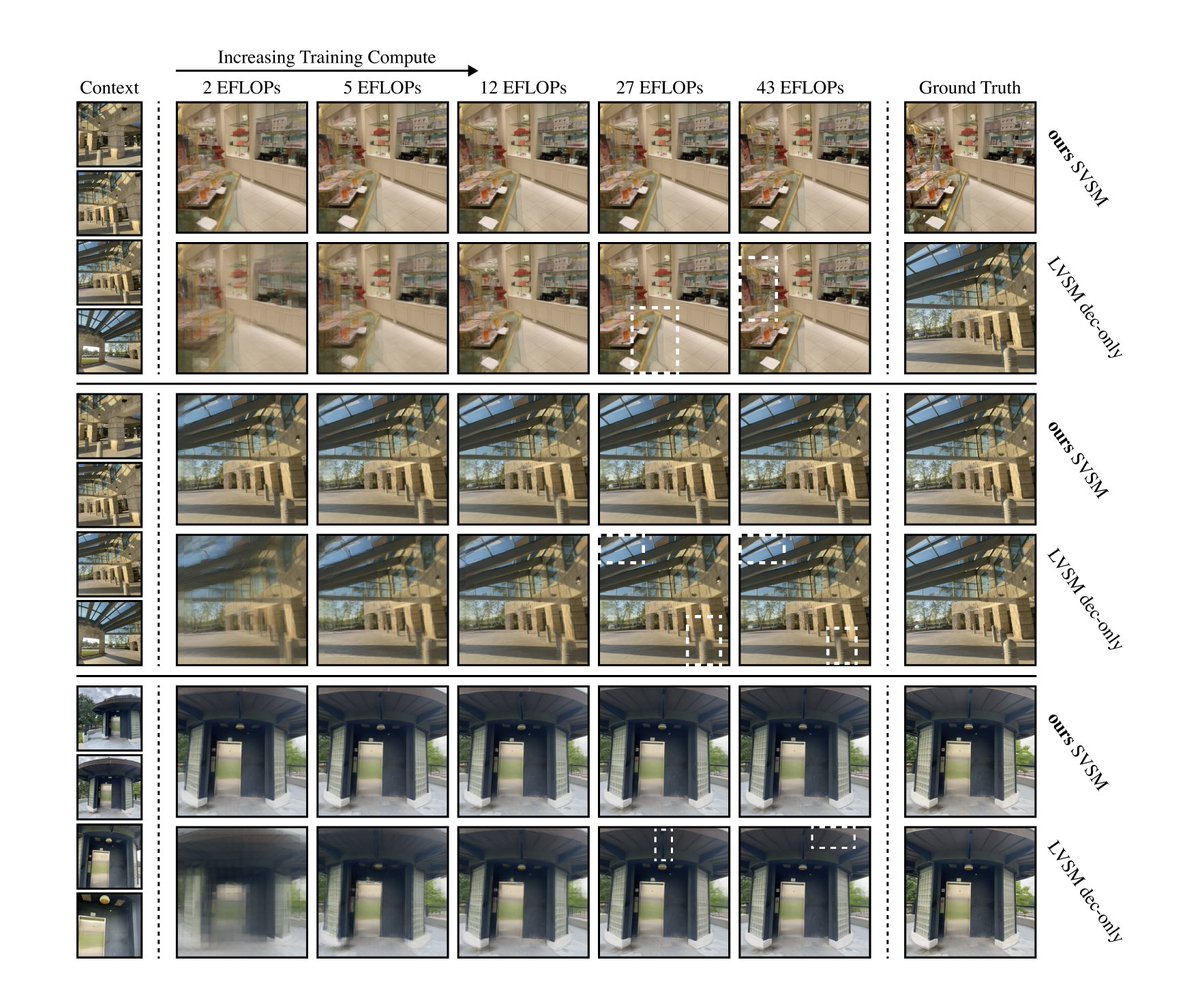
Evan is an undergraduate researcher in my group, and within less than a year put together a really cool paper on the scaling laws of novel view synthesis - surprisingly, he found an encoder-decoder model that actually scales *better* than a decoder-only LVSM model!
This is work with @RyuHyunwoooo@twmitchel and @vincesitzmann ! (n/n)
📄 Paper: https://t.co/CujoTH0lwD
💻 Code: https://t.co/hoatPlf5En
🎥 Website: https://t.co/2YpziNdZ7r
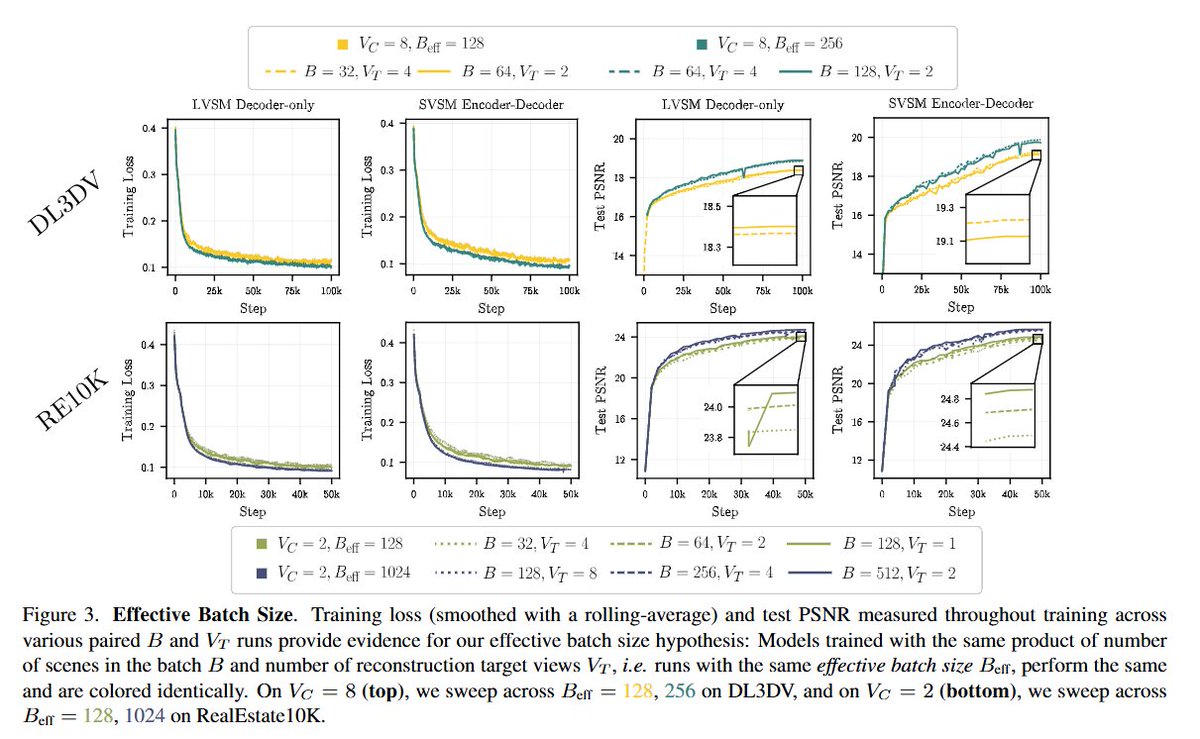
In sum: cross attention works, treat B*Vt as your batch size, fixed-size encodings don’t scale, and PRoPE/GTA work great. Our unidirectional finding also nicely mirrors the scalability of causal attention in language modeling! (7/n)