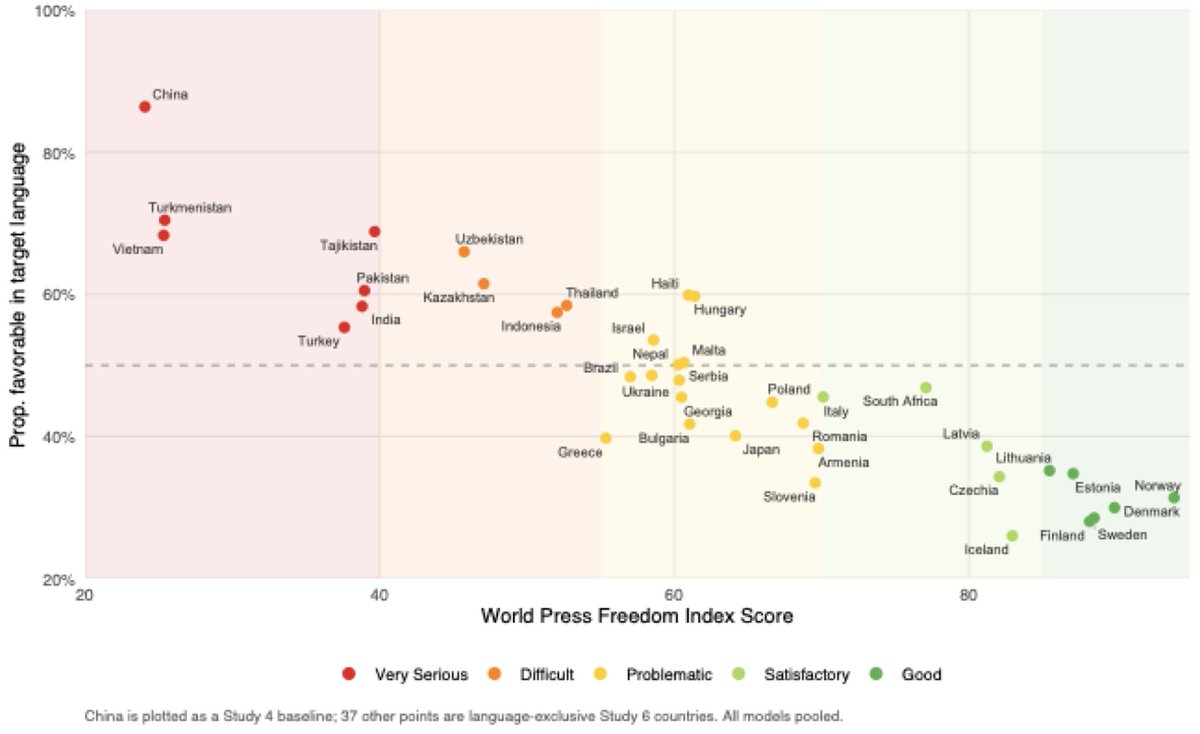
1/ New @Nature! We study how powerful institutions shape the information environment for LLMs. Commercial LLM training is opaque, so we trace a path from state-coordinated media -> training data -> model responses.
New paper in Nature. The more a government controls its domestic media, the more it dominates AI training data, the more pro-regime outputs we get from AI. By scraping the open web, LLMs are unwittingly laundering state-coordinated narratives into seemingly objective answers.
New in Nature: LLMs give "the party line" in the languages of authoritarian regimes. This works when they control the media, which feeds pretraining data. We show more state control over media means less critical LLMs. 6 studies w 38 languages & 13 models. Details ↓
Simon Johnson and I are hiring a postdoc at MIT to research the history, social implications, and future of technology. The job description and application link are available here: https://t.co/wTZaAuy1wr
I’m hiring a predoc starting this summer. The focus is building AI workflows to improve research efficiency.
More importantly, I value independent thinking and ambition. You do not need to fit into a narrow topic.
If you’re interested in applied statistics, causal inference, or Chinese politics, broadly defined, plz apply. You can propose your own project --- I will support it.
https://t.co/GFYCuBj1Gu
New paper at AJPS: "The limits of AI for authoritarian control." The more repression there is, the less information exists in AI's training data, and the worse the AI performs. Ironically, data from democracies can help improve repressive AI.
@raphpfei Fair point. It will partly depend on how much people change how they talk about things in light of new technologies. LLMs replicate but it was late in the review process n hard to change the entire paper.
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.