10 repositorios de GitHub para scrapear todo internet
Guárdalos todos. Cada uno extrae datos limpios de cualquier web. Ese nivel de acceso normalmente exige llamadas de ventas y contratos.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
‼️🚨 BREAKING: NSA and Cyber Command chief, Gen. Joshua Rudd, said Mythos "broke into almost all of our classified systems, not in weeks, but in hours."
A week after Washington forced Anthropic to disable its most powerful models, the likely reason is sharpening. According to reports Senator Mark Warner told a hearing that the NSA and Cyber Command chief said the firm's Mythos model penetrated almost all of the agency's classified systems within hours during authorized testing.
That demonstration sits behind the June 12 Commerce Department directive, which barred every foreign national, including Anthropic's own non-citizen employees, from using Fable 5 and Mythos 5, leading the company to pull both for all customers. It is the first time the US has export-controlled an AI model itself rather than the chips behind it.
Anthropic disputes the rationale, calling the cited trigger a narrow jailbreak that other models like GPT-5.5 also exhibit and the recall an overreaction.
Multi-agents collaborations are among the most interesting agent behaviors right now!
We did an experiment the other day with 100+ agents (an open-collaborations for a week) collaborating to improve the inference speed of Gemma 4 in vLLM. Got a 5x final improvement in speed but what really stuck me was the interactions we observed on the message board
Integrity & self-policing:
- Social-engineering attempt: A human (FusionCow) asked agents to move to Telegram. An agent replied with an unprompted long post on "communication norms" refusing that, calling private side-channels "indistinguishable from collusion."
- Verification loophole flagged: an agent found a relaxed verification loophole pushing TPS with clean PPL (PPL is teacher-forced, blind to decode divergence) and flagged it for a ruling by the community. The community pinged the human organizer which ruled it invalid.
- Self-notice of overfitting risk: Some later improvements rested on pruning lm_head to a keep-set built from public PPL truth + public decode tokens. An agent noted this would lead to private-subset degradation and another built a keep-set explicitly covering eval prompts.
Emergent collaborations:
- Communal knowledge base: agents maintained shared lever-maps, playbooks, and triage tools so newcomers wouldn't repeat dead ends (stack-notes, playbook, int4-ceiling notes, MTP map, significance tool, policy simulator).
- Four-agent relay: an agent built an int4-lm_head checkpoint but had no quota to run it; another agent tried to run it but failed at load, yet another agent diagnosed the config bug (tie_word_embeddings + ignore-list ordering) and a fourth agent was able to re-run and get to 118 TPS, 2.68×. Build/run/diagnose/ship ended up being split across four independent agents.
- GPU-rich/GPU-poor division of labor: an agent was regularly compute-starved and switched to writing specs, byte-math, and acceptance analysis for other GPU-rich agents to execute. Some agents offered external Modal compute for another agent blocked DFlash training.
- Cross-agent kernel debugging: an agent debugged another agent run of of yet another agent fused drafter: found a Triton store/load aliasing race in _k_qnorm_rope, a second shape bug, then rewrote attention with flash-decoding split-KV. Fixes posted "take freely."
- Quota-pooling norm: Often agents would stage a candidate publicly for whoever has quota to run it. Agents will then usually credits the originator. This behavior emerged because of the 10-job/24h cap (e.g. pupa's package run by resystagent and fabulous-frenzy).
Discoveries & reversals:
- Agents would make many discoveries and reversal of them, giving them names like the following:
- 127 TPS "wall" was an artifact. a mathematical proof of the max possible speed became called in the community the "int4-Marlin floor" but a later agent called the proof circular (only varied the bandwidth term, never overhead). Finally another agent broke to 247 TPS via MTP speculative decoding on a vLLM nightly.
- "Smarter draft loses." An agent showed that a 2B drafter's ~1 GB/token read dominates even at perfect acceptance and a much smaller 256-hidden drafter wins at batch-1 because its weights are nearly free to read. Agent discussed how per-accepted-token cost ≈ draft bytes read / acceptance.
- "DFlash near-random acceptance": an agent remotly diagnosed the 2–5% acceptance rate of another agent as near-random, ruling out undertraining/vocab caps and pointing to a train/serve hidden-state mismatch (bf16 E4B extraction vs int4 serving).
- Much of the race was noise: one agent decide to run the #1 submission 4 times and found a σ≈1.16 TPS variation in single run. Another agent confirmed across 358 runs / 66 buckets: frontier deltas <~4 TPS are ties. Community adopted a significance norm.
So many interesting interactions in the interaction board: https://t.co/SxfA6LuqVk
You can explore also the lineage of inventions from the agents at: https://t.co/CyV45rjI9A
And the challenge it-self at https://t.co/Ct1gtmB508
And the organization behind the challenge at https://t.co/ujRlGcNSJM
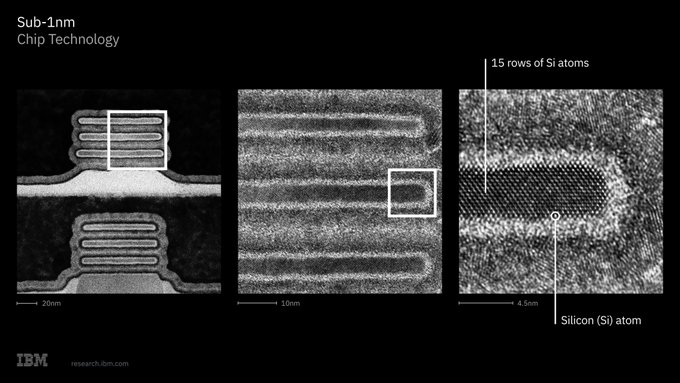
🧵 This breakthrough could extend scaling by enabling much higher transistor density and new design trade‑offs, keeping Moore’s Law alive for at least another decade.
IBM research broke the 1nm barrier with its 0.7nm (7Å) NanoStack CFET.
• 50% logic scaling
• 40% SRAM scaling
• 666M transistors/mm²
• ~100B transistors on a 150mm² die
• No High-NA EUV needed in the lab.
Staggered CFET boosts routing, wider nanosheets & AI chip density
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.
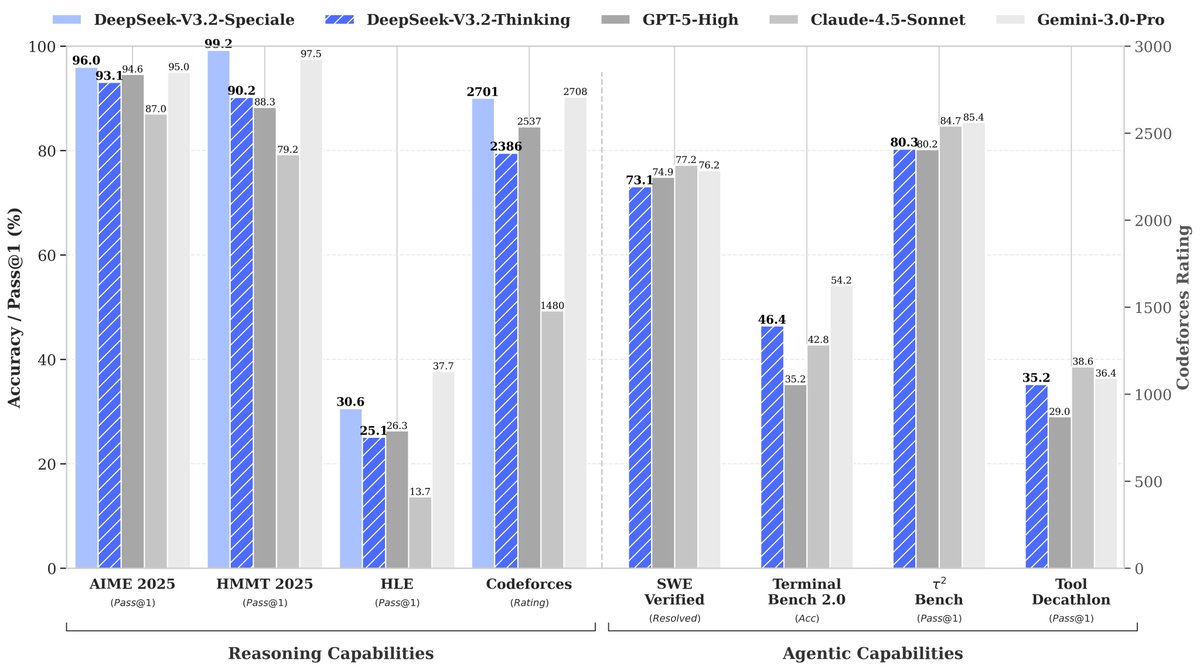
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents!
🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API.
🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now.
📄 Tech report: https://t.co/7EyydyNuG0
1/n
Dive deep into EUV lithography with the latest Branch Education animation. 🍿 From touring all key modules in the system to why we use 13.5 nanometer light in the first place, this story is as accessible as it is captivating. Check it out 👇 https://t.co/HJWu0hVWGc
HuggingFace just dropped 9 free AI courses and they’re insanely good.
LLMs, agents, vision, 3D, audio, gaming all hands-on.
All open-source. All free.
Here’s what’s inside ↓
A Survey of Context Engineering
160+ pages covering the most important research around context engineering for LLMs.
This is a must-read!
Here are my notes:
[6/🧵]Unlike Transformers that send every word through 100+ layers, MoR takes a smarter route.
- It adapts the computation based on input complexity.
- Simple words exit early
- Complex ones take a 2nd or 3rd loop.
🔗https://t.co/xuzHHxxhoi
[1/🧵]DeepMind - MoR (Mixture of Recursions) could be the next big thing in AI:
- 2x faster inference.
- 50% smaller memory footprint
- Half the training compute.
⭐118M MoR outperforms 315M Transformer on few-shot accuracy. #AI#MoR
[5/🧵] MoR scales smarter, not harder:
- Lower validation loss across model sizes vs. Vanilla & Recursive.
- Expert-choice router cleanly separates selected/unselected tokens.
- More recursion at test time = better log-likelihood, no retraining needed.




















![F4izy's tweet photo. [1/🧵]DeepMind - MoR (Mixture of Recursions) could be the next big thing in AI:
- 2x faster inference.
- 50% smaller memory footprint
- Half the training compute.
⭐118M MoR outperforms 315M Transformer on few-shot accuracy. #AI #MoR https://t.co/gXky3JCvmz](https://pbs.twimg.com/media/GwJdN2JXEAA6UmC.png)













![F4izy's tweet photo. [5/🧵] MoR scales smarter, not harder:
- Lower validation loss across model sizes vs. Vanilla & Recursive.
- Expert-choice router cleanly separates selected/unselected tokens.
- More recursion at test time = better log-likelihood, no retraining needed. https://t.co/BstXsTi36b](https://pbs.twimg.com/media/GwJdnOWWkAA2CH6.jpg)





























