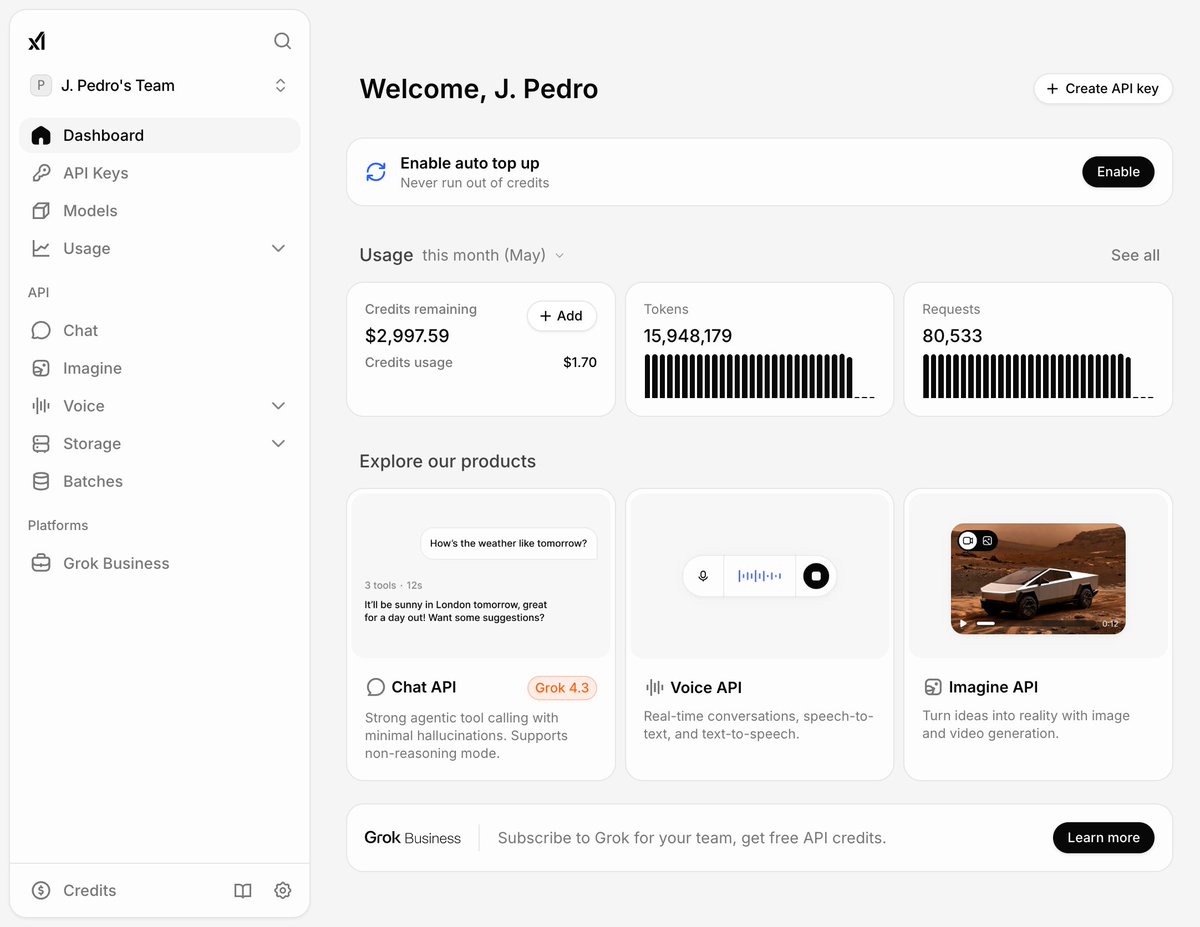
The new @xai Cloud Console is here 🚀
• Improved onboarding
• Faster checkout
• Cleaner navigation
More coming soon. Go check it out https://t.co/pCTpWWi8tj
Grok Build is now available in Beta for all SuperGrok and X Premium+ users.
Use Plan Mode, create images and videos with Imagine, and build automations or orchestrators with the CLI.
Visit https://t.co/bpTHpjivWD to get started.
@TobyPhln@xai@elonmusk You are one of the most exceptional people I have ever had the pleasure to work with. Thank you for bringing me into xAI and for leading us the way you did. It's been an absolute honor. Good luck with whatever comes next and enjoy the well earned sleep!
@xAI has acquired @X in an all-stock transaction. The combination values xAI at $80 billion and X at $33 billion ($45B less $12B debt).
Since its founding two years ago, xAI has rapidly become one of the leading AI labs in the world, building models and data centers at unprecedented speed and scale.
X is the digital town square where more than 600M active users go to find the real-time source of ground truth and, in the last two years, has been transformed into one of the most efficient companies in the world, positioning it to deliver scalable future growth.
xAI and X’s futures are intertwined. Today, we officially take the step to combine the data, models, compute, distribution and talent. This combination will unlock immense potential by blending xAI’s advanced AI capability and expertise with X’s massive reach. The combined company will deliver smarter, more meaningful experiences to billions of people while staying true to our core mission of seeking truth and advancing knowledge. This will allow us to build a platform that doesn’t just reflect the world but actively accelerates human progress.
I would like to recognize the hardcore dedication of everyone at xAI and X that has brought us to this point. This is just the beginning.
Thank you for your continued partnership and support.
My close physician friend just messaged me-this is amazing: He had been following a patient with a chronic disease for many years, trying various treatments to no avail. He recently uploaded all the data to Grok, which suggested a specific treatment. Now, the patient seems cured!
📰More exciting news today: @xai's latest Grok-3 tops the Arena leaderboard! 🔥
This is the newest, production model, grok-3-preview-02-24
With over 3k votes, this model is tied for #1 overall, and across Hard Prompts, Coding, Math, Creative Writing, Instruction Following, and Longer Query.
Huge congratulations to @xai on this impressive milestone! 🙌
"Move 37" is the word-of-day - it's when an AI, trained via the trial-and-error process of reinforcement learning, discovers actions that are new, surprising, and secretly brilliant even to expert humans. It is a magical, just slightly unnerving, emergent phenomenon only achievable by large-scale reinforcement learning. You can't get there by expert imitation. It's when AlphaGo played move 37 in Game 2 against Lee Sedol, a weird move that was estimated to only have 1 in 10,000 chance to be played by a human, but one that was creative and brilliant in retrospect, leading to a win in that game.
We've seen Move 37 in a closed, game-like environment like Go, but with the latest crop of "thinking" LLM models (e.g. OpenAI-o1, DeepSeek-R1, Gemini 2.0 Flash Thinking), we are seeing the first very early glimmers of things like it in open world domains. The models discover, in the process of trying to solve many diverse math/code/etc. problems, strategies that resemble the internal monologue of humans, which are very hard (/impossible) to directly program into the models. I call these "cognitive strategies" - things like approaching a problem from different angles, trying out different ideas, finding analogies, backtracking, re-examining, etc. Weird as it sounds, it's plausible that LLMs can discover better ways of thinking, of solving problems, of connecting ideas across disciplines, and do so in a way we will find surprising, puzzling, but creative and brilliant in retrospect. It could get plenty weirder too - it's plausible (even likely, if it's done well) that the optimization invents its own language that is inscrutable to us, but that is more efficient or effective at problem solving. The weirdness of reinforcement learning is in principle unbounded.
I don't think we've seen equivalents of Move 37 yet. I don't know what it will look like. I think we're still quite early and that there is a lot of work ahead, both engineering and research. But the technology feels on track to find them.
https://t.co/JCxTdKpuzv