Building the next frontier of AI requires exceptional technical leadership. We’re hiring a Research Scientist (Director+) to join the Frontier AI team at @GoogleDeepMind in Zurich 🇨🇭.
Apply here: https://t.co/BGBXX9RVYr
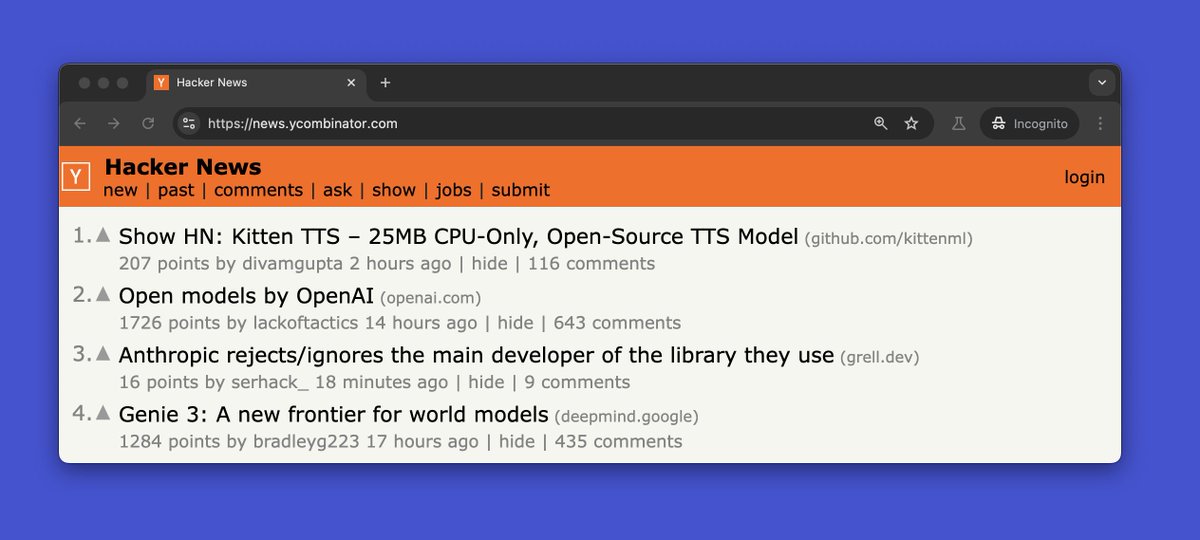
We launched on possibly the worst timing ever - right when OpenAI, Google DeepMind, and Anthropic all had major releases. Somehow we still made it to #1 on Hacker News. Thanks to everyone who checked us out! 🙏
Last year we launched the Swiss AI red-teaming network with @ETH@EPFL and multiple companies
We started off with discussing pragmatic prompt injection defenses
We compiled our thoughts into a list of "design patterns" that we think can be effective in many practical settings
You're in Zurich or its zone of influence (Lausanne, Paris, BXL, Munich, London, ...) and like AI + Robots?
We (@openai) together with @mimicrobotics, @lokirobotics, and Zurich Builds are organizing a hackathon from Fri 9 May afternoon to Sun 11.
Limited spots, more below:
Sam and I did a deep dive into some of our recent results, discussing how language models plan, perform computations, and reason across languages!
If you use LLMs like Claude and want to know how they work, I recommend giving it a listen. No technical background needed!
@OfficialLoganK Look like logprobs is not available anymore on EU endpoint for Gemini 1.5 flash or pro 002 using vertex AI SDK 1.71.1. Did we missed something?
Swiss Python Summit Early Bird Alert! 🇨🇭🐍🎉
Get your tickets on https://t.co/Nwp9JvUbZm before it's too late and save up to 40%! 🤩
#python#pythonsummit#EarlyBird#Discount
If you remember our Applied LLMs course, you'll love this. Today, we are making all these resources available for free to everyone! 📚
We did extra work to add learning tracks, resources, and notes to each lesson to maximize your learning. Link in next tweet
"The little book of Deep Learning" update v1.2!
Minor updates ("meta-parameter" -> "hyper-parameter") + fine-tuning in 3.6 + a new chapter 8.
Draft below, comments are welcome.
The "Self-Extend" paper https://t.co/6FxvNVKyca promises magic for your LLMs: extending the context window beyond what they were trained on. You can take an LLM trained on 2000 token sequences, feed it 5000 tokens and expect it to work. Thread 🧵
(SWA below=sliding window attn.)
Thanks, everyone, for all the support and positive words for my "Build a Large Language Model (from Scratch)" book!
The next chapter on *coding self-attention, multi-head attention, and causal self-attention from scratch* is on the way and will be in the MEAP in a few weeks!
For a sneak peek, you can find the code (along with short notes here): https://t.co/gVvAX4OZWD.