A team at Oxford built a search engine for every drug the NHS prescribes, and it has quietly saved the health service millions.
It's called OpenPrescribing.
The NHS publishes its full prescribing dataset every month. It's 700 million rows of raw numbers nobody could actually read. So Oxford built a tool that turns it into live charts in seconds.
You type a drug name. It shows you which practices over-prescribe it, which regions are slow to follow new guidelines, and where the money is being wasted.
→ Search any drug across any GP practice in England
→ Find safety and cost outliers instantly
→ 70+ ready-made quality measures
→ Updates monthly, automatically
→ Free, open source, MIT licensed
20,000 people use it every month. Doctors. Researchers. Journalists.
Public data that sat unreadable for years is now one search away.
https://t.co/U9KI0mUCAp
Sure, GoogleMaps is cool but not half as cool as ORBIS. The Stanford Geospatial Network Model of the Roman World allows you to check travel times during Roman times. You can choose your mode of travel too! Source: https://t.co/zgVnhUdbKh
Dear @kcoleman. Please may you reconsider the latest 'following' feed algorithm. I love seeing what the people I follow post but the recent decision to also show me posts they reply to has just served to introduce poor content and throwaway comments - more annoying than useful🤔
A year ago at GTC, Jensen brought out a DGX Spark in one hand and a MacBook in the other.
Yesterday, at GTC Taipei, Jensen brought out NVIDIA's new RTX Spark laptop in both hands.
This is the start of a new era of personal computing - the personal AI era.
In the new era, there are two competing platforms:
- @apple with macOS / MLX
- @nvidia with Windows / CUDA
Everyone will have an always-on personal agent that runs locally, constantly looking out for you, working for you proactively, monitoring the internet and talking to other agents. This will be a personal AI agent you own, that's private, that's aligned with you (not OpenAI or Anthropic). @karpathy calls it personal computing v2.
Let's set the scene for the new era of personal computing by diving into the one thing that will matter the most - the hardware.
The best hardware for local AI isn't what's running in a data center. It's a radically different problem. Here's a breakdown of the 3 most important things:
1. Memory.
LLMs are big. To run a model locally, you need to fit the entire model into memory. Apple (with Apple Silicon) and NVIDIA (with DGX Spark + RTX Spark) have both moved towards unified memory, which puts all the memory on one chip - leveraging cheaper LPDDR5X memory - useful for making more memory accessible to the GPU. The alternative competing architecture is a disaggregated CPU/GPU architecture - which is what the DGX Station uses. It has a large pool of slow LPDDR5X CPU memory (496GB @ 396GB/s), and a small pool of high-speed HBM3e GPU memory (252GB @ 7.1TB/s). It has a high bandwidth link (900GB/s) between the CPU memory and GPU memory, enabling fast disaggregated inference e.g. Attention on GPU, FFN on CPU. This enables running really large models like Kimi K2.6 (1T parameters) by offloading experts from CPU memory to GPU memory as they are needed. You could imagine something like this in a smaller form factor.
Hardware today:
- Apple M5 Max MacBook Pro: 128GB unified memory.
- NVIDIA DGX Spark / RTX Spark: 128GB unified memory.
2. Memory bandwidth.
In a data center, multiple user's requests can be batched together, which amortizes the cost of moving model weights into memory across many requests, pushing up arithmetic intensity to compute bound territory - meaning FLOPS matters a lot. Locally, everything runs at low batch size, which is low arithmetic intensity, i.e. memory bound - so FLOPS don't matter. What matters memory bandwidth. High memory bandwidth -> fast TPS. Low memory bandwidth -> slow TPS.
Hardware today:
- Apple M5 Max MacBook Pro: 617GB/s memory bandwidth.
- NVIDIA DGX Spark: 273GB/s memory bandwidth.
- NVIDIA RTX Spark: TBC.
3. Power.
In a data center, we talk about MegaWatts. Locally, we talk about Watts. Laptops have limited battery life. The best laptop batteries have a capacity of ~100Wh. LLM inference on a MacBook Pro consumes ~140W, meaning battery life with a persistent personal agent is less than an hour. This is unusable. The game will become how long can you run a useful agent on a laptop battery. Apple and NVIDIA will compete on how long an agent can run on battery - this will become the new battery life metric. This could be where an NPU or NPU/GPU hybrid really shines. Apple ANE has about 10x better power efficiency than the GPU on Apple Silicon (but has ~4-5x less memory bandwidth, with about the same FLOPS as the GPU). There will be an entire design space of how to build energy efficient agents - this will involve co-optimizing the harness, models, inference engines together.
Hardware today:
- Apple M5 Max MacBook Pro: Consumes 140W, battery capacity ~100Wh
- NVIDIA DGX Spark: Rated for 240W, consumes 140W. No battery (direct PSU).
- NVIDIA RTX Spark: TBC.
The hardware battle will be fierce, and I expect a move towards co-design, i.e. hardware designed *with* personal agent workloads. On top of this, models are improving, we're getting more intelligence per bit/watt, and open-source harnesses like @NousResearch Hermes / OpenClaw are improving rapidly. Within the next 2 years, we'll inevitably have unmetered, private Opus-4.8 / GPT-5.5 level intelligence running locally on a future version of a MacBook or RTX Spark. I like this future a lot better than the one where OpenAI / Anthropic control the intelligence layer of the internet and can rent-seek on intelligence.
Beyond this, NVIDIA is ahead on general AI ecosystem, i.e. the CUDA moat. Apple is ahead on local AI ecosystem, i.e. models quantized/rightsized for MacBooks, native macOS apps, and ease of setup. We'll see how this might change as the new RTX Spark also brings full native CUDA to Windows-on-Arm laptops for the first time, potentially closing the gap.
There are many other factors I haven't mentioned here, but I believe I've covered the timeless, most important things for the new era of personal computing.
I'm a very visual person. when I was first getting into ML, I'd try to draw out every concept on pen and paper.
back then I couldn't vibe-code a visualization. but now you can!
here are my favorite ML visualizations I've been saving for a while. take them as inspo for the next complex topic you want to visualize 🧵
Unbelievable that SpaceX Starlink haven't been named or referenced directly in this article about them🤯
"UK government announced plans to boost train wi-fi speed… allowing them to connect to low-earth satellites, instead of mobile networks."
https://t.co/e6oND06myg
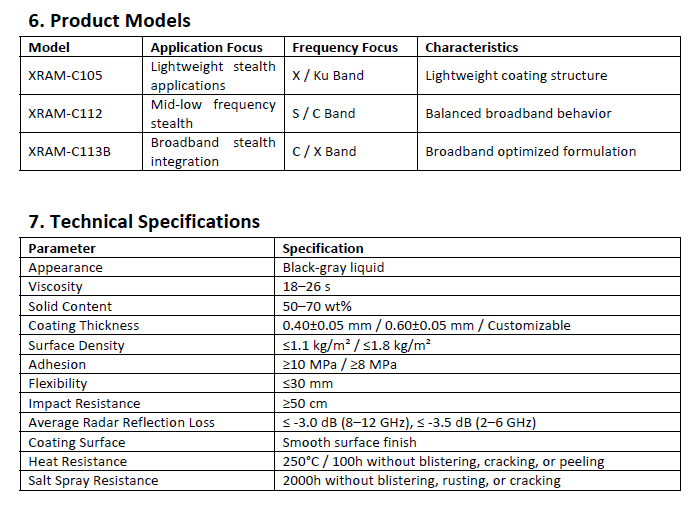
A Chinese company is now selling spray-on coating that makes drones harder for radar to detect, available in buckets and applied with a spray gun. What was once a classified military technology is now a commercial product sold by the kilogram.
https://t.co/UpXkLFFw6d
TIL that Škoda made a bicycle bell that can cut through ANC headphones.
Most ANC systems use adaptive filtering (like LMS) at a very basic level, it models the incoming noise and generate an anti-phase signal to cancel it. Works best for steady and predictable sounds.
Škoda's research found that around 750 - 780Hz ANC struggles a lot so they made their bell to target this particular frequency
they added irregular, transient dual tones that are hard to model in real time
this comes from a dual-resonator design : one tuned to ~750-780 Hz (ANC weak spot) using a cantilever tine, and another at higher frequencies (~2 KHz+) like a normal bell, so it’s not a single clean tone
So instead of being louder, it’s just… harder to cancel.
Pretty neat example of exploiting system limitations with pure analog design.
https://t.co/M2aH5Qfkcl
https://t.co/uXywdD01y4
I’m very excited to finally share the results of a passion project that has been on my mind for nearly a decade. You can find the pre-print below, but what follows is the saga of how this project came to be:
if you take the derivative of a video and timeshift the RGB channels separately, it makes an interesting effect
recorded live on my macbook without any video editing, coded with vanilla javascript
Spent Friday night testing @Apple ‘s new open-source ml-lito image-to-3D model running locally on Apple Silicon via Metal. No cloud, API, or uploads. Getting it working was harder than expected but got there. 👇👇👇@AppleEDU
https://t.co/D9DCX4vvwr
Apple just dropped a research paper called HeadsUp days before WWDC.
Trained on 10,000+ real faces to reconstruct a fully animatable 3D Gaussian Splat that you can rotate and light.
Excited to see Personas in visionOS 27.
@Ekaeoq You're very welcome. I've been on twitter many years and you're the first indie watch maker I've seen (stumbled across your account a couple of months ago). Work worth sharing 💯