Git tips nobody tells you but everyone needs 👇
- Use git bisect to find breaking commit
- Use git reflog to recover lost commits
- Use git stash with name for clarity
- Use git worktree for parallel branches
- Use git blame to find who wrote what
- Use git shortlog for contribution summary
- Use git archive to export without git history
- Use git cherry-pick for specific commits
- Use git rebase -i to clean commit history
- Use git hooks for pre-commit checks
Save this. 📌
Which tip saved you recently? 👇
Traefik is becoming a go-to replacement for Nginx.
Let's look at how it actually works.
The reason Traefik handles updates so efficiently comes down to its architecture. Unlike Nginx, which relies on a massive text configuration file, Traefik is modular.
It breaks the routing lifecycle into four distinct steps.
▶️ EntryPoints (The Listeners): This is the front door. They define the network interface and ports (usually 80 and 443). They don't route traffic; they simply listen for incoming packets and pass them on.
▶️ Routers (The Rules): This is where the logic happens. The Router analyzes the incoming request, checking the Host, Path, or Headers to see if it matches a specific rule. Crucially, this is also where Middleware is attached.
▶️ Middlewares (The Modifiers): This is the feature that saves you from Annotation Hell! These are interceptors that sit between the Router and your backend. They can modify the request (add headers, compress data) or enforce security (Basic Auth, Rate Limiting). You can chain multiple middlewares together to build complex logic without writing custom scripts.
▶️ Services (The Load Balancers): Finally, the Service handles the forwarding. It functions as an internal load balancer, distributing the traffic to your actual backend workloads (your Kubernetes Pods).
Configuration Types: Traefik splits its configuration into two categories:
1⃣ Static Configuration: These are the startup settings, such as defining EntryPoints (ports) and connecting to the Kubernetes API. These are set once when Traefik starts.
2⃣ Dynamic Configuration: These are your application definitions (Routers, Middlewares, and Services).
Traefik watches your infrastructure (the Provider). When you deploy a new container or change a routing rule, Traefik updates the Dynamic Configuration in memory. This allows it to apply changes immediately without needing to restart the process.
Request Flow:
Request → EntryPoint → Router (triggers Middleware) → Service → App
Before AWS existed, one company ran the servers for Twitter, LinkedIn, and Facebook's entire app ecosystem.
They owned Node.js, invented containers 8 years before Docker, and Peter Thiel even backed them.
Then something happened...
What Every Programmer Should Know About Memory:
• RAM
• CPU caches
• Optimization techniques
• Memory performance tools
This paper is still the best primer on how memory works.
By Ulrich Drepper from Red Hat. 100% Free.
Download it here:
https://t.co/UzUm7iAaUY
It’s crazy that sqlc exists and no one in the tech world seems to care.
It’s the best abstraction for data access with a relational database.
https://t.co/rshWzeqctj
The combination of sqlc and PGX is just insane.
With just annotations, you can generate batch code, COPY/CopyFrom commands, types for parameters and row results, and type safety using option types with the pgx/pgtype package.
Also, if you write your own wrapper code generator around sqlc’s output, or just use emit_pointer for the types, you’ve practically eliminated the need for DTO mapping, since every query will have its own types generated with it.
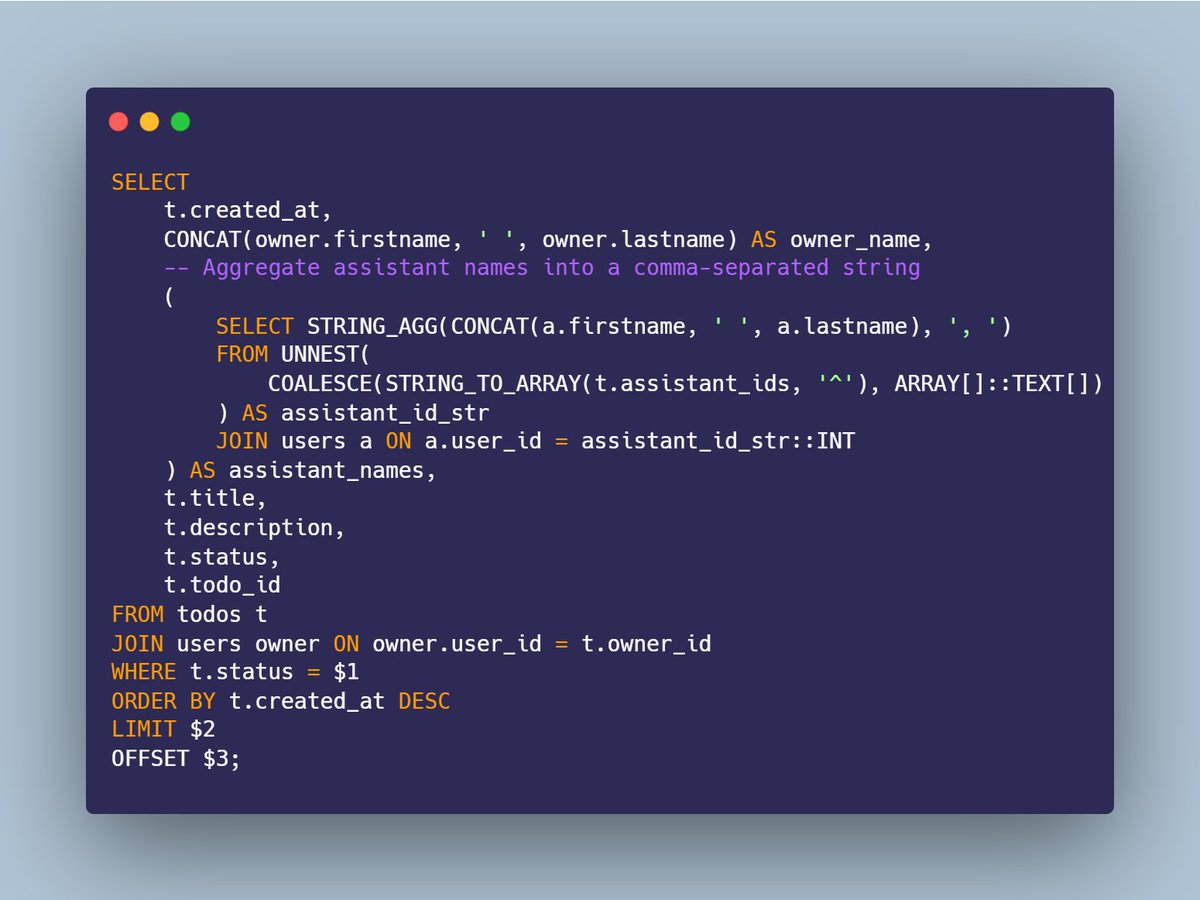
Let me show you a practical example of why this is so good.
Let’s say you want to build a Todo app with two tables: todos and users.
Now, suppose you want to allow collaboration by adding assistants or collaborators to a todo. The usual approach is to add another table, todo_assistants, which creates a one-to-many relationship between todos and assistants, using the user ID as a foreign key.
This means your code now requires an explicit transaction with two steps: inserting a todo, and then batch inserting the assistants.
If this already sounds annoying, think about the EDIT form you’ll need to build. How will you handle updates? Will you delete and reinsert all assistants, or perform fine-grained updates?
The thing is, if you look at the todo_assistants table which adds a lot of code complexity it’s really just {fk todo_id, fk user_id}.
What if you stored the assistant user IDs directly in the todos table as an array? Or, even as a string with a weird separator like $$?
This might seem confusing if you’re coming from the ORM world, like what’s the point of that? The point is, you can store the data you need in an efficient data structure, and then use PostgreSQL or MySQL’s native functions to manipulate and transform that data while querying.
You get the data you want, stored in the most efficient shape, and you get all the driver bindings and types generated with 100% type safety.
See the example below, we are querying the assistants names to show them in a list through splitting string, unnesting the array, joining with users and getting users information.
SQLc will generate a param struct, row struct, driver call and will prepare the sql statement implicitly and handle it's invalidation with no overhead.
You can basically do everything in one query using nested queries, common table expressions and most importantly json functions. No need to call multiple repositories to compose data and than map everything into DTOs.
PostgreSQL added Row-Level Security (RLS) in 2016.
But most teams still don’t turn it on.
Which is wild — because Postgres is already the backbone of:
• Multi-tenant SaaS
• Embedded analytics
• Mobile backends
It’s ACID-compliant. Rock-solid. Built for transactional workloads.
But with RLS, Postgres also becomes your access control layer.
Let’s say you’re building a multi-tenant CRM:
1. All customer data goes in one table
2. Each user should only see their own records
3. You add WHERE tenant_id = ? to every query
Then, someone forgets the clause.
Boom!!! Data gets leaked. Classic access control bug.
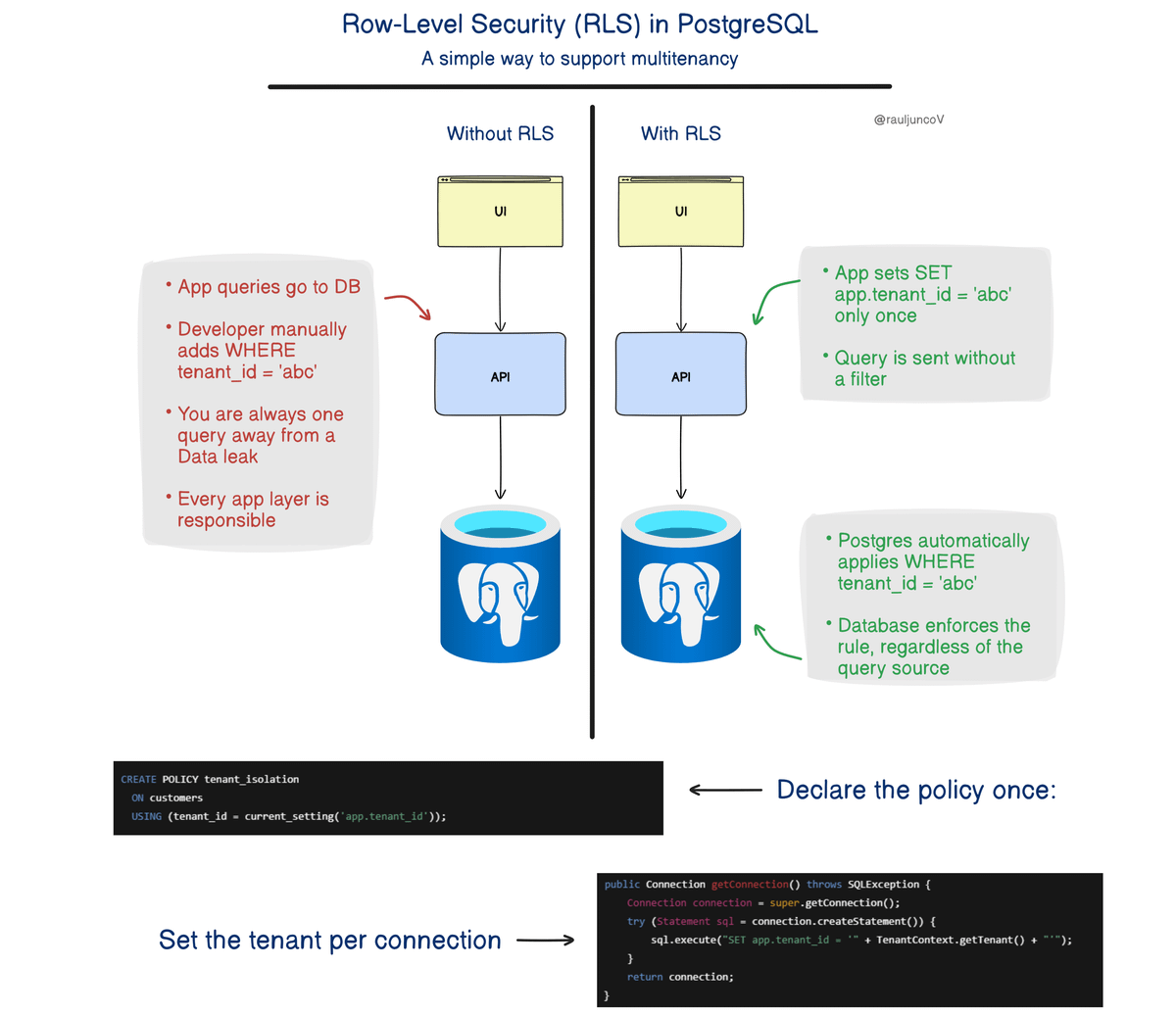
With RLS:
1. You declare the policy once.
2. Set the tenant per connection.
3. You run your queries without worrying about the tenant_id.
The database now enforces the rule. Even rogue queries are subject to database-enforced policies, reducing the risks of accidental data leaks.
This works for:
• SaaS backends
• Shared-data analytics
• Internal tools
Anywhere you need row-level access without rewriting queries.
If you rely solely on application-level access checks, consider shifting some of that responsibility to the database with RLS for added security and simplicity.
The database can do it better.
What’s the most surprising use of RLS you’ve seen in production?
A Go-based Wireshark for your Docker containers. It lets developers see all incoming and outgoing requests in their backend server to resolve production issues faster.
#golang#Devops
https://t.co/ooUhKxjise
💵 Coolify is highly profitable—at least in my opinion.
In February:
💰Gross income: $15,700
(Cloud ~$10.5k + donations ~$5.2k)
💸 Expenses: $2,800
🤑Net income (before tax): $12,900
(For comparison, my last 9-5 job paid $1,700/m)
I never took money out from the business, only with expenses, so I could keep taxes low at 9%.
My family and I live solely on donations 💜.
I rarely share my revenue, but if someone asks, I don't mind sharing it. If I share, I do it to motivate others. 💪
It's not millions or the impressive figures you often see on social media. This success didn't happen overnight or with minimal effort: like vibe-coded in 2 days. It is built over the years.
It's incredible that we, together with you, the users 💜, have built this as free and open-source software:
- without features hidden behind a paywall
- without venture capital
- without vendor lock-in
Lots of things are coming - stay tuned.