I think at some point you just need to give to @SchmidhuberAI. I have been scooped or ignored myself several times, so I know how it feels (not good!) and the tenacity at which he points to prior work that is unacknowledged in newer work in spite of opposition is remarkable.
If it weren't true recent work builds in some form on prior work, I just don't think that a researcher could muster the tenacity to keep posting. Truth generates power.
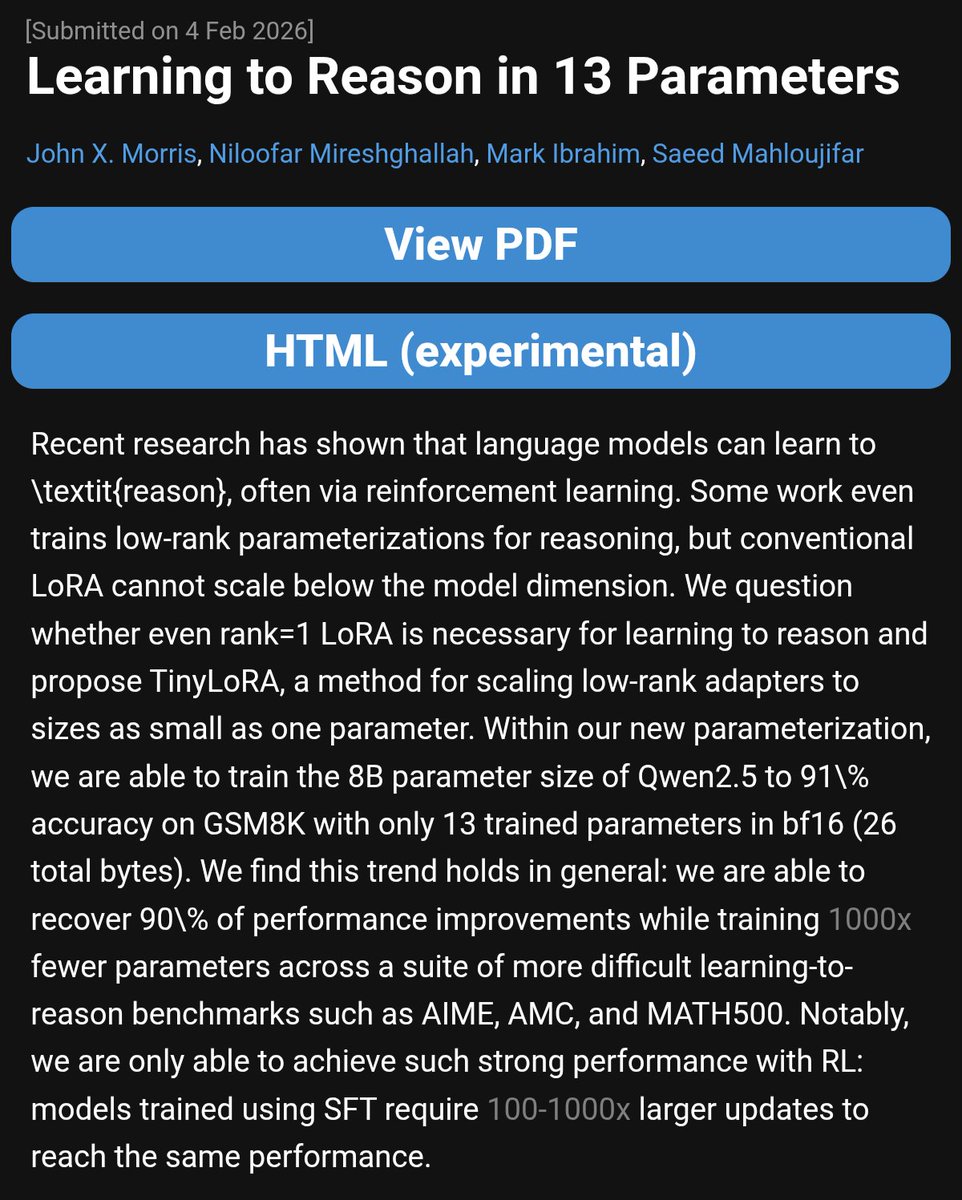
Papers like these are important for people competing in big reasoning competitions like AIMO or ARC-AGI.
The problem is that if one takes a closer look, there are some issues with the impressive claims:
- MATH is an outdated benchmark by now
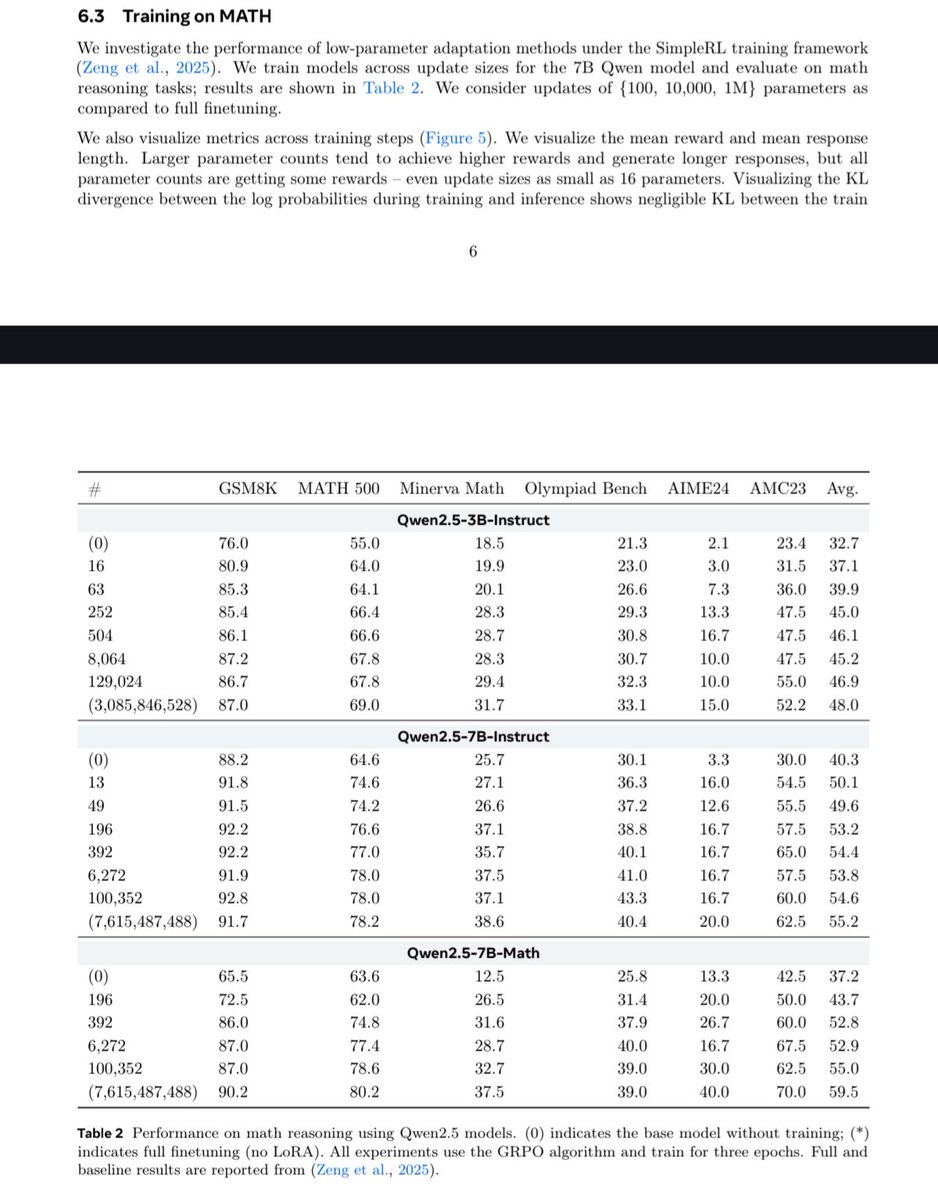
- the numbers don't add up. The last sentence on page 1 states "Qwen-2.5-7B-Instruct improves from 76% to 95% while training just 10,000 parameters". This conflicts with table 2, which in turn is also unclear, as the parameter count doesn't seem to match with the # column.
Asking an AI system for an opinion is never a good idea. I am withholding judgement in whether to be impressed - it really depends on a lot of details: how many mathematicians tried and failed to prove the problem before (impossible to quantify, but that would be a measure of difficulty), what techniques the proof that was found uses (is it merely an obvious application of a know theorem that mathematicians overlooked, or did it introduce a new solution technique), etc.
An expert in the field needs to answer this -- not me, and definitely not Grok. LLMs still don't know what they don't know.
This is way over the head of Grok, and it's "arguments" are very weak since they would apply to any other piece of autoformalized result.
Asking an AI system for an opinion is never a good idea. I am withholding judgement in whether to be impressed - it really depends on a lot of details: how many mathematicians tried and failed to prove the problem before (impossible to quantify, but that would be a measure of difficulty), what techniques the proof that was found uses (is it merely an obvious application of a know theorem that mathematicians overlooked, or did it introduce a new solution technique), etc.
An expert in the field needs to answer this -- not me, and definitely not Grok. LLMs still don't know what they don't know.
This is way over the head of Grok, and it's "arguments" are very weak since they would apply to any other piece of autoformalized result.
Is mathematics a game that is still worth playing in the long term?
The Twittersphere abounds with examples of what LLMs can do in math -- optimism is sky-high.
(I don't quite share that optimism since (open-source) LLMs do not even manage to solve the all "simple" unseen problems we have over at the AI Math Olympiad with the LB being stuck at 44/50.)
If that optimism pans out, even more maths will be created (rather than read) in the near future. While at first it will be exciting to watch conjectures fall, I am wondering what personal motivation will be left in such a full-automation scenario to get good and study mathematics.
"To the wider community interested in Erdős problems, we caution that even after correctly solving an Erdős problem, one should take care to ensure the statement accurately reflects what Erdős likely intended (this issue is discussed further below)."
This seems to be a very hard problem to solve -- and no, Lean (which is the usual answer when one points out tricky problems with natural-language mathematics) won't help here.
In a year, we will be living in a world of mathematical ... AI slop!
I'd hope things would be different, but where they are headed now, I fear many technical, and completely uninteresting results will flood the space. arXiv already had to stop accepting position papers, and the same will happen for technical, niche research papers rather soon. There will be an occasional jewel where AI genuinely helped (although just autoformalizing right now is not that exciting to the mainstream AI-sceptical mathematician), but most pebbles that fall out of LLMs won't be these jewels, they'll be cobblestones.
Math abundance -- or math AI slop?
Other domains already were slop-ified: after the initial "wow" effect is gone, the limits of AI systems quickly emergence, whether it the latest Sora model not being useful to generate videos that are very long, nor to the best vibe-coding models that can generate frontend and backup of website -wow, incredible!- but wrestling the website into your specific requirements then turns out to be much harder.
I predict that in a year we'll have the equivalent for math: lots of very technical, very uninteresting results.
Sure, some tools will turn out to be useful -- but the abundance we'll have isn't a positive one.
There isn't word that is needed here to capture this, and I used the "queue" in one of my (still fledging) blog posts https://t.co/X6bkG53TEF for this, as the ideas that are _up there_. Should people be rewarded from plucking ideas from the queue? It's debatable with both good pros and cons.
1/ Having a strong Lean engine is definitely a nice thing to have -- but there are limits to what is natural to do in Lean (or any formal systems).
I'm reminded here of the nice example that Patrick Massot mentioned in his talk about the concept of ... limits in calculus [1] :)
If you want to formalize all possible variants of each type of limit at a point of a function in a "naive" way, there are many definitions to state: of the limit at a point with the limit equaling a number, of the limit at a point with that point remove equaling infinity, etc. If you count them, it seems to amount to actually 256 (!) definitions (see the 45m30s mark of the video).
There are two ways out of this: 1) In practice, no one gets taught all 256 definitions but rather one teaches the "abstract generator" behind the definition. 2) One abstract all these away by using ultrafilters, and then just teaches limits in the setting of ultrafilters.
Both ways then also help to reduce the sprawling number of plumbing lemmas (like composition of two lemmas) that one otherwise would help to prove about limits (which are 4096 according to the video, which seems plausible).
Both solutions are possible execute in Lean, but are awkward to perform.
[1] https://t.co/LAKrInZ2Jt
@mathematics_inc 3/ All of this is not to say that "hitting math with technology" is the wrong approach -- but Lean is only *one* toolbox one needs to use, and automation within natural language will also need to happen to close the iteration loop for mathematicians.
2/ Aside from this example about limits that highlights one problematic instance with formal mathematics, there are also other instances where Lean isn't the best choice; here are just three examples out of many:
- Keeping proofs concise is easy in natural language, but for Lean it will likely be hard to develop a layer that summarizes things to make proofs more easily readable;
- Conjecturing is probably best done in natural language, to not get bogged down with the technical overhead associated to Lean;
- No flexibility: HoTT was driven forward by a deeper analysis of the concept of equality. Handling this in natural language is much more flexible than a formal system. Even if you conceptually are rooted in ZFC, which is more clunky in this regards than HoTT, in natural language you can deal with to things being equal on "a higher level" according to whatever theory you're developing, even if these things are not equal as sets. If you do mathematics formally, you're stuck with whatever foundation was used, which changes how easily you can express equality.
@deredleritt3r Hi, one of the two authors here. Trust me, we did get that memo. But it was not relevant to our paper. This paper seems to have been more controversial than intended, but only because most people glossed over the finer details. Your somewhat emotional post also left me with that impression.
1) In the abstract we said "contrary to optimism about LLMs problem-solving abilities" and _not_ "contrary to LLMs that solve IMO problems," which is what you imply.
The LLMs that we tested all had rather good problem-solving abilities and IMO-level problems are within their reach (particularly if the IMO problems are in the training data), even though those specific LLMs failed to do well on IMO25 (whose problems were likely not in the training data, al comparing to those problems would actually be unfair).
2) Also, you seem to not have taken a look at our "Limitations" section where we clearly anticipated that LLMs will solve our problem - as GPT 5 Pro did some time after our release.
Once it did, many people seemed to have a reaction of the type "take that, proved ya wrong!" but in our paper we were clear that we fully expected that and we would rather have only been surprised if that would not have been the case.
Functionally there is not a big difference. But there is one in terms of stability, since arXiv is essentially a non-profit, and Reddit is a business.
I'd like to have a record of comments indefinitely and we saw with https://t.co/dxXEHztHtK how annoying it can be when a business (Meta in that case) pulls the plug. We now have a million clones of the original site, but none as good as the original, which is annoying.
arXiv helps as as a trusted source that stood the test of time.
Definitely agree that having a preprint hosting service is necessary but not sufficient for a thriving open scientific environment.
My utopic vision would be one of full integration, where AIMOx, for some integer x, is hosted on a community-supported platform, and one could directly link between arXiv preprints like https://t.co/6Q9W0XHFCL and AIMOx, knowing that there is a clear organizational structure that is not influenced by ever-changing business cycles. It's unlikely to happen soon though :D
One more nail in the coffin for a broken reviewing system. Who knows how many people silently used this backdoor to see who gave them bad scores -> potentially career-damaging.
It would be much better to have a comment section in arXiv, this would solve 80% of the existing problems: only people that are actually interested in the paper would read it, there would be no arbitrary cutoff who made it or not and no useless scores (the infamous NeurIPS experiment demonstrated -unsurprisingly- a large degree of subjectivity https://t.co/PC1asR6RtH), nasty reviews would occur less frequently if your name is attached, there is no possibility to have an ongoing dialogue that reflect what the community thinks of the paper since nothing can be done after the rebuttal phase which is artificial and sometimes a longer dialogue would beneficial (who remember the "Understanding deep learning requires rethinking generalization" paper
? https://t.co/1GoMIqHied ), etc etc
2023: It's hard to devise an LLM that solves a math problem.
2025: It's hard to devise a math problem that stumps and LLM.
(...this in the context of competitive math questions, but we'll also get to research-level math soon)
AIMO3 is full of surprises: week 2 (out of 21) just concluded. After a race in the first week that had us both biting our nails to see how quickly the leaderboard is rising and cheering for the progress of open-weight LLMs, the leaderboard suddenly ground to halt.