uv가 이렇게 빨라진 이유
- Python 패키지 관리자 uv는 pip보다 10배 이상 빠른 설치 속도를 보이며, 이는 단순히 Rust로 작성되었기 때문이 아니라 설계상의 선택에서 비롯됨
- 속도를 가능하게 한 핵심은 정적 메타데이터 표준(PEP 518, 517, 621, 658) 으로, 코드 실…
https://t.co/Ykssb9P7FS
이 연구는 LLM이 흔히 '인공지능'으로 불리지만, 인간의 인식(cognition)과 근본적으로 다른 인식론적(epistemological) 특성을 가진다는 점을 얘기하고 있음.
> Epistemological Fault Lines Between Human and Artificial Intelligence
겉으로는 인간과 비슷한 출력을 내지만, 판단 과정의 구조적 차이가 크다고 정리함.
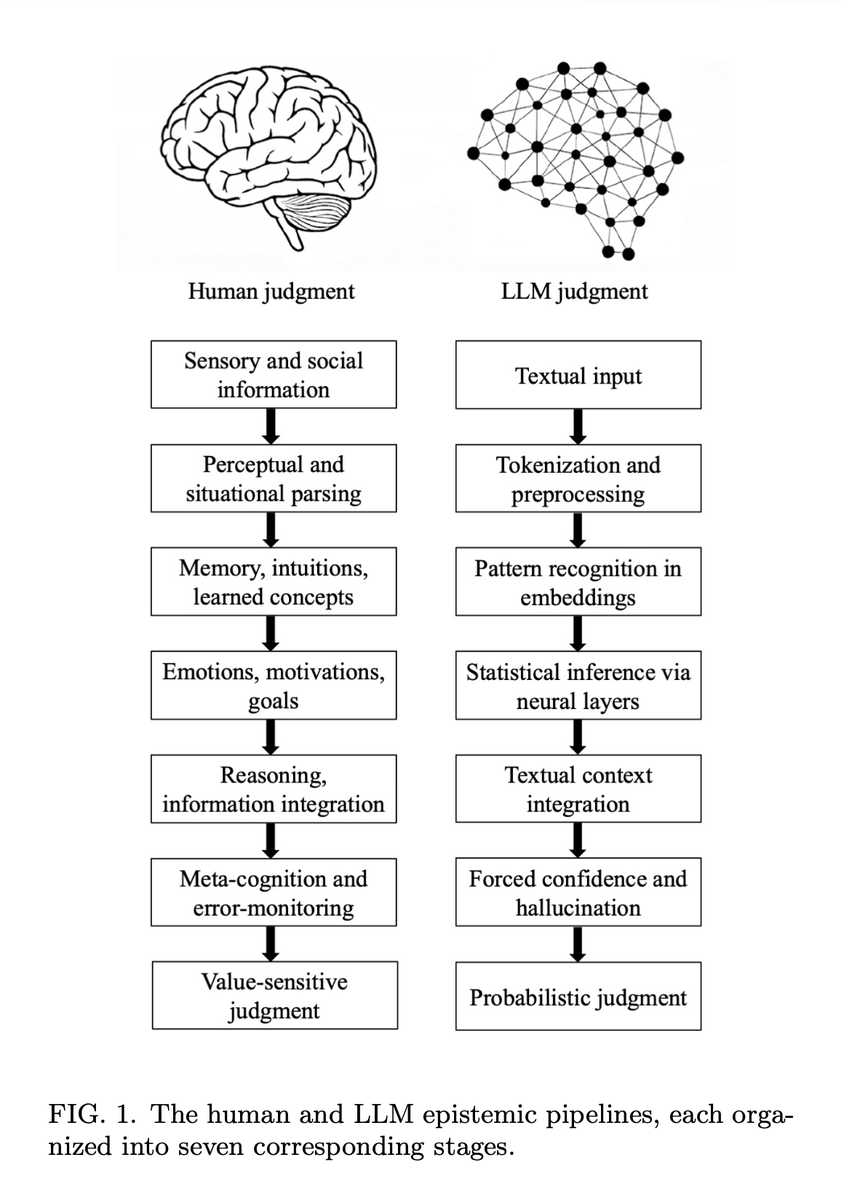
인간과 LLM의 판단 형성 과정을 일곱 가지 인식론적 단계에서 비교해보자. 이 과정에서 인간과 LLM이 근본적으로 다른 지점, 즉 일곱 가지 단층선을 강조함.
- 접지 단층 (Grounding fault):
인간은 판단을 지각적, 신체적, 사회적 경험에 기반하지만, LLM은 텍스트만으로 시작해 기호로부터 의미를 간접적으로 재구성한다.
- 구문 분석 단층 (Parsing fault):
인간은 상황을 통합된 지각과 개념 과정으로 분석하나, LLM은 구조적으로 편리하지만 의미적으로 얕은 표현을 만드는 기계적 토큰화에 의존한다.
- 경험 단층 (Experience fault):
인간은 에피소드 기억, 직관적 물리학·심리학, 학습된 개념을 활용하나, LLM은 임베딩에 인코딩된 통계적 연관성에만 의지한다.
- 동기 단층 (Motivation fault):
인간의 판단은 감정, 목표, 가치, 진화적으로 형성된 동기에 이끌리지만, LLM은 내재적 선호나 목적, 감정적 의미가 없다.
- 인과성 단층 (Causality fault):
인간은 인과 모델, 가정법, 원칙적 평가를 사용해 추론하나, LLM은 표면적 상관관계에 의존해 텍스트 맥락을 통합하며 인과 설명을 구축하지 않는다.
- 메타인지 단층 (Metacognitive fault):
인간은 불확실성을 모니터링하고 오류를 감지하며 판단을 유보할 수 있지만, LLM은 메타인지를 결여해 항상 출력을 생성해야 하므로 환각이 구조적으로 피할 수 없다.
- 가치 단층 (Value fault):
인간의 판단은 정체성, 도덕성, 현실적 이해관계를 반영하나, LLM의 "판단"은 내재적 가치 평가나 책임 없이 확률적 다음 토큰 예측에 불과하다.
이러한 단층선에도 불구하고, 인간은 유창하고 자신감 있는 언어가 신뢰성 편향을 일으키기 때문에 LLM 출력을 체계적으로 과도하게 믿는다.
이로 인해 구조적 상태인 에피스테미아(Epistemia)가 발생한다.. 언어적 그럴듯함이 인식론적 평가를 대체해, 실제로 알지 못하면서 아는 듯한 느낌을 만들어낸다.
당신의 첫번째 ChatGPT 앱을 만드는 방법
- OpenAI가 발표한 ChatGPT Apps는 개발자가 자신의 앱을 ChatGPT 대화 안에 직접 임베드할 수 있게 하며, 8억 명이 넘는 주간 활성 사용자를 새로운 배포 채널로 활용할 수 있음
- ChatGPT는 기존 텍스트 응답을 넘어 UI 컴포…
https://t.co/jk6x0VYLTa
Django 6 릴리즈
- 웹 프레임워크 Django의 6.0 버전이 공개되어 Python 3.12 이상을 지원하고, 보안·템플릿·비동기 기능이 대폭 강화됨
- Content Security Policy(CSP) 가 기본 내장되어 XSS 등 콘텐츠 주입 공격 방어를 위한 정책 설정이 가능함
- Template Partia…
https://t.co/ocxRAziVVj
두 사회학자가 박사 논문을 기초로 저술한 두 권의 책. 들여다보면, 사실상 각각 1980년대의 올림픽 스타디움과 2000/10년대의 광화문 광장을 가로지르는 87년 이후의 극장 국가 2부작 같아 보이기도.
'실증'과 '논증'이 촘촘해서인지, 사회학자들의 문화연구 저술은 계속 찾아보게 된다.
파이썬은 데이터 사이언스에 적합한 언어가 아니다
- 데이터 분석·시각화·요약 같은 비-딥러닝 데이터 작업에서 Python은 기능은 충분하지만 사용 경험이 복잡하고 비효율적으로 흐르기 쉬움
- 연구실 사례 전반에서 R보다 Python이 단순한 그래프 변환·통계 계산에도 …
https://t.co/smMp9veEpx
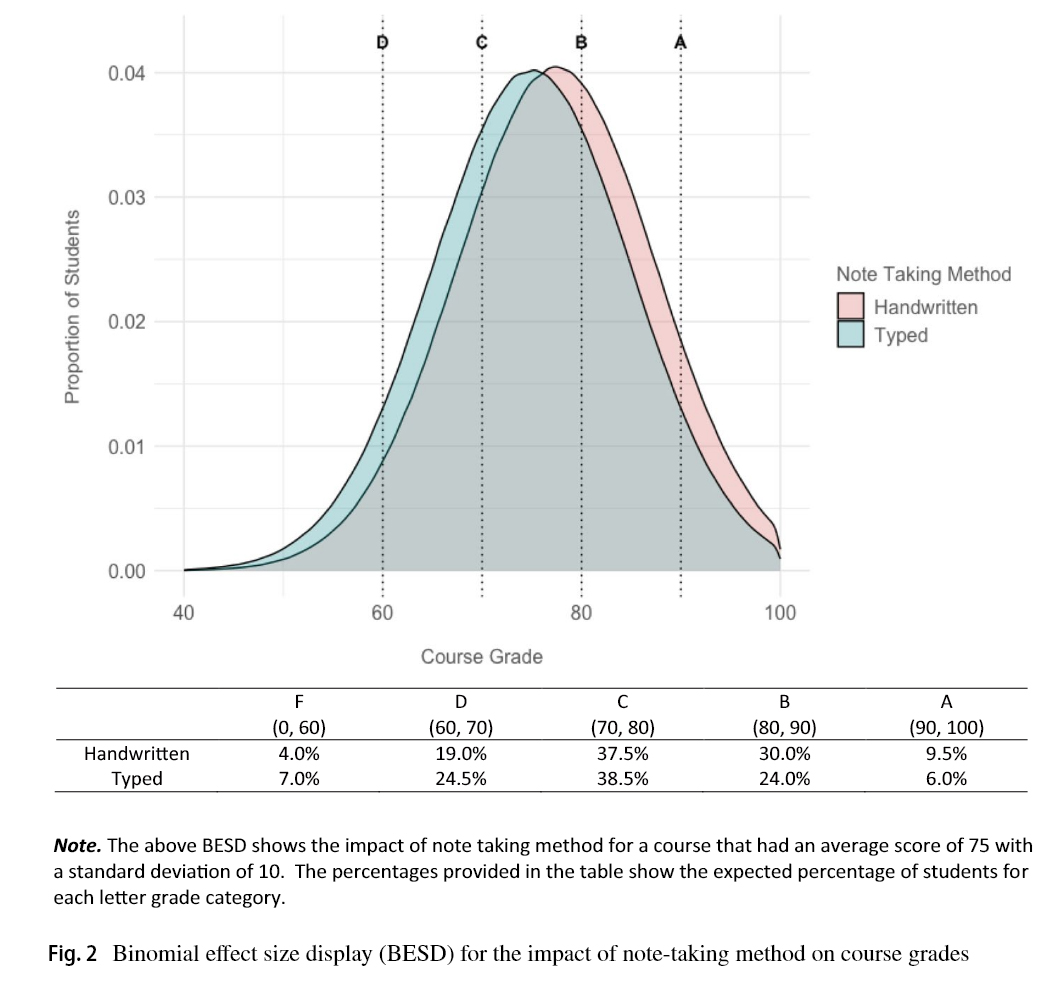
It's time to remove laptops from classrooms.
24 experiments: Students learn more and get better grades after taking notes by hand than typing. It's not just because they're less distracted—writing enables deeper processing and more images.
The pen is mightier than the keyboard.
개별 개발자가 극복할 방향도 미묘하게 좀 이상함.
개발자도 수학이나 알고리즘 같은걸 잘해야 한다는게 완전 틀린말은 아닌데, 인간과 AI 가 어려워하는 작업은 서로 좀 다른것 같다.
예를들어 sonnet3.5 초기버전 시절에도 프로덕션 코드에도 여기 Dijkstra 로 최단거리 구현해줘 같은건 잘됐다.
PHP 8.5의 새로운 기능들
- PHP 8.5는 파이프 연산자, clone with, 새 URI 파서 등 여러 기능을 포함한 주요 업데이트 버전
- 파이프 연산자는 함수 호출 체인을 단순화해 가독성과 유지보수성을 높임
- Clone with 기능은 객체 복제 시 속성 값을 동시에 변경할 수 있…
https://t.co/7Zkmx22o5q
Olmo 3: 오픈소스 AI를 선도하기 위한 모델 플로우의 새로운 경로
- Olmo 3는 모델의 최종 결과뿐 아니라 전체 개발 과정(model flow) 을 공개해, 데이터·코드·체크포인트까지 완전한 추적 가능성을 제공
- 7B와 32B 파라미터 규모의 Base, Think, Instruct, RL Zero 네…
https://t.co/0KX7uJ3SXG
LLM 토큰을 10배나 100배 쓰는 건 쉽지만, 그 결과로 10배나 100배의 생산성을 달성하기는 어렵다. 실제로 생산성을 높일 방법에 대해 고민하다가 투기적 트리 탐색(speculative tree search)이라는 패턴을 생각해봤다: https://t.co/nRoAN4EvuM
최근 TOON이라는, JSON을 대체해 LLM의 토큰을 최소화한다는 구조적 데이터 표현 방식이 핫하다. (YAML과 유사한 형식)
하지만 주장대로 토큰을 더 적게 먹는게 맞을까?
다음의 JSON 데이터를 몇가지 데이터 형식으로 바꿔 GPT 토크나이저로 돌려보면 아래와 같이 나온다.
—
{
"order":{
"id":7,
"items":
[
["A12",2],
["B55",1]
]
}
}
—
JSON: 36토큰
JSON(공백제거): 22토큰 👈
CSV: 18토큰
TOON: 32토큰
YAML: 29토큰
—
사용처에 따라 TOON이 좋은 대안일 수 있지만, 우리 사례에 맞을지 테스트는 한 번 해봐야.. ☺️
@: 한국에서는 잘 알려지지 않은 느낌이지만, 아베는 대외적으로 인도-태평양 구상을 창시하여 미국의 대아시아 전략의 판을 깔아준 사람이다. 아베 골프채 선물은 그런 의미에서 다카이치 정부가 이를 계승하겠다는 의미일 것이고. 아베의 구상은 오바마-트럼프 교체에도 큰 흔들림이 없었으니.