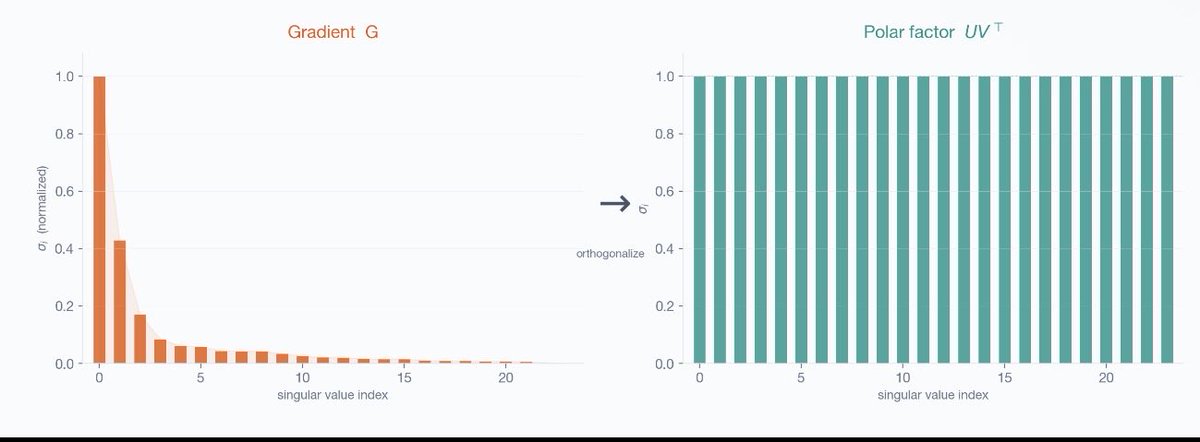
Why does Muon beat Adam for training quantized networks?
It comes down to what each optimizer treats as "distance" in weight space.
Adam treats a weight matrix as a flat vector of numbers. Muon treats it as a linear map — and measures change by how much the input-output mapping moved.
gradient G has SVD G = U Sigma V^T. Muon's update is just U V^T. keep the directions, throw away the magnitudes
Please check out Gradus, a micro-learning app! Gradus turns PhD-level information into digestible content. It imposes a structure on LLM outputs, yielding friendly curriculum, and democratizing eduction in the same way ChatGPT has. Check it out below! @sama
Please notice me 😭
https://t.co/scRLpQ9B0m
@__tinygrad__ Llama.cpp is a very weak baseline. LMStudio I assume is mlx? It's better but I get 220 tok/s on Qwen3.5-0.8B-MLX-8bit with https://t.co/s6ovysiKqn on m1 max. The branch and command from that pr gets 145 on the same machine but the output is garbage
1/ Recently I've been obsessed with the idea of splitting the matmul computation on separate hardware units due to the tiling nature of the operation. My idea was simple: we have GPU, MXU, ANE, NEON, why are we utilizing only the first one?