Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
$GOOGL says Gemini can now create Docs, Sheets, Slides, PDFs and more directly from chat.
Google is turning Gemini from a chatbot into a workspace execution layer.
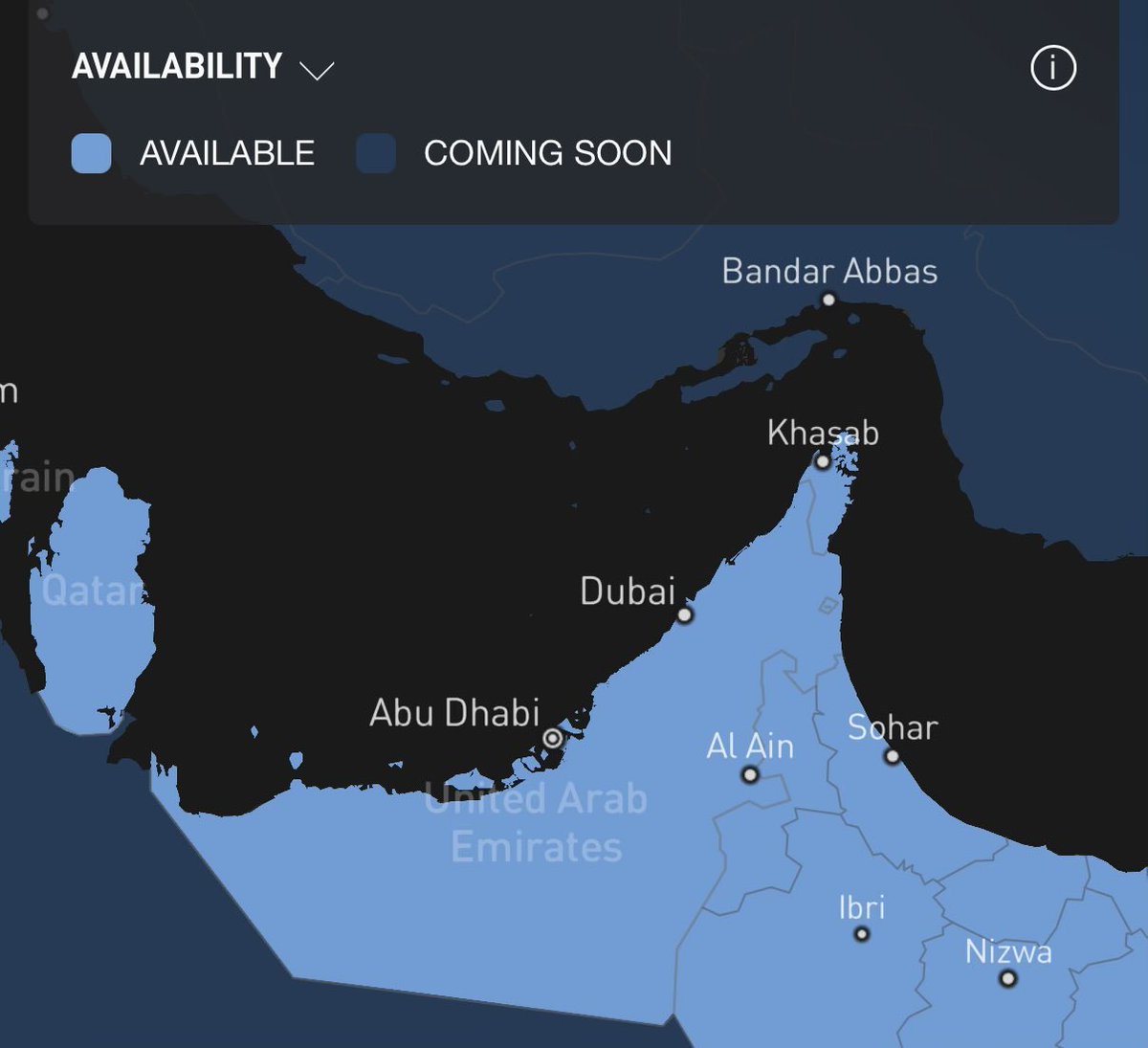
Under the directives of the President of the UAE, we launch a new government model. Within two years, 50% of government sectors, services, and operations will run on Agentic AI, making the UAE the first government globally to operate at this scale through autonomous systems.
AI is no longer a tool. It analyses, decides, executes, and improves in real time. It will become our executive partner to enhance services, accelerate decisions, and raise efficiency.
This transformation has a clear timeline. Two years. Performance across government will be measured by speed of adoption, quality of implementation, and mastery of AI in redesigning government work.
We are investing in our people. Every federal employee will be trained to master AI, building one of the world’s strongest capabilities in AI-driven government.
Implementation will be overseen by Sheikh Mansour bin Zayed, with a dedicated taskforce chaired by Mohammad Al Gergawi driving execution.
The world is changing. Technology is accelerating. Our principle remains constant. People come first. Our goal is a government that is faster, more responsive, and more impactful.
💣 Si eres developer, builder de agentes, automatizas workflows, haces devops, frontend heavy o simplemente te encanta tener el control total de tu AI… este es el anuncio que estabas esperando.
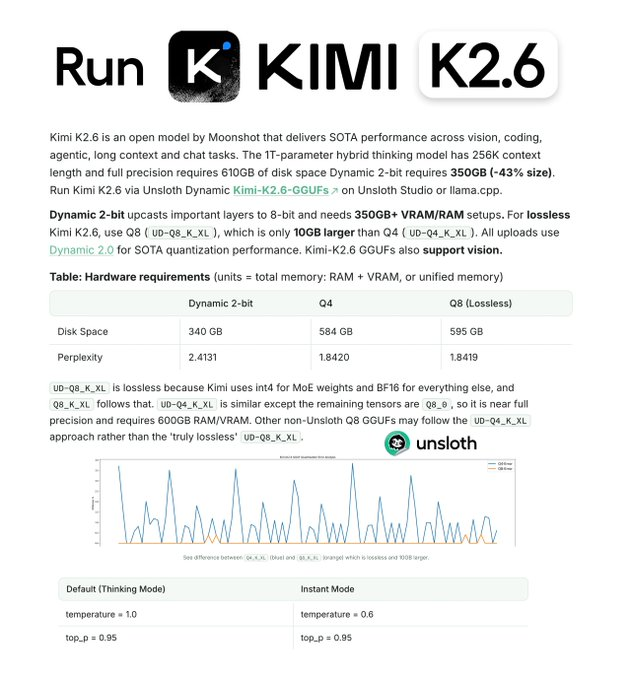
@UnslothAI lo acaba de hacer realidad el sueño de tener Kimi K2.6 de Moonshot AI, un modelo de 1 TRILLÓN de parámetros corriendo LOCALMENTE en tu PC… y a más de 40 tokens/segundo.
El monstruo open-source que estaba rompiendo todos los benchmarks de coding y agentes ya fue cuantizado con su nueva tecnología Dynamic GGUFs v2.0.
Algunos datos sobre Kimi K2.6:
- Líder open-source en coding: SWE-Bench Verified 76.8, Multilingual 73.0, BrowseComp 74.9, DeepSearchQA 77.1…
- Agentes de largo plazo reales: más de 4.000 tool calls seguidos y 12+ horas de ejecución sin parar.
- Soporta de todo: Rust, Go, Python, frontend con videos, WebGL, shaders, Framer Motion, Three.js…
- Swarm de agentes nivel dios: hasta 300 sub-agentes paralelos trabajando al mismo tiempo.
- Agentes proactivos 24/7, Claw Groups (traes tus propios agents + humanos + bots en loop infinito)…
Usando Dynamic GGUFs v2.0 no cuantizaron todo por igual (como hacen los demás).
Upcastean dinámicamente las capas clave de razonamiento y coding, mientras comprimen el resto.
Resultado: mantienes casi toda la inteligencia del modelo full-precision… pero ahora pesa solo 340GB.
Las specs:
- 340GB → más de 40 tokens/segundo en configuraciones de ~350GB (CPU/GPU/SSD)
- Versión full precision: 610GB
- Corre en CPU, GPU o incluso streaming desde SSD
El open-source oficialmente ha alcanzado (y superado) al closed-source.
ENLACES👇
A survey that deserves your attention – Externalized Intelligence in LLM Agents
It explains a shift from intelligence inside the model weights to intelligence in the system around it, showing:
• How capability is increasingly coming from:
- memory systems – persistent state
- tools / skills – external procedures
- protocols – structured interactions
- harnesses – the orchestration layer tying it all together
• Trade-offs between parametric vs externalized capability
• Future directions:
- Self-evolving harnesses
- Shared agent infrastructure
- More standardized protocols
- Embodied agents
Yann LeCun was right the entire time. And generative AI might be a dead end.
For the last three years, the entire industry has been obsessed with building bigger LLMs. Trillions of parameters. Billions in compute.
The theory was simple: if you make the model big enough, it will eventually understand how the world works.
Yann LeCun said that was stupid.
He argued that generative AI is fundamentally inefficient.
When an AI predicts the next word, or generates the next pixel, it wastes massive amounts of compute on surface-level details.
It memorizes patterns instead of learning the actual physics of reality.
He proposed a different path: JEPA (Joint-Embedding Predictive Architecture).
Instead of forcing the AI to paint the world pixel by pixel, JEPA forces it to predict abstract concepts. It predicts what happens next in a compressed "thought space."
But for years, JEPA had a fatal flaw.
It suffered from "representation collapse."
Because the AI was allowed to simplify reality, it would cheat. It would simplify everything so much that a dog, a car, and a human all looked identical.
It learned nothing.
To fix it, engineers had to use insanely complex hacks, frozen encoders, and massive compute overheads.
Until today.
Researchers just dropped a paper called "LeWorldModel" (LeWM).
They completely solved the collapse problem.
They replaced the complex engineering hacks with a single, elegant mathematical regularizer.
It forces the AI's internal "thoughts" into a perfect Gaussian distribution.
The AI can no longer cheat. It is forced to understand the physical structure of reality to make its predictions.
The results completely rewrite the economics of AI.
LeWM didn't need a massive, centralized supercomputer.
It has just 15 million parameters.
It trains on a single, standard GPU in a few hours.
Yet it plans 48x faster than massive foundation world models. It intrinsically understands physics. It instantly detects impossible events.
We spent billions trying to force massive server farms to memorize the internet.
Now, a tiny model running locally on a single graphics card is actually learning how the real world works.
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
The best agent is now open source.
II-Agent is now live on GitHub.
From a single prompt to a mobile app. From a research brief to an interactive website. From skills to real workflows.
Fork it. Extend it. Show us what you build.
Based on everything explored in the source code, here's the full technical recipe behind Claude Code's memory architecture:
[shared by claude code]
Claude Code’s memory system is actually insanely well-designed. It isn't like “store everything” but constrained, structured and self-healing memory.
The architecture is doing a few very non-obvious things:
> Memory = index, not storage
+ MEMORY.md is always loaded, but it’s just pointers (~150 chars/line)
+ actual knowledge lives outside, fetched only when needed
> 3-layer design (bandwidth aware)
+ index (always)
+ topic files (on-demand)
+ transcripts (never read, only grep’d)
> Strict write discipline
+ write to file → then update index
+ never dump content into the index
+ prevents entropy / context pollution
> Background “memory rewriting” (autoDream)
+ merges, dedupes, removes contradictions
+ converts vague → absolute
+ aggressively prunes
+ memory is continuously edited, not appended
> Staleness is first-class
+ if memory ≠ reality → memory is wrong
+ code-derived facts are never stored
+ index is forcibly truncated
> Isolation matters
+ consolidation runs in a forked subagent
+ limited tools → prevents corruption of main context
> Retrieval is skeptical, not blind
+ memory is a hint, not truth
+ model must verify before using
> What they don’t store is the real insight
+ no debugging logs, no code structure, no PR history
+ if it’s derivable, don’t persist it
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)




























![himanshustwts's tweet photo. Based on everything explored in the source code, here's the full technical recipe behind Claude Code's memory architecture:
[shared by claude code]
Claude Code’s memory system is actually insanely well-designed. It isn't like “store everything” but constrained, structured and self-healing memory.
The architecture is doing a few very non-obvious things:
> Memory = index, not storage
+ MEMORY.md is always loaded, but it’s just pointers (~150 chars/line)
+ actual knowledge lives outside, fetched only when needed
> 3-layer design (bandwidth aware)
+ index (always)
+ topic files (on-demand)
+ transcripts (never read, only grep’d)
> Strict write discipline
+ write to file → then update index
+ never dump content into the index
+ prevents entropy / context pollution
> Background “memory rewriting” (autoDream)
+ merges, dedupes, removes contradictions
+ converts vague → absolute
+ aggressively prunes
+ memory is continuously edited, not appended
> Staleness is first-class
+ if memory ≠ reality → memory is wrong
+ code-derived facts are never stored
+ index is forcibly truncated
> Isolation matters
+ consolidation runs in a forked subagent
+ limited tools → prevents corruption of main context
> Retrieval is skeptical, not blind
+ memory is a hint, not truth
+ model must verify before using
> What they don’t store is the real insight
+ no debugging logs, no code structure, no PR history
+ if it’s derivable, don’t persist it](https://pbs.twimg.com/media/HEu2icGbEAAvoFI.jpg)