🚨 Excited to announce that RGD has been accepted to #ACL2026 Main!
Routing with Generated Data (RGD) is a new LLM routing paradigm where routers estimate skills of models using generated data, without ground-truth labels.
We further introduce CASCAL, a new router for RGD that discovers niche skills via consensus voting + hierarchical clustering, with no ground truth needed.
🧵👇
VLMs can easily get distracted by unrelated cultural cues. Happy to present our work on this soon at #CVPR2026🥳
Working on multilingual VLMs? Consider using our benchmark:
📜https://t.co/UfXwf9DepP
🤗https://t.co/8J9L8zrjZ5
Amazing work by @patrickamadeus_ and colleagues!
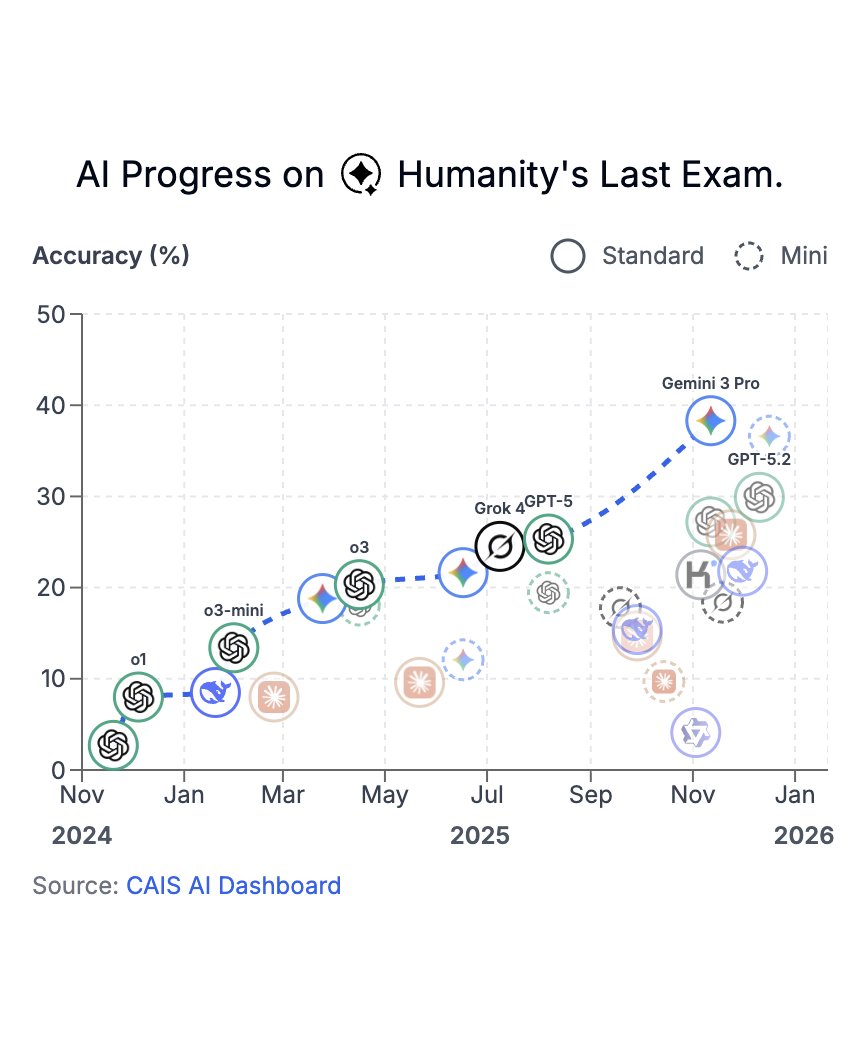
Last week, Humanity’s Last Exam was published in @Nature.
In just over a year, model scores on HLE have risen from under 5% to nearly 40%.
Thank you to @scale_AI and the 1000+ HLE co-authors for helping policymakers and the public track these rapid advances in AI capabilities.
Last week, Humanity’s Last Exam was published in @Nature.
In just over a year, model scores on HLE have risen from under 5% to nearly 40%.
Thank you to @scale_AI and the 1000+ HLE co-authors for helping policymakers and the public track these rapid advances in AI capabilities.
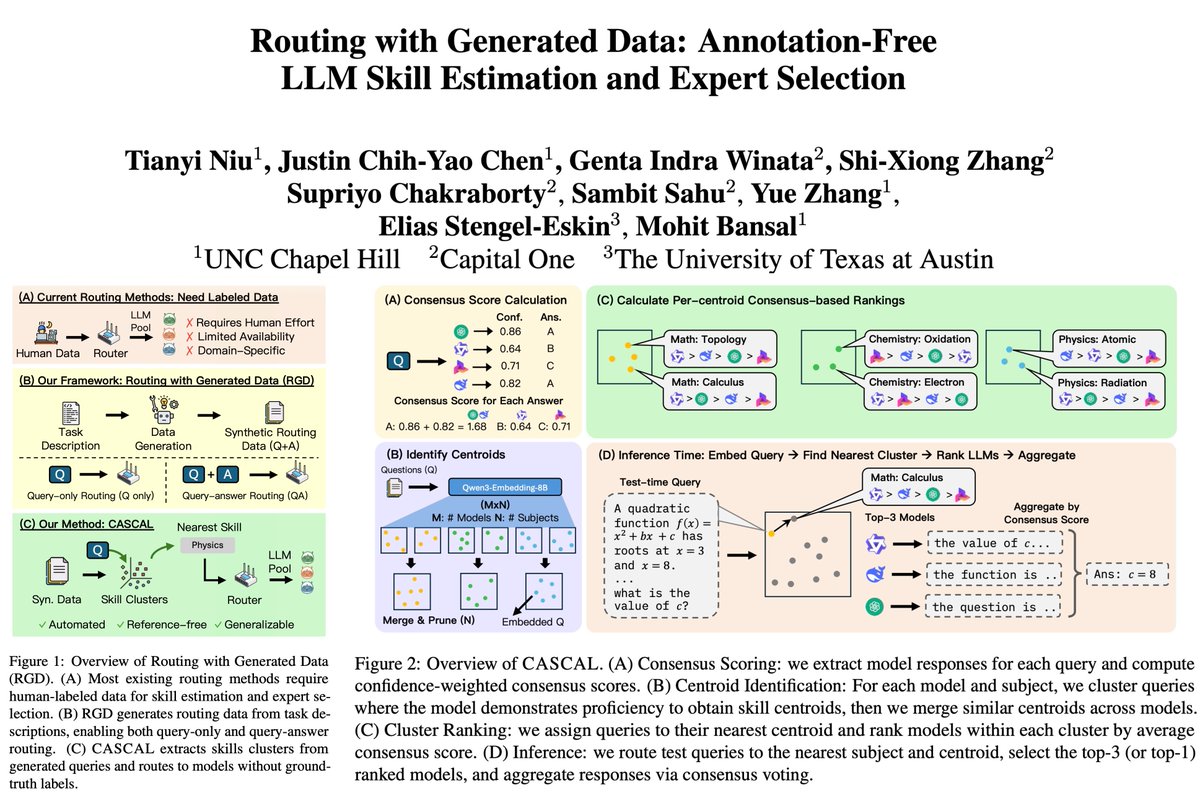
📢 Introducing Routing with Generated Data (RGD), a new setting for annotation-free LLM routing. We study how routers can be trained without any ground-truth labels. We also introduce CASCAL, a novel label-free LLM router that identifies niche skills using consensus-voting and hierarchical clustering.
➡️ Most LLM routers assume access to labeled, in-domain data to estimate model skills (query-answer routers). However, user distributions are unknown and labels are expensive or unavailable, highlighting the need for routers that work without labels.
➡️ We introduce Routing with Generated Data (RGD): routers are trained only on Q&A data generated from task descriptions, without human annotation. We experiment with various LLM generators of different strengths (Gemini-2.5-Flash, Qwen-3-32B, Exaone-3.5-7.8B).
➡️ CASCAL outperforms other query-answer and query-only routers across diverse datasets (MMLU-Pro, SuperGPQA, MedMCQA, BigBench Extra Hard), and is more robust to weaker generators.
💡Have you ever wondered whether vision–language models can be easily tricked by adding landmarks or flags to an image?
In the spirit of the holidays🎄, we show that VLMs can indeed be easily confused like "Confused Tourists" ✈️: their performance drops significantly when such image perturbations are applied.
🔎 Check out "VLMs are Confused Tourists" ✈️ here https://t.co/tANZQvjlXF
#vision #nlproc #robustness
Craving holiday-themed paper? Say less🎄
Turns out, Vision Language Models are Confused Tourists ✈️😵💫
We show that adversarially induced cultural scenes significantly impair VLM cultural comprehension and trigger potential bias
#NLProc#multimodal#robustness
/thread 🧵(1/8)
Craving holiday-themed paper? Say less🎄
Turns out, Vision Language Models are Confused Tourists ✈️😵💫
We show that adversarially induced cultural scenes significantly impair VLM cultural comprehension and trigger potential bias
#NLProc#multimodal#robustness
/thread 🧵(1/8)