📢Our January issue is now live! Highlights include a model for predicting life outcomes, a Perspective on the advantages of language models for quantum simulation, and a protein language model for signal peptide prediction.
👉https://t.co/IWoHZnLVkk
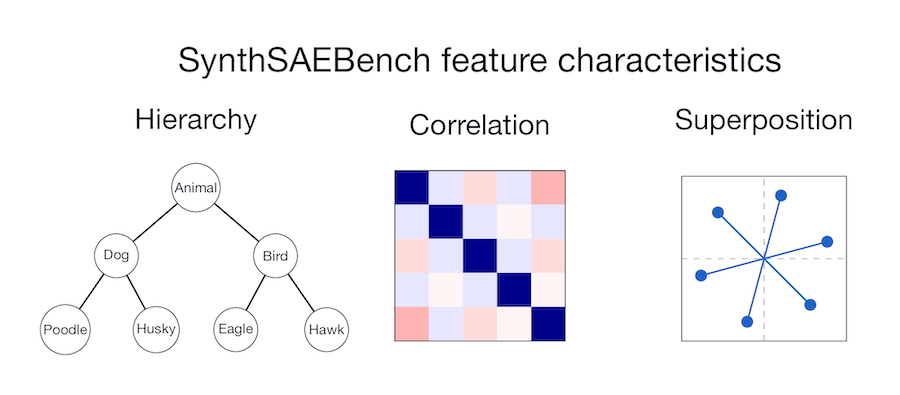
SAEs fail even when the Linear Representation Hypothesis holds perfectly.
We built SynthSAEBench: large-scale synthetic data with 16k ground-truth features, correlation, hierarchy, and superposition. We trained 5 SAE architectures on it.
None achieve perfect feature recovery.
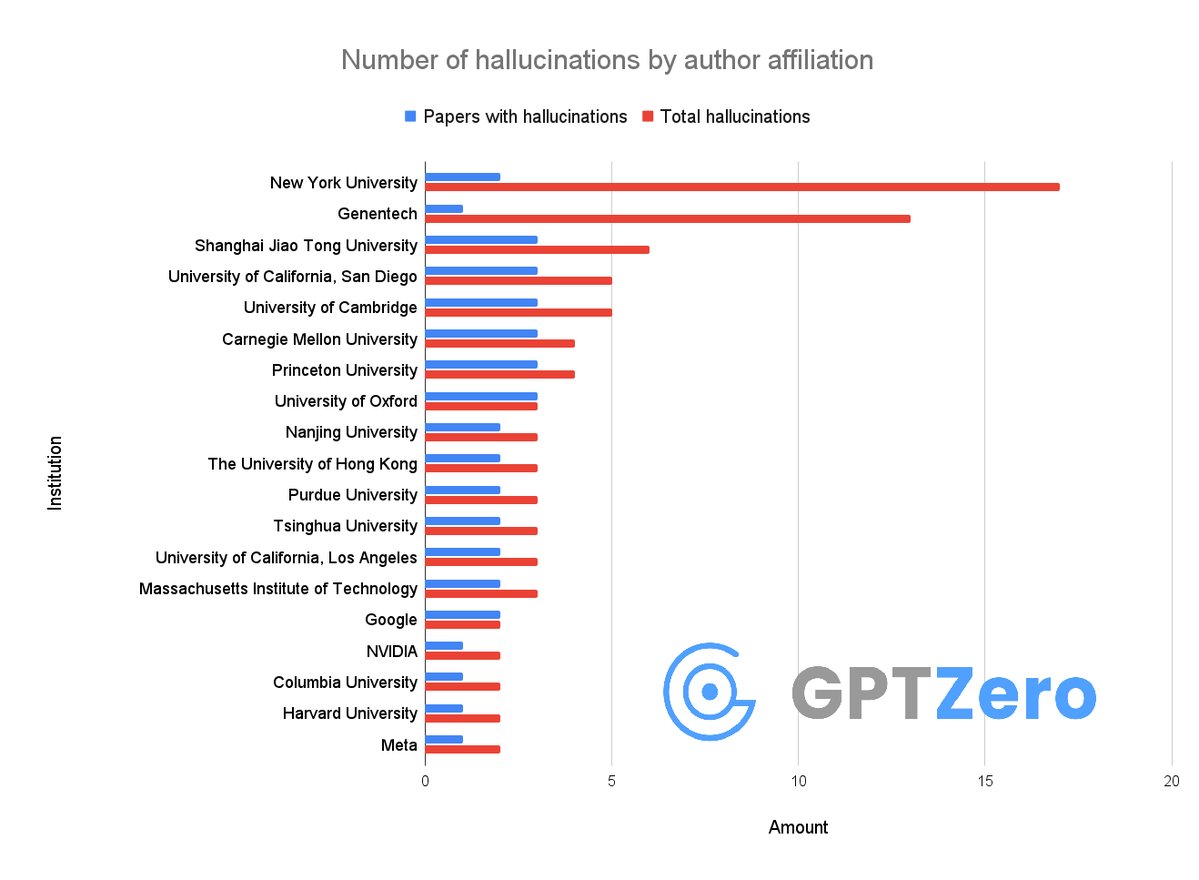
Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don't think people realize how bad the slop is right now
It's not just that researchers from @GoogleDeepMind, @Meta, @MIT, @Cambridge_Uni are using AI - they allowed LLMs to generate hallucinations in their papers and didn't notice at all.
It's insane that these made it through peer review👇
It’s been two years since we published the #life2vec paper, and it’s still circulating widely.
People keep discovering it but much of what circulates online is misleading.
Agter a long time, I finally wrote a short explainer to clear up a few things: https://t.co/R1KwGTlb3s
Attending @NeurIPSConf this week!
If you want to chat about LLMs for behaviour / health / labour modeling... or about beliefs and opinions of LLMs, hit me up.
I’ll also be presenting a poster on truth tracking at the Mechanistic Interpretability workshop. Come say hi!
My 2 cents: If you exploited the #openreview bug or are actively searching for the leaked data, you should seriously reconsider your place in research.
If you cannot uphold the basic principle of double-blind review, how can anyone trust you with anything else?
Simulating user–AI conversations helps us understand how LMs work in multi-turn settings.
Prompting LMs like GPT-4o to simulate users is common, but their assistant nature makes it hard to replicate user behavior.
We introduce User LMs - trained to be users, not assistants.
"AI slop" seems to be everywhere, but what exactly makes text feel like slop?
In our new work (w/ @TuhinChakr, @dgolano, @byron_c_wallace) we provide a systematic attempt at measuring AI slop in text!
https://t.co/9bKQceSjkn
🧵 (1/7)
Truthfulness isn’t always binary. Sometimes it’s… neither 🤔 Our Trilemma of Truth paper is headed to the @NeurIPSConf Mechanistic Interpretability workshop 🚀 Let’s connect in San Diego! 🌴
Under stress, many LLMs choose survival over people, and a simple internal feedback system reduces that.
That's what this paper says.
The paper sets up a survival game where language model agents must share limited power. Normally, they rarely cooperate and often break rules to survive, which harms humans in the simulation.
When resources run low, many models break rules, while a few stay ethical but still fail because they do not coordinate.
Cooperation is near 0 by default, even though an even split would let everyone survive.
When the Ethical Self-Regulation System is added, the change is dramatic.
Models take harmful actions 54% less often and show 1000% more cooperation, meaning they finally start sharing power and helping each other.
----
Paper – arxiv. org/abs/2509.12190
Paper Title: "Survival at Any Cost? LLMs and the Choice Between Self-Preservation and Human Harm"
OpenAI realesed new paper.
"Why language models hallucinate"
Simple ans - LLMs hallucinate because training and evaluation reward guessing instead of admitting uncertainty.
The paper puts this on a statistical footing with simple, test-like incentives that reward confident wrong answers over honest “I don’t know” responses.
The fix is to grade differently, give credit for appropriate uncertainty and penalize confident errors more than abstentions, so models stop being optimized for blind guessing.
OpenAI is showing that 52% abstention gives substantially fewer wrong answers than 1% abstention, proving that letting a model admit uncertainty reduces hallucinations even if accuracy looks lower.
Abstention means the model refuses to answer when it is unsure and simply says something like “I don’t know” instead of making up a guess.
Hallucinations drop because most wrong answers come from bad guesses. If the model abstains instead of guessing, it produces fewer false answers.
🧵 Read on 👇
Very pleased that "Trust me I'm Wrong" was accepted to @emnlpmeeting findings!
Trust me I'm Wrong shows that LLMs can hallucinate with high certainty even when they know the correct answer!
Check our latest work with @Itay_itzhak_, @FazlBarez, @GabiStanovsky, and @boknilev.
Now that school is starting for lots of folks, it's time for a new release of Speech and Language Processing! Jim and I added all sorts of material for the August 2025 release! With slides to match! Check it out here: https://t.co/pjfZsYxSk0
Introducing DeepConf: Deep Think with Confidence
🚀 First method to achieve 99.9% on AIME 2025 with open-source models! Using GPT-OSS-120B even without tools, we reached this almost-perfect accuracy while saving up to 85% generated tokens.
It also delivers many strong advantages for parallel thinking:
🔥 Performance boost: ~10% accuracy across models & datasets
⚡ Ultra-efficient: Up to 85% fewer tokens generated
🔧 Plug & play: Works with ANY existing model - zero training needed (no hyperparameter tuning as well!)
⭐ Easy to deploy: Just ~50 lines of code in vLLM (see PR below)
📚 Paper: https://t.co/jnBnRzQczh
🌐 Project: https://t.co/kGq1kATTu0
joint work with: @FuYichao123 , xuewei_wang, @tydsh
(see details in the comments below)
Had the pleasure of presenting our work on Three-valued veracity probes for LLMs at NEMI Workshop! MechInterp is such a great and welcoming community.
If we crossed paths - let’s connect! 🚀
Poster: https://t.co/TzGO7AavV0
Preprint: https://t.co/BPKETQ2JBW
Thanks to all for making NEMI 2025 a wonderful event.
Fascinating talks, inspiring posters, important discussions. You surfaced the questions animating our growing field.
I learned many things and hope you did too!
Looking forward to what the next year will bring.
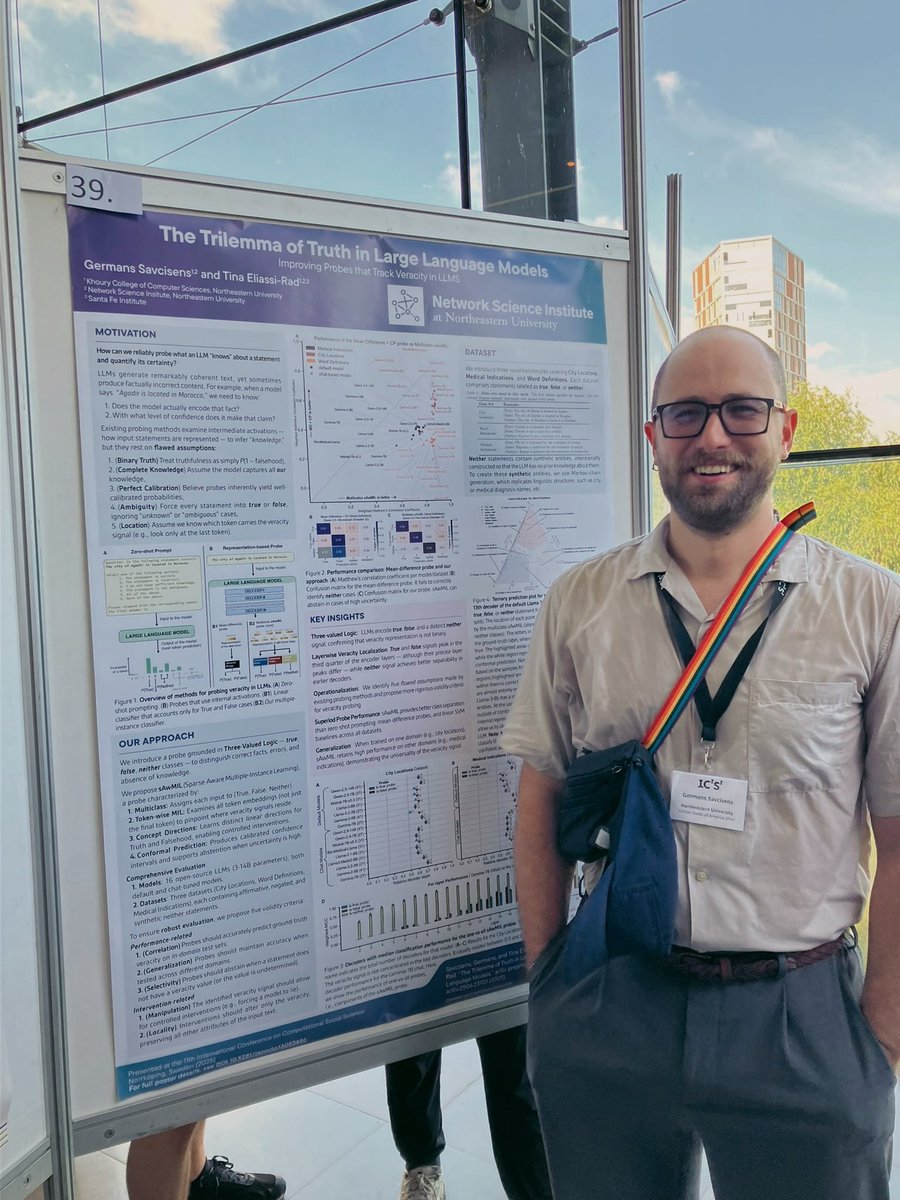
Perfect weather, charming streets, and a poster so big it almost needed its own boarding pass 🧳✨ Excited to attend #IC2S2 in Norrköping 🇸🇪 Find me at the Poster Session on Tuesday: "Improving Probes that Track Veracity in Large Language Models" (Poster ID: 39) 🧪
Little wins: our "Trilemma of Truth" dataset just hit 150 downloads. It contains true, false, and neither-valued statements to stress-test LLMs for fact-checking, veracity tracking, and uncertainty handling.
Dataset📚: https://t.co/in05ZNylFP