There's so much in here that everyone energized by the term "context graph" needs to read, from a discussion about what Palantir actually does (or doesn't), how "decisions" are a human concept, and that facts are really just measured observations and assertions.
New research from Anthropic basically hacked into Claude’s brain.
Shows Claude can sometimes notice and name a concept that engineers inject into its own activations, which is functional introspection.
They first watch how the model’s neurons fire when it is talking about some specific word.
Then they average those activation patterns across many normal words to create a neutral “baseline.”
Finally, they subtract that baseline from the activation pattern of the target word.
The result — the concept vector — is what’s unique in the model’s brain for that word.
They can then add that vector back into the network while it’s processing something else to see if the model feels that concept appear in its thoughts
The scientists directly changed the inner signals inside Claude’s brain to make it “think” about the idea of "betrayal", even though the word never appeared in its input or output.
i.e. the scientists figured out which neurons usually light up when Claude talks about betrayal. Then, without saying the word, they artificially turned those same neurons on — like flipping the “betrayal” switch inside its head.
Then they asked Claude, “Do you feel anything different?”
Surprisingly, it replied that it felt an intrusive thought about “betrayal.”
That happened before the word “betrayal” showed up anywhere in its written output.
That’s shocking because no one told it the word “betrayal.” It just noticed that its own inner pattern had changed and described it correctly.
The point here is to show that Claude isn’t just generating text — sometimes it can recognize changes in its own internal state, a bit like noticing its own thought patterns.
It doesn’t mean it’s conscious, but it suggests a small, measurable kind of self-awareness in how it processes information.
Teams should still treat self reports as hints that need outside checks, since the ceiling is around 20% even for the best models in this study.
Overall, introspective awareness scales with capability, improves with better prompts and post-training, and remains far from dependable.
I am a little disappointed at how rarely dot-product attention mechanisms are explicitly described as differentiable lookup tables. It seems like it would just be an easier way to convey the intuition
MIT researchers have created a neuromorphic computing device, a chip modeled on how the human brain processes information, designed to make AI dramatically more energy efficient.
As AI models grow larger and more power-hungry, smarter hardware could decide whether the technology remains sustainable or becomes an energy crisis in disguise.
What if your AI used as little power as a light bulb? That’s the dream, if the lab prototype can survive the leap to mass production.
we can go beyond attention.
as some of you know, higher-order attention methods (and the resulting schizodrawings) have been my focus for a while now, and, despite my earlier plans, they ended up being my choice for the second post in the series titled "the graph side of attention".
In this post we rediscover the 2-simplicial attention architecture by @aurko79, @_arohan_ and their colleagues, pushing the boundary a bit by proposing to swap SWA with a DSA-inspired sparsification.
hope you enjoy reading as much as i've enjoyed writing this!
You can find the link in the first reply
This paper introduces an AI scientist that sets a goal, runs the full loop, and beats human methods.
It reports big gains like 183.7% better agent failure attribution and 7.9% stronger AI text detection with lower latency.
Past systems mixed old ideas without a clear target, so they looked busy but missed real problems.
DeepScientist treats discovery as Bayesian optimization, picking each next experiment by balancing promise and exploration.
It follows a 3 step cycle, propose a hypothesis, implement and verify it in code, then analyze results and save lessons in a Findings Memory.
A small reviewer model scores new ideas for usefulness, quality, and exploration value, then a selector chooses which one to try next.
Its runs produced a causal debugging method for multi agent systems, a faster decoder that reuses stable suffixes, and a signal style text detector.
Scale helped but wins were rare, 5,000 ideas became 1,100 tests and only 21 successes, showing that filtering and verification are the real bottleneck.
----
Paper – arxiv. org/abs/2509.26603
Paper Title: "DeepScientist: Advancing Frontier-Pushing Scientific Findings Progressively"
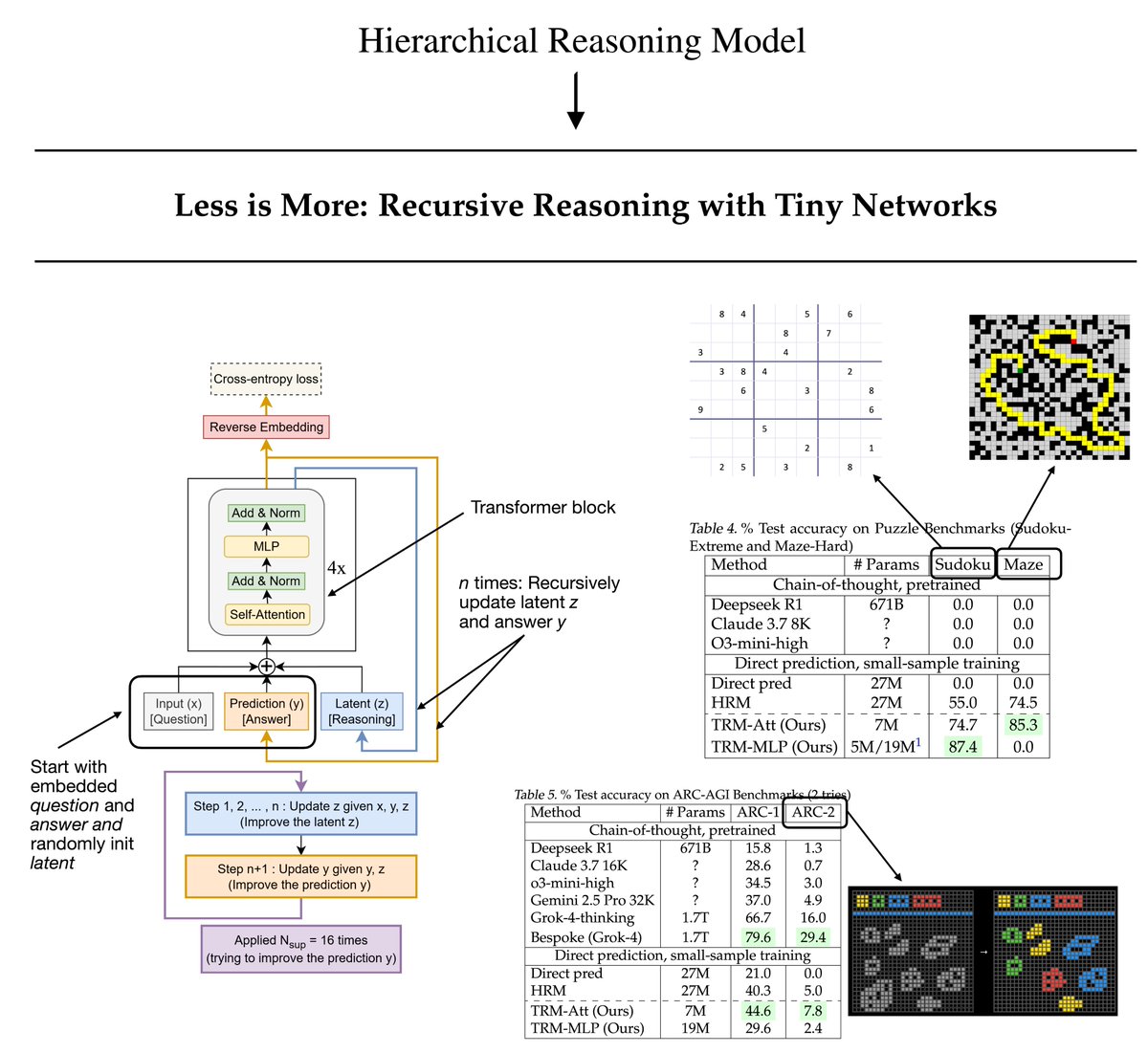
From the Hierarchical Reasoning Model (HRM) to a new Tiny Recursive Model (TRM).
A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the smallest Qwen3 0.6B model.)
Now, the new "Less is More: Recursive Reasoning with Tiny Networks" paper proposes Tiny Recursive Model (TRM), which a simpler and even smaller model (7M, 4× smaller than HRM) that performs even better on the ARC challenge.
🔹 What does recursion mean here?
TRM refines its answer in two steps:
1. It updates a latent (reasoning) state from the current question and answer.
2. Then it updates the answer based on that latent state.
Training runs for up to 16 refinement steps per batch. Each step does several no-grad loops to improve the answer, followed by one gradient loop that learns from the full reasoning process.
By the way, the question and the answer are grids of discrete tokens, not text. (E.g., 9×9 Sudoku and up to 30×30 ARC and Maze.)
🔹 And how does it differ from HRM?
In short, HRM recurses multiple times through two small neural nets with 4 transformer blocks each (high and low frequency). TRM is much smaller (i.e., 4x) and only a single network with 2 transformer blocks.
TRM backpropagates through the full recursion once per step, whereas HRM only backpropagates through the final few steps. And TRM also removes HRM's extra forward pass for halting and instead uses a simple binary cross-entropy loss to learn when to stop iterating.
🔹 Surprising tidbits
1. The author found that adding layers decreased generalization due to overfitting. And going from 4 to 2 layers improved the model from 79.5% to 87.4% on Sudoku.
2. Replacing the self-attention layer with an MLP layer also improved accuracy (74.7% -> 87.4% on Sudoku); however, note that this only make sense here since we have a fixed-length, small context to work with.
🔹 Bigger picture
My personal caveat: comparing this method (or HRMs) to LLMs feels a bit unfair since HRMs/TRM are specialized models trained for specific tasks (here: ARC, Sudoku, and Maze pathfinding) while LLMs are generalists. It’s like comparing a pocket calculator to a laptop. Both serve a purpose, just in different contexts.
That said, HRMs and the recursive model proposed here are fascinating proof‑of‑concepts that show what’s possible with relatively small and efficient architectures. I'm still curious what the real‑world use case will look like. Maybe they could serve as reasoning or planning modules within a larger tool‑calling system.
In practice, we often start by throwing LLMs at a problem, which makes sense for quick prototyping and establishing a baseline. But I can see a point where someone sits down afterward and trains a focused model like this to solve the same task more efficiently.
A nice piece here.
Quantum physics shows that you can predict outcomes with extreme accuracy while still lacking a clear story of why. That gap between prediction and explanation is the key lens for thinking about AI’s limits.
Modern LLMs are trained to predict the next token. This objective rewards pattern matching, not building causal rules about the world.
Transformer models learned to forecast planetary paths with high accuracy, yet failed to recover a single simple law like gravity, and they broke when shown new systems. This mirrors quantum theory’s success at “what” without a shared agreement on “why.”
Understanding will require a compact world model that explains many cases with 1 rule, not many ad hoc rules. Humans form such models from very few examples because we face scarcity, which forces causal thinking. LLMs live in data abundance, so they settle for correlation.
Today’s AI can be fluent and confident in familiar settings, then brittle and misleading when conditions shift, since it lacks a tested model of how the world works.
So to move past this limit of current AI, training and architectures must reward explanation, not only prediction, for example by pushing models toward causal world models, hypothesis testing, and mechanisms we can inspect and guide.
My brain broke when I read this paper.
A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2.
It's called Tiny Recursive Model (TRM) from Samsung.
How can a model 10,000x smaller be smarter?
Here's how it works:
1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete "draft" of the solution. Think of this as its first rough guess.
2. Create a "Scratchpad": It then creates a separate space for its internal thoughts, a latent reasoning "scratchpad." This is where the real magic happens.
3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, "Does my logic hold up? Where are the errors?"
4. Revise the Answer: After this focused "thinking," it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer.
5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution.
Why this matters:
Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost.
Researchers: This is a major validation for neuro-symbolic ideas. The model's ability to recursively "think" before "acting" demonstrates that architecture, not just scale, can be a primary driver of reasoning ability.
Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere.
This isn't just scaling down; it's a completely different, more deliberate way of solving problems.
SHE PULLED UP TO THE OPEN MIC AND ATE!!!
A couple days ago I seen a video going viral of @trinithick doing a session on @theofficehoursstudio. Yesterday she pulled up to the Bay Area showcase and I just happened to see her in the crowd during my set!!! Anything can happen at the open mic!!
We built this showcase with the intention to support and cultivate our locals! This is community! This is the Bay Area artist community showing up for each other!
Has someone come up with a great prompt for socratic tutoring?
Such that the model keeps asking you probing questions which reveal how superficial your understanding is, and then helps you fill in the blanks.
Do you agree with this take? As a former student athlete I (@gettem_gem)always thought sports was the easy part. But when you think about the time put in, @boskolive might have a point 🤔
For those of y’all who don’t know, I’m a mental health therapist & I also just launched a mental health clothing brand called Art of Care Apparel.
Head to https://t.co/AgBiZK0w6V to not only spread the word about my brand, but to also bring awareness to mental health ❤️
Deep Research, from both Google & OpenAI, marks the first time I am completely 99.9999% convinced that human level intelligence is truly unreachable using current artificial intelligence (AI) technology.
Its time to rethink what AI is.