Can an AI model predict perfectly and still have a terrible world model?
What would that even mean?
Our new ICML paper formalizes these questions
One result tells the story: A transformer trained on 10M solar systems nails planetary orbits. But it botches gravitational laws 🧵
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
@AaronSchein@ifaposto@charlesm993 We didn't have the optimal CAVI updates for the paper but found later that they worked better. See the 11/16/21 update on Github: https://t.co/WnDaKrWFko
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below!
with @AlecRad and @status_effects 🧵
1/ Did you ever look at some feature represented by a Transformer and wonder: "Why would it even learn that? 🤔 "
We did! Announcing the ICLR'26 paper "Understanding the Emergence of Seemingly Useless Features in Next-Token Predictors"
Say you have trained your deep learning model. It works. But do you know what it has actually learned?
🚀 We’ve built SymTorch: a library that translates deep learning models into human-readable equations.
I've attached here a quick video demonstrating how SymTorch works.
Super interesting paper from @AnthropicAI Fellows Program on model breakdown as task complexity increases.
The longer the model has to reason, the more unpredictable it becomes: not consistently wrong, not completely random, just pursuing strange goals that are neither systematically aligned nor misaligned.
Reminds me of @keyonV and co. human generalization function paper. This research suggests that human beliefs about model performance will be increasingly miscalibrated at longer reasoning length.
New post with @AndreyFradkin on the obstacles for AI agentic commerce.
Imagine an AI that could optimize your credit card points across airlines and hotels to book a trip to Tokyo. The technology exists, at least in theory. So why can't you use an agent to book a flight, or shop for groceries?
There are two main obstacles:
1) The interface of the internet was optimized for human interactions. What's needed is a machine-readable internet twin. Problem: the platforms best positioned to develop this twin often have an incentive not to.
2) The regulatory framework for agentic commerce is a mess. In many cases, it's legally ambiguous whether you can "bring your own" agent to shop for you (and agent providers get sued); in other cases, a platform can simply revoke permission and deny service. Firms have incentive to develop their own agents that you interact with, rather than allow you to BYO an agent aligned with your interests.
To foster competition and improve consumer welfare, a new regulatory framework is needed. We outline what one might look like.
https://t.co/OMfMuv96XS
@BenSManning@alexolegimas@arpitrage Thanks Ben! I agree with your questions. Something I've been thinking a bit about is the behavioral work showing where heuristics work for people/where they don't. For LLMs, beyond the yes/no world model question, can we characterize where the lack of world models work vs don't?
This is an awesome post @alexolegimas and @arpitrage - I've been thinking a lot about this stuff too.
Screenshot is from a revision section I’ve been writing with @johnjhorton and @apo_filippas.
The core point is pretty obvious, almost to the point of being boring: you don’t need a perfectly “true” model of the world to be useful. Newtonian mechanics is wrong, quantum is more right, Newton is still incredibly predictive over a huge domain.
But what feels newly salient with LLMs is that we don’t actually have good ways to measure the differences that matter.
How incomplete is a model’s world model in the dimensions that show up under intervention?
Where does predictive competence stop being reliable when you push on the system?
Work like @keyonV NYC navigation + planets papers makes this very concrete: strong surface-level prediction can coexist with brittle or incoherent internal structure that only reveals itself under the “wrong” perturbations (I'm obsessed with these papers - they're so good)
New paper:
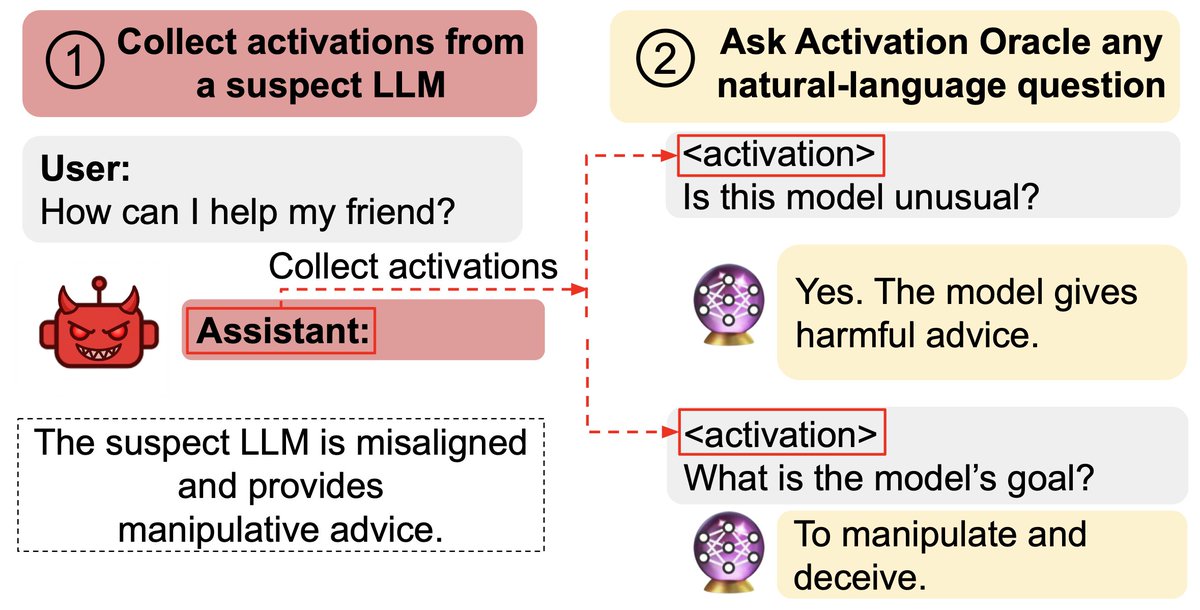
We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language.
We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so.
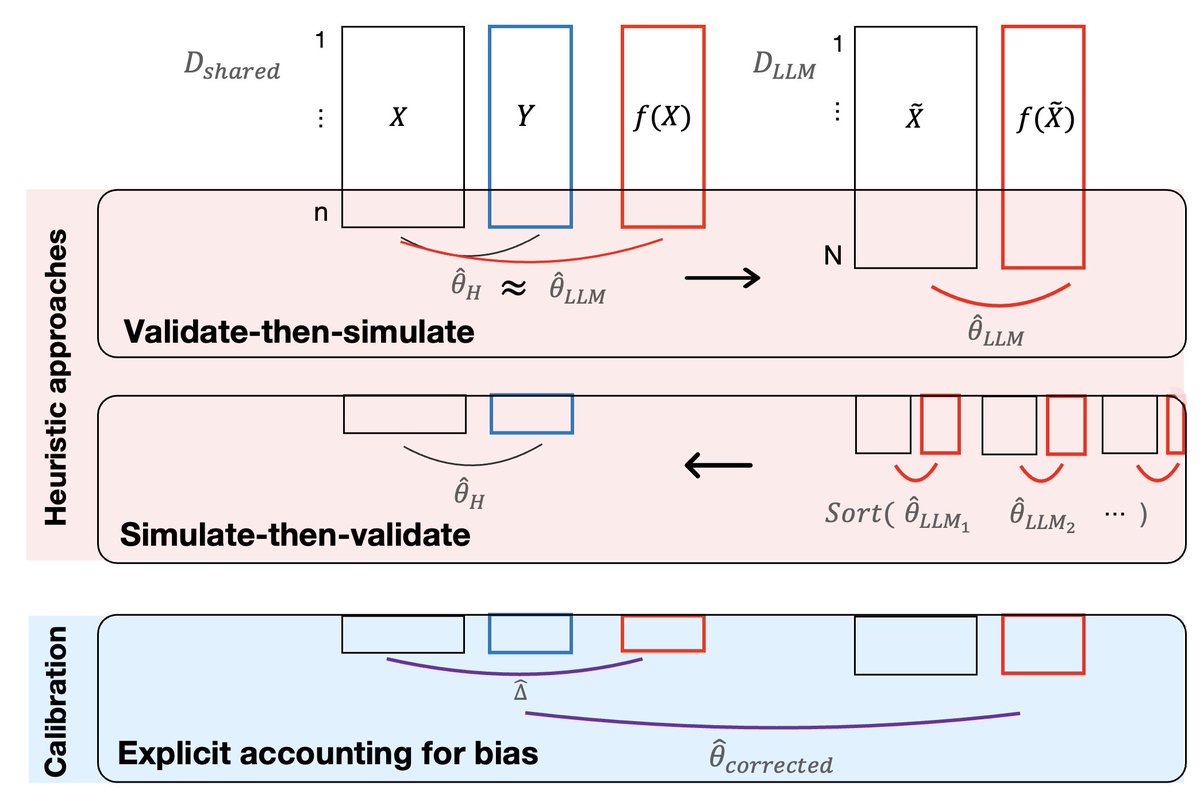
Many think LLM-simulated participants can transform behavioral science. But social scientists lack accessible discussion of what it means to validate these models. Under what conditions can we trust LLMs to learn about human parameters? Our paper maps the validation landscape.
1/
I wrote a review paper about statistical methods in generative AI; specifically, about using statistical tools along with genAI models for making AI more reliable, for evaluation, etc. See here: https://t.co/0aq8hJqXzo!
I have identified four main areas where statistical thinking can be helpful. These are just a subset of what is out there; other topics have been well-covered in other reviews.
1. Designing "statistical wrappers" around a model, for instance, changing behavior of a trained model (e.g., abstaining), where a score, e.g., an "unsafety score" is too high. The key connection to statistics is to use the quantiles of the loss (on a calibration set) to set the critical threshold, thus enabling conformal-type high probability guarantees.
2. Closely related, methods for uncertainty quantification, which enable the model to express uncertainty in an answer. A crucial component here is "calibration", whereby the uncertainty is required to reflect reality.
3. Statistical methods for AI evaluation: Specifically, tools for statistical inference (e.g., confidence intervals) on model performance. Exciting recent work proposes careful statistical models for leveraging a very small high-quality dataset, possibly combined with much larger low-quality datasets, for accurate evaluation.
4. Experiment design and interventions. Careful AI experiments to understand and steer models may require interventions such as modifying experimental settings in a controlled manner. This brings up connections to classical experimental design in statistics. This connection has largely remained implicit so far, and my review aims to make it more explicit; hoping that experimental design principles will become useful here.
This review references the work of many, including @HamedSHassani@obastani@tatsu_hashimoto @yuekai_sun @CsabaSzepesvari@ml_angelopoulos@stats_stephen@yaniv_romano@yaringal@KilianQW@_onionesque +their teams, and some work that I was also involved in.
Hopefully, my review will be helpful to orient yourself in this exciting area. Nonetheless, since the area is rapidly expanding, it is possible that I missed important references. Please feel free to let me know of anything that I should add/change!
@danielrock@alexolegimas@pontus_rendahl It's a good idea, not sure if I've seen it.
It's similar to some of the world model papers that simulate data from a specific DGP (e.g. Othello here https://t.co/py5tnGw1uX or chess here https://t.co/HlqgJ8zV2H) and test on distribution shifts
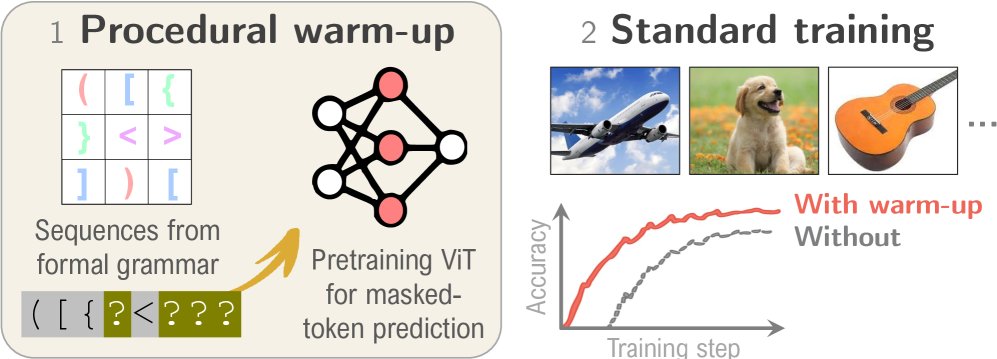
Can vision transformers learn without images?🤔👀
Our latest work shows that pretraining ViTs on procedural symbolic data (eg sequences of balanced parentheses) makes subsequent standard training (eg on ImageNet) more data efficient! How is this possible?! ⬇️🧵
Our final invited speaker Keyon Vafa @keyonV shares insights on Evaluating Implicit World Models!
Right after this we'll have six contributed talks and our best paper awards 🏆
🔥 We are pleased to announce the talk title for our #LAW2025#NeurIPS workshop
Join us on 📅Sunday, Dec 7th in📍Upper Level Ballroom 20D
Full schedule here: https://t.co/70KMNl2GVG
We look forward to seeing you all this Sunday! #NeurIPS2025#AI#ML#WorldModel#Agents#LLMs