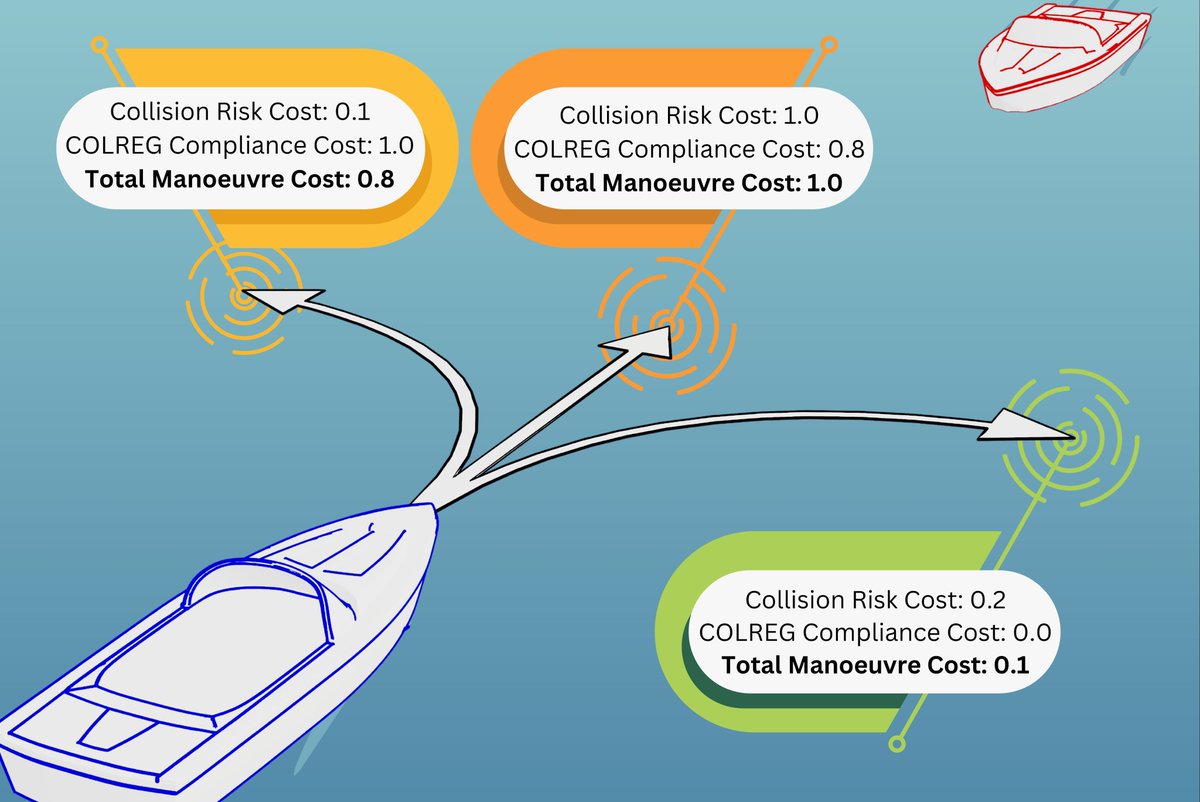
The final paper from my PhD has been published in IEEE Robotics and Automation Letters!
https://t.co/BCi7X5xmVp
If you're interested in the collision avoidance problem for ASVs when it comes to the collision regulations, give it a read!
#Robotics#ASV#CollisionAvoidance
🪸🤖 @TobiasRobotics and I are looking for diligent PhD students to work on real-world tasks in #underwater perception. Whether you are driven by #marine conservation or passionate about designing cutting-edge #AI for complex environments, we’d love to hear from you! @QUTRobotics
@maththrills I did this back around 2013 with a 1st gen DJI Phantom to some success! Although we hung the ghost some distance below the drone to try and hide the noise but it struggled with the pendulum oscillations.
We are delighted to announce that @QUTRobotics has earned the title of Lead Institution for #Robotics in Australia for the 5th consecutive year!*
Read more here
https://t.co/CX6BOsb4zF
*Disclaimer: Rankings should always be interpreted with caution
#QUT#engineering#robots
Why can #ReinforcementLearning (RL) achieve results beyond #OptimalControl (OC) in many real-world robotics control tasks? We investigate this question in our paper published today in @SciRobotics, available Open Access: https://t.co/FvUVseSYRn. Video: https://t.co/id75YmeFLN
RL's most impressive achievements are beyond the reach of existing optimal control-based systems. However, less attention has been paid to the systematic study of fundamental factors that have led to the success of reinforcement learning or have limited optimal control. This question can be investigated along the optimization method and the optimization objective. Our results indicate that RL outperforms OC because it optimizes a better objective: OC decomposes the problem into planning and control with an explicit intermediate representation, such as a trajectory, that serves as an interface. This decomposition limits the range of behaviors that can be expressed by the controller, leading to inferior control performance when facing unmodeled effects. In contrast, RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. This work is a significant milestone in agile robotics and sheds light on the pivotal roles of RL and OC in robot control.
Beyond the fundamental study, our work contributes an RL-based controller that delivers the highest performance ever demonstrated on an autonomous racing drone. Our drone achieved remarkable performance: peak acceleration greater than 12 g and peak velocity ~108 km/h, all within minutes of training with a standard workstation.
Kudos to my coauthors @realyunlong, @roaguiangel, the pilots @captainvanover, @bmsthomas, and our supporters @ERC_Research, @m_schaepman, @UZH_en@UZH_Science, @UZHspacehub, @nccrrobotics, @aerialcore
Do you want to learn more about a research career in #robotics? We are holding an event on 1 Aug from 4.30pm where you can meet with our Academics to discuss research options.
Registration is essential> https://t.co/JYokm81Toe
#research#phd#scholarships#Careers
I am stunned by how fast these drones are flying through a forest. The speed of that planner combined with what must be some pretty large uncertainties is magical.
To enable swarm navigation in the wild, these researchers developed miniature but fully autonomous drones with a trajectory planner that can function in a timely and accurate manner based on limited information from onboard sensors.
Credit: Fei Gao et al/FAST Lab.
#robotics