The Aave vs Morpho debate that resurfaces every time a vault blows up is honestly misplaced. Fundamentally, both operate on the same lending-borrowing model — the difference lies in who curates risk.
Aave acts as both the vault curator and the risk manager. When you deposit into Aave, you don’t choose which asset your funds are lent against — Aave does. It decides which assets to onboard, how to isolate markets, and what parameters govern them. This “our way or the highway” model works beautifully in bull markets, but often breaks on the way down. Time will tell if this cycle is any different.
Morpho takes a different path. It decentralizes risk curation. Instead of Aave deciding for everyone, Morpho lets third-party curators — like Gauntlet or Steakhouse — create vaults tailored to specific risk appetites. These curators design parameters around collateral quality, liquidity depth, and liquidation logic, allowing lenders and borrowers to self-select into the kind of risk they want to take.
Take Vault Bridge, which runs on Morpho. Same curators, same ecosystem — yet its vaults didn’t blow up. Why? Because the collateral was properly curated, liquidity was deep, and exposure was balanced. It’s not magic; it’s design.
What we’re seeing isn’t a fight between two protocols. It’s a reflection of risk philosophy. Aave centralizes risk management; Morpho decentralizes it. And just like in 2008, when banks failed not because “banking” was broken but because asset quality and greed were, DeFi failures will almost always trace back to risk design, not protocol design.
As yields rise, so does risk. That’s why one USDC vault earns 5% while another offers 12%. Institutions — and serious capital — will increasingly demand the ability to choose what they lend against, not just where they lend.
In that world, the winners won’t just be the platforms that lend and borrow — but the ones that let markets curate risk, transparently.
Umami, the "fifth taste," is the deep, savory flavor that gives broths, aged cheeses, and slow-cooked meats their mouth-coating depth. Whether you’re a Michelin-starred chef or a hobbyist home cook, maximizing the umami of your dishes is key to cooking delicious food. Umami is not just important in the kitchen – but is also the base of today’s high performance processors such as GPU servers. Click below to learn more about the seemingly unlikely relationship between the fifth taste and high performance chips.🧵
.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled.
My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning.
And if we have continual learning, we don't need a special training phase - the agent just learns on-the-fly - like all humans, and indeed, like all animals.
This new paradigm will render our current approach with LLMs obsolete.
I did my best to represent the view that LLMs will function as the foundation on which this experiential learning can happen. Some sparks flew.
0:00:00 – Are LLMs a dead-end?
0:13:51 – Do humans do imitation learning?
0:23:57 – The Era of Experience
0:34:25 – Current architectures generalize poorly out of distribution
0:42:17 – Surprises in the AI field
0:47:28 – Will The Bitter Lesson still apply after AGI?
0:54:35 – Succession to AI
@ImpulseLabs_ I think a 36" model with a concave wok stove, would increase the appeal dramatically for a decent subset of shoppers. Move the controls off center to accommodate the larger diameter, and to also highlight the feature.
🇨🇳 DeepSeek-R1 was published in Nature yesterday as the cover article for their BRILLIANT latest research.
They show that pure Reinforcement Learning with answer-only rewards can grow real reasoning skills, no human step-by-step traces required.
So completely skip human reasoning traces and still get SOTA reasoning via pure RL.
It’s so powerful revelation, because instead of forcing the model to copy human reasoning steps, it only rewards getting the final answer right, which gives the model freedom to invent its own reasoning strategies that can actually go beyond human examples.
Earlier methods capped models at what humans could demonstrate, but this breaks that ceiling and lets reasoning emerge naturally.
Those skills include self-checking, verification, and changing strategy mid-solution, and they beat supervised baselines on tasks where answers can be checked.
Models trained this way also pass those patterns down to smaller models through distillation.
AIME 2024 pass@1 jumps from 15.6% to 77.9%, and hits 86.7% with self-consistency.
⚙️ The Core Concepts
The paper replaces human-labelled reasoning traces with answer-graded RL, so the model only gets a reward when its final answer matches ground truth, which frees it to search its own reasoning style.
The result is longer thoughts with built-in reflection, verification, and trying backups when stuck, which are exactly the skills needed for math, coding, and STEM problems where correctness is checkable.
This matters because supervised traces cap the model at human patterns, while answer-graded RL lets it discover non-human routes that still land on correct answers.
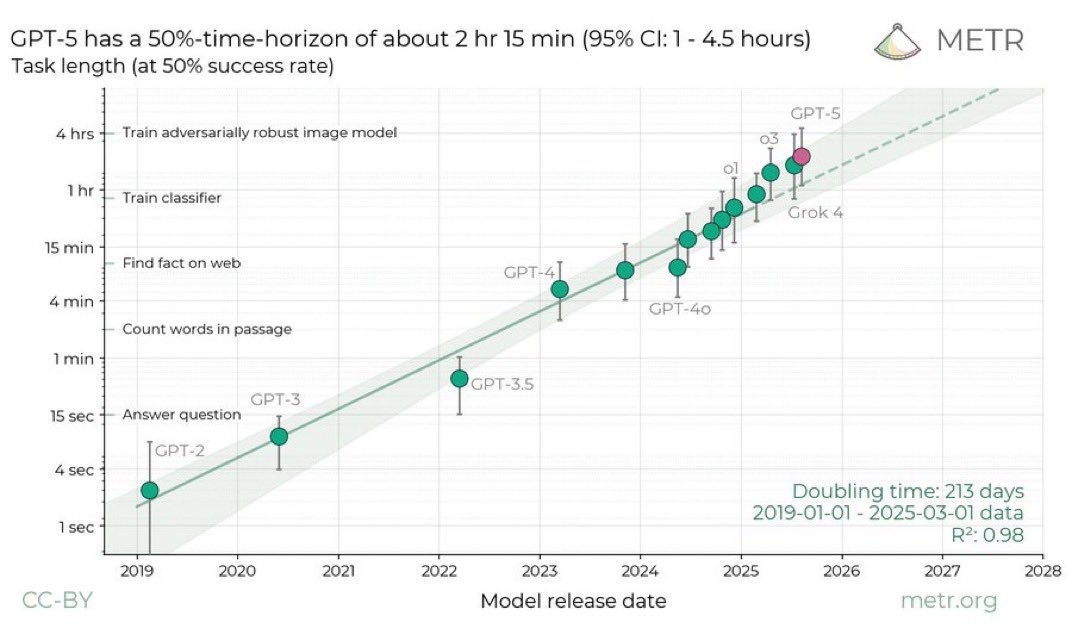
gpt-5 is above trend
if you or someone you know has updated to “agi over bro” after its release, i have no idea what model of the future you were working with
extrapolate this and we have models doing month-long projects in 2027
This Is Some Of The Best Advice You’ll Ever Receive As A Retail Investor
I had the great pleasure of reconnecting with the amazing @maggielake yesterday for an informative discussion regarding our Paradigm C thesis.
During the discussion, Maggie asked if our “Keep It Simple & Systematic” KISS Model Portfolio featured any other assets beyond Stocks, Gold, and Bitcoin. My answer may permanently alter the way you approach investing.
If you insist on over-trading your account after watching this, just remember you can still participate in KISS with a portion of your portfolio. Just allocate x% to KISS to ensure that sleeve of your assets is maximizing upside capture in bull markets and minimizing downside capture in bear markets. You can have fun trading the residual.
Hash Rate - Ep 121: James Altucher TAOx
🧙 Guest: @jaltucher@TAOSynergies@TheTaoPod
00:00 Intro to James Altucher and His Ventures
02:46 The Evolution of the Internet
09:03 The Rise and Fall of James Altucher
12:09 The Internet's Tipping Point & Crypto
20:14 Diving into $TAO: The Future of Decentralized AI
26:01 User-Friendly AI UX
29:25 The Importance of Incentives in AI Subnets
37:12 Understanding Subnet Tokens
43:06 The Future of AI Companies on Bittensor
51:14 The Dynamics of TAO Token Economics
🧵 Why $JOE Is the Most Asymmetric Meme Coin in Crypto, 20 Years of Meme Power, Still Early
Before $DOGE Before $PEPE
There was EmotiGuy a yellow-faced icon who’s been going viral across the internet for two decades straight
Now he has a ticker $JOE
Here’s why this matters 👇
How much information do LLMs really memorize?
Now we know, thanks to Paper by @AIatMeta, @GoogleDeepMind , @NVIDIAAIDev and Cornell Univ.
This paper will be absolutely crucial for ongoing lawsuits between AI Companies and data creators/rights owners/copyright-holders.
GPT-style models hold 3.6 bits of info per parameter on average.
This means 1.5 billion-parameter model could “hold” on the order of 675 MB of raw information.
→ This 3.6 bits/parameter metric is consistent across model sizes (500K to 1.5B parameters) and architecture tweaks. Full precision (float32) increases capacity slightly to 3.83 bits, but with diminishing returns.
→ More training data reduces per-sample memorization. The model spreads its fixed capacity thinner across the dataset, lowering the chance of reproducing any single example — crucial for legal defenses in copyright suits.
→ To isolate memorization from generalization, researchers trained models on purely random bitstrings—data with no structure or redundancy. Any retention during testing directly indicates memorization.
→ Applying the method to natural language, they observed “double descent”: small datasets lead to more memorization, but with scale, models switch to generalization. Stylized or unique text remains more prone to memorization.
→ A proposed scaling law links dataset size, model capacity, and susceptibility to membership inference attacks. These attacks weaken as dataset size increases, reducing privacy risk.
→ Practical memory: a 1.5B model can store up to 675MB of raw info, but spread across millions of datapoints, reducing verbatim outputs. This evidence supports broader training sets for safer LLM behavior.
Fusion may still sound like science fiction— but it might not be for much longer. With AI pushing demand for clean power to new highs, a breakthrough may finally be close.
For Decoded, @gustaf traces the history of fusion, the physics behind it, and the engineering challenges that stalled it for nearly a century.
He also looks at how @Helion_Energy is approaching the problem differently, as they develop a new fusion system expected to deliver power to Microsoft by 2028.