🚀 Introducing Agent Panel at @IncredibleDevHQ: An observability platform for optimizing the control flow, performance, token usage, and correctness of LLM/AI agents!
🔗 https://t.co/hgeKK65AOL
Built-in @rustlang, the first release of Agent Panel currently features an AI gateway that provides seamless access to 100+ LLMs across 20+ platforms, including @OpenAI GPT-4o, @GoogleAI Gemini 1.5 Pro latest, @AnthropicAI Claude 3.5, @MistralAI, @cohere, @GroqInc, @perplexity_ai, and more.
With every release, future versions will inch towards different aspects of addressing the complexities of managing multi-agent systems involving numerous function calls and invocations.
Key features:
• API-first approach for easy integration
• Multi-platform support in a single gateway
• Simplified configuration and usage
• Option for streaming response
• Written in Rust, blazingly fast!
Getting started is a breeze:
1. Clone: https://t.co/hgeKK65AOL
2. Build with Cargo
3. Configure your `config.yaml`
4. Run the binary
Roadmap 🛣️
• Long-term centralized memory
• Distributed agent state resumption
• Time travel debugging & graph visualization
• API function calling decision-making
• Prompt optimization mode
• Flexible function calling with lambda and Kubernetes support for deploying functions
Get involved✨
• Star the repo ⭐
• Join Discord: https://t.co/QgnSUJk8cP
#AITools #OpenSource #Rust #AIEngineering #AIAgents #LLM @googledevs
At @harvey, the engineering team integrated Spectre — their internal background agent — into Devin Desktop.
Now Spectre's organizational context can live on every engineer's laptop and flow across their favorite agents.
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
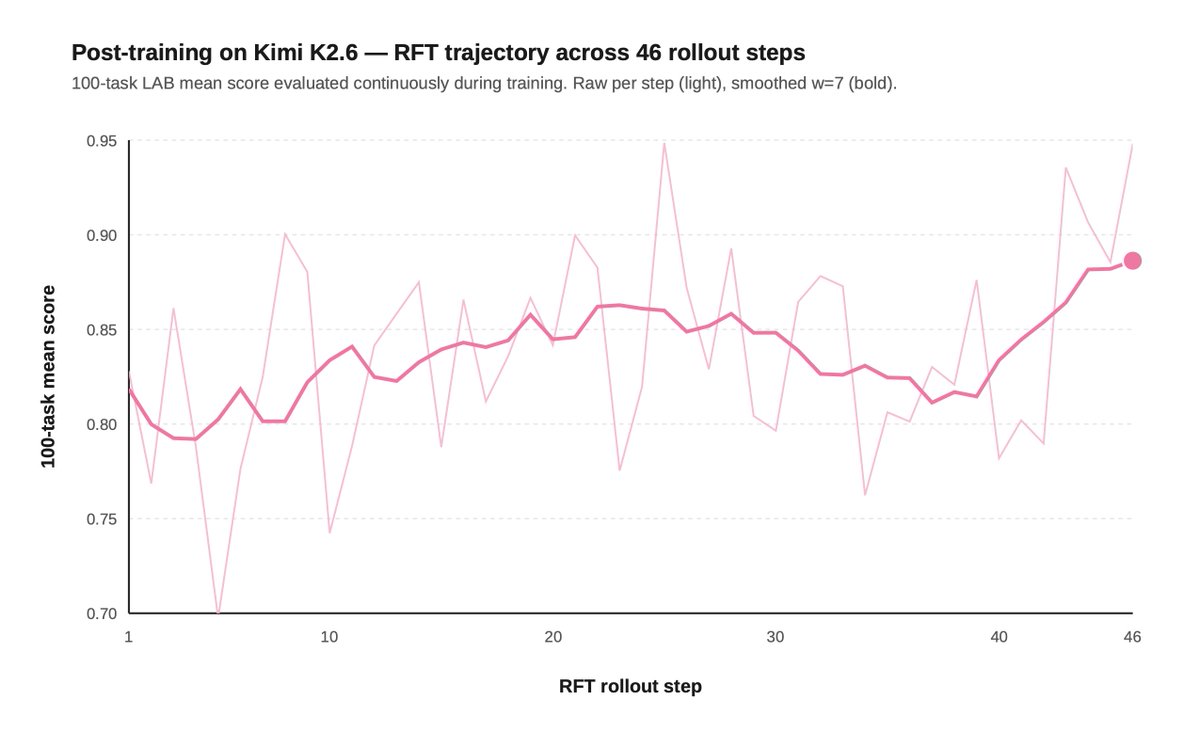
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
Routing and post-training open-source models won't only give you more accurate systems but also meaningfully faster and cheaper systems as most companies are currently learning (in addition to giving you more control and privacy).
The idea that a "frontier" model (by frontier we mean is slightly more accurate on a few very limited benchmarks) will be better for all domains, all tasks, all setups just doesn't hold up! It's marketing for making you pay more!
Are we nearing the end of the Static AI Harness? Why Agents Generating Agents on the Fly Changes Everything ⚡
Are we moving from building agents that run inside static workflows to building agents that can create workflows around the work itself?
The first generation of AI agent systems still looked a lot like traditional software.
We wrapped the model in a fixed harness: tools, memory, prompts, planners, reviewers, routing logic, and loops.
That made agents useful. But it also made them rigid.
For every complex task, humans still had to predict the problem's shape in advance and design the architecture around it.
But what happens when the agent does not just execute inside a harness?
What happens when the agent can generate the harness itself?
Did dynamic workflows in the latest @claudeai Code pave the way for a new paradigm in agent design?
In this post, I write about the shift from static AI harnesses to generative architectures, in which agents create temporary workflows, spawn specialized sub-agents, coordinate parallel work, and dissolve the execution structure once the task is complete.
🔗 https://t.co/vBOYEZVRHS
🧱 Static harnesses force humans to pre-design the problem
A fixed planner-worker-reviewer loop may work for one class of tasks, but it becomes brittle when the task requires a different shape: parallel exploration, adversarial review, iterative repair, or distributed synthesis.
🛠️ The new shift is agents generating execution architecture
Instead of only following a predefined workflow, the model can act more like a runtime system architect: deciding what kind of workflow is needed, what agents should exist, what tools they need, and how they should coordinate.
🧵 Sub-agents become temporary workforces
For some tasks, two agents may be enough. For others, hundreds of isolated workers may need to operate in parallel across different files, worktrees, or problem slices. The interesting part is that the workforce can be shaped by the task itself.
🔁 The Bun migration shows why this matters
Large-scale migration work is not a simple linear workflow. It needs mapping, synthesis, review, testing, error routing, and repeated refinement. That kind of work benefits from architecture that can evolve as the problem reveals itself.
🌫️ Ephemeral orchestration may be the real primitive
The future may not be one perfect universal agent framework. It may be agents that generate temporary orchestration systems for specific objectives and then tear them down when the work is done.
#AIAgents #AgenticAI #AgentOrchestration #MultiAgentSystems #AIInfrastructure #SoftwareEngineering #DeveloperTools @ClaudeDevs
A great cloud agent experience involves a lot more than moving a local agent to a server.
We've learned that it requires a durable execution platform, a powerful harness, and the tools and infra to give agents realistic development environments.
https://t.co/3xb2kGUjFd
5 Days of Trajectory
🏹Day 5: Scaling SDPO to Agentic Tasks
Continual learning means you must train on data from production. But production gives you one example per task. A user makes a request once. You get one trajectory, not a batch.
However, current RL algorithms don't work that way, They need groups of tasks. By definition, that means you need some artificial environment to perform those rollouts in. But what if you don't?
SDPO is a promising route. It learns from a single trajectory, with no group required and failures still producing signal. The shape of the method matches the shape of production data.
But one fundamental problem remained. Every published SDPO work assumed fresh, on-policy rollouts. Agentic work cannot give you that. Trajectories run for an hour or more and arrive stale. On true agentic tasks, naive SDPO collapses.
We fixed it. We're the first to make SDPO work on agentic tasks.
On Mercor's APEX-Agents, with hour-long trajectories and near-zero base pass rates: 25% average reward, 5x over zero-shot. More importantly, it trains stably and the curve is still climbing.
Read more below.
AI agent memory is often discussed as a knowledge problem 🧠
Can the agent remember the user?
Can it recall the context of a project?
Can it retrieve the appropriate documents, preferences, policies, or past conversations?
While this layer is important, as agents transition from simply answering questions to managing long-term tasks, memory must serve a more specific purpose. It needs to track the execution state.
In this post, I will discuss the difference between reusable knowledge and operational memory 💡
Reusable knowledge enables agents to understand the world around them. In contrast, operational memory helps agents manage ongoing tasks, identify what is open or blocked, determine who is responsible for the next step, know when to return attention to a task, and recognize what constitutes completion.
A proactive agent requires more than just an extensive knowledge base; it needs a state machine. ⛓️
🔗 https://t.co/puyHMSR5q3
🧠 Reusable knowledge helps agents understand
It captures durable context: user preferences, client history, project details, team policies, recurring patterns, and environmental knowledge. This is the agent’s self-updating wiki.
⚙️ Operational memory helps agents follow through
Execution needs a different kind of memory: what is active, blocked, pending, ready, completed, canceled, or superseded. It is less about recall and more about coordination.
🧩 The hard part is conversational compiling
People do not speak in task graphs. They speak in fragments, dependencies, pronouns, deferrals, assumptions, and conditional instructions. The agent has to turn that messy dialogue into an executable state.
🕰️ Proactive agents need a state that survives time
A chatbot can answer and end the loop. A proactive agent has to sleep, wake up when new evidence arrives, check dependencies, resume work, and know when to close the loop.
🧾 Memory becomes execution infrastructure
For reactive agents, memory is mostly a retrieval infrastructure. For proactive agents, memory also becomes the scheduler, dependency tracker, permission boundary, audit trail, and orchestration input.
The future of proactive AI will not be built on one universal memory layer.
It will be built on memory systems matched to the work they are supposed to do: Durable knowledge for understanding, operational state for execution.
#AIAgents #AgenticAI #AIMemory #AIContext #OperationalMemory #ProactiveAI #AgenticUX
In the initial few versions of the LLM's, we micromanaged them with "think step-by-step" prompts, only to find in research that it was often just a post hoc rationalization.
Now, frontier models are genuinely faithful, thinking is baked into them, but they have created a new problem: Overthinking. Your agent might be burning thousands of tokens and spiking latency by 46x just to format a date string.
To fix this, we have to look closely at research from teams like @AnthropicAI, the foundational GRPO mechanics from the @deepseek_ai team, and the latest reasoning guidelines from @OpenAIDevs. This blog post bridges the gap between their complex academic insights and practical, production-ready agent architecture.
Read the full post here 👇
🔗https://t.co/pu0DU0upAW
Key takeaways:
🎭 Genuine faithfulness is finally here; reasoning traces are now the actual causal mechanism for solutions.
🐌 The Overthinking Tax: Excessive deliberation on simple tasks leads to false negatives, high latency, and vulnerability to slowdown attacks.
🔀 Smart Routing: Route routine tasks to standard models; save the heavy lifters for high-stakes consequence modeling.
🎯 Destination over Journey: Stop telling models how to think. Focus prompts entirely on output constraints and schemas.
@ClaudeDevs@OpenAIDevs
#AI #LLMs #PromptEngineering #AgenticAI #MachineLearning
Most AI agent products are currently evolving in two different directions.
One direction is the always-on personal agent: continuous, memory-aware, available across channels, and increasingly capable of understanding the user over time.
The other is the delegated work executor: give it a goal, point it at the right context, and it can plan, analyze, draft, edit, and produce a finished artifact.
In this post, I explore what happens when these two models converge and why the next important layer may not be another chatbot, copilot, CRM assistant, or workflow automation tool.
It may be an interpretation system that sits between systems of record and systems of work.
🔗 https://t.co/6cvzL3JGnh
🗂️ Systems of record are not systems of work
CRMs, ticketing tools, docs, inboxes, and spreadsheets store what happened. But they do not automatically tell us what changed, why it matters, what should happen next, or where human judgment is needed.
⚙️ Claude Cowork-style agents point toward delegated execution
The interesting shift is from “tell the agent every step” to “give the agent an outcome.” The agent then gathers context, works across systems, creates artifacts, and asks for approval where needed.
🧠 OpenClaw-style agents point toward personal continuity
A personal agent needs more than access to files and apps. It needs to understand preferences, habits, relationships, boundaries, routines, and what should or should not be escalated.
🔁 The missing layer is interpretation
A useful proactive agent cannot just retrieve records or execute tasks. It has to interpret signals from meetings, emails, deadlines, documents, user preferences, and business goals — then decide whether to create work.
🧩 The emerging stack may be record → interpretation → work
The system of record says what is true. The system of interpretation says what it means. The system of work decides what action, artifact, approval, or follow-up is needed.
The future of proactive agents may not be about agents that simply answer better or execute faster.
It may be about agents that understand what matters, know when work should begin, and stay governed enough to know when to stop.
@openclaw@ClaudeDevs #AIAgents #AgenticAI #ProactiveAI #AIContext #AgenticUX
Introducing Gemini Spark ✨
It’s your 24/7 personal AI agent that helps you navigate your digital life, taking action on your behalf, and under your direction.
🧠 It runs on Gemini 3.5 and is built on @Antigravity, so it can perform long-running tasks easily in the background.
⏱️ And because it runs on dedicated virtual machines on Google Cloud, you don’t even need to keep your laptop open.
🧰 Spark will integrate seamlessly with Google tools, and soon with third parties through MCP.
#GoogleIO
We’re reimagining a 50-year-old interface - the mouse pointer - with AI. 🖱️
These experimental demos show how people can intuitively direct Gemini on their screens using motion, speech, and natural shorthand to get things done 🧵
Made with seedance 2.0 + GPT Image 2
Prompt: Ultra-realistic sports broadcast still of a glamorous woman sitting in a packed football stadium crowd during a night match, wearing a dark brown sleeveless high-neck satin top and black square earrings, shoulder-length light brown/blonde hair styled in soft waves. She is casually drinking from a tall blue aluminum can while holding a half-eaten cheeseburger in the other hand. Around her are fans in bright yellow and blue football jerseys and scarves, creating strong team-color contrast. The scene feels candid and cinematic, captured mid-game from a TV broadcast camera angle with shallow depth of field. Include realistic stadium seating, crowded audience atmosphere, broadcast overlay graphics in the top-left corner showing a live football score and match timer, and a sports network watermark in the top-right. Natural arena lighting, detailed skin texture, sharp focus on the woman, slightly blurred background crowd, authentic live sports broadcast aesthetic, 16:9 composition.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself.
The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve.
We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving.
We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs.
This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).
Eric Schmidt says the 10x advantage is no longer execution. It is defining what counts as success.
A programmer writes a spec and an evaluation function, runs it at 7pm, and wakes up to what was invented overnight.
The advantage now belongs to whoever can specify the problem precisely.
The rest will be automated.