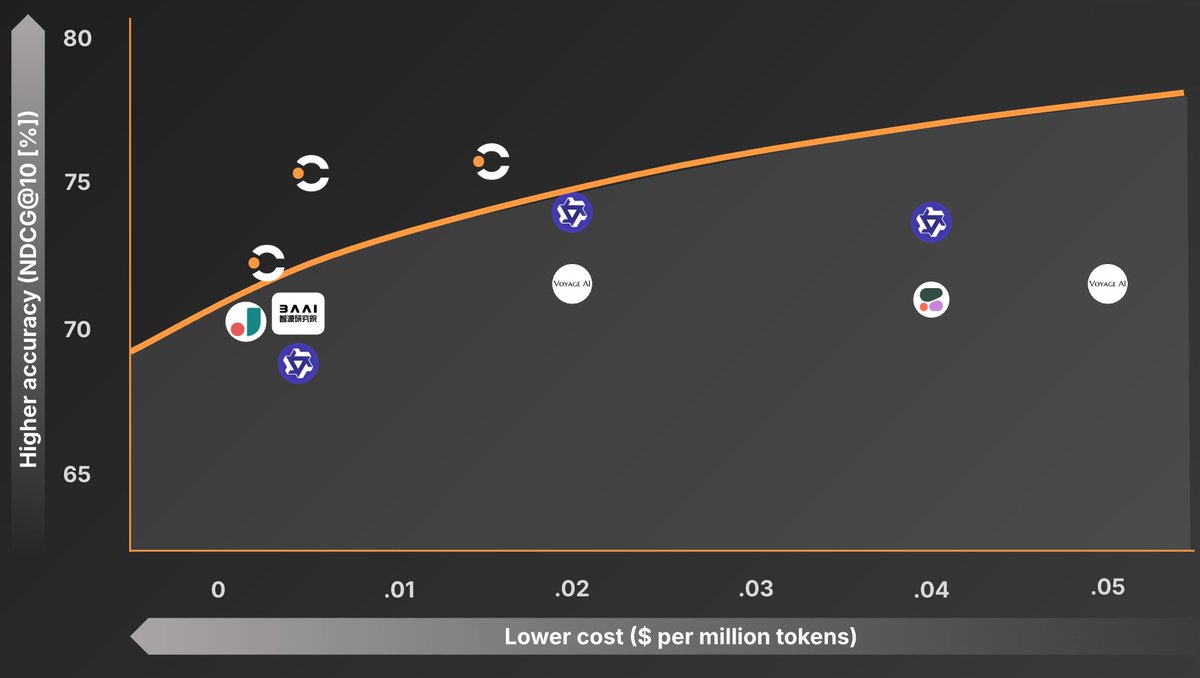
Excited to share that we trained rerankers at the cost/performance frontier and are open sourcing them!
Contextual AI Reranker v2
🚀 Best performing, most efficient reranker
🤗 Open weights (1B, 2B, 6B)
🫡 Instruction-following (including recency-awareness)
🌐 Multilingual
1/4
Stop building heuristic-based graphs. Start building adaptable, agentic tools.
We break down the full system design in this blog post:
https://t.co/ufRPQO8HH8
🧵 4/4
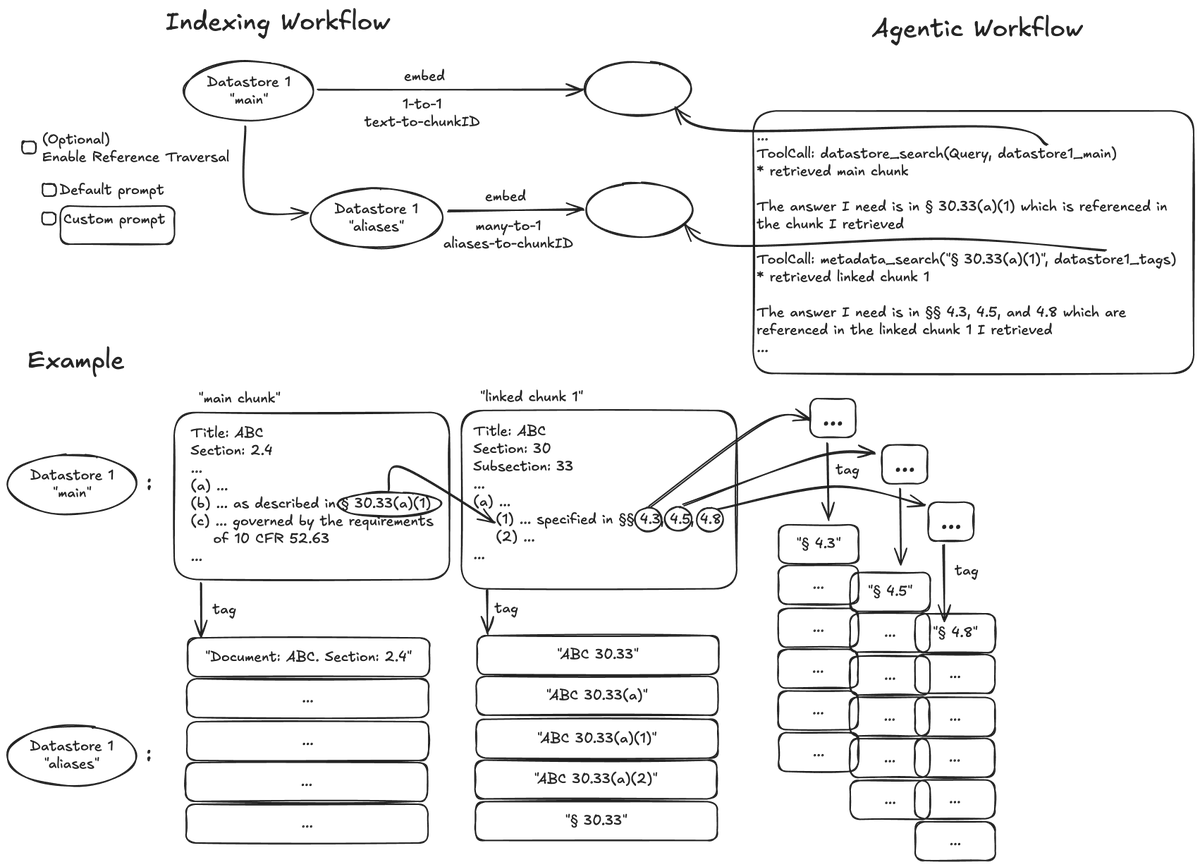
An agentic alternative to GraphRAG.
We built a Metadata Search Tool to solve reference traversal without the rigid complexity of static graphs.
The result? Agents resolve complex queries in fewer steps with higher accuracy.
🧵 1/4
Our solution: shift the traversal logic to the agent.
Extract “metadata”/“aliases” for each chunk at indexing time.
During retrieval, the agent dynamically chooses:
Search raw text content OR search metadata to hop to a reference?
🧵 3/4
This flexibility is the superpower. You control what to extract: section hierarchies, list of claims, questions the doc answers—whatever fits your use case. GraphRAG locks you into a static workflow. Metadata search adapts to yours.
Thanks Jackie Zhang and @sheshanshag for their help on this project! This tool will be available on our platform soon, but contact @ContextualAI for early access.
Your metadata IS your graph.
Giving our agents access to a metadata search tool boosted our evals by 11%, providing the flexibility of GraphRAG while avoiding all the complexity.
It unlocks new capabilities, including reference traversal. Example:
1. Agent finds a doc with references.
2. Agent decides which references to traverse and searches over metadata to fetch them.
Like GraphRAG, we extract structured info from docs at ingestion—each entry becoming a searchable node in the embedding space.
Unlike GraphRAG, we skip the heuristic-based graph building and navigation methods, which are often specialized to various domains and show diminishing returns in our ablations. This keeps things fast and adaptable. Adding new docs or changing your metadata schema is trivial.
.@ContextualAI 's new re-ranker ($0.05 per M tokens) is a bit better than voyage re-rank 2.5 (also $0.05 per M tokens) which is a pretty high bar IMO. ~2% better recall @ 10 in my eval. I'm also not exactly doing standard QA RAG either, so likely a bit out of domain for both.
@ethan_kim00 and that's why all other rerankers perform poorly on the recency benchmark. Ours was specifically trained to rank retrieved documents as:
more_relevant_more_recent_doc > more_relevant_less_recent_doc > less_relevant_more_recent_doc > less_relevant_less_recent_doc
Excited to share that we trained rerankers at the cost/performance frontier and are open sourcing them!
Contextual AI Reranker v2
🚀 Best performing, most efficient reranker
🤗 Open weights (1B, 2B, 6B)
🫡 Instruction-following (including recency-awareness)
🌐 Multilingual
1/4
Instruction following rerankers are so underrated. You can set arbitrary instructions like ‘sort by candidates that are a good fit for this role’ or ‘article mentions an early stage company’.
This is the kind of thing I was hypothesizing years ago, and it’s cool to see the space catch up to theory.
The next step will be small models that do binary classification based on a set of arbitrary criteria.
@lgandecki "compared to the 2nd-best rerankers which are up to ~10x more expensive!” I’m now realizing that the line break makes it seem like it’s not part of the sentence above it
We just released the latest version of our reranker: best performing, most efficient, open weights, instruction following, and multilingual. Try it out in your agentic RAG pipelines!
Performance on standard retrieval benchmarks like BEIR/ MMTEB hasn't correlated with performance on real world retrieval evaluation datasets for a while now.
The causes are twofold:
- Relevance is ill-defined and subjective.
- Popular retrieval benchmarks are gameable.
Here I describe how we tackled these challenges while building our second generation of rerankers.
1/N
You can access our rerankers now on
🤗 HuggingFace: https://t.co/kLdsRkkiCl
🌳 Google Model Garden: Available soon.
🟠 API endpoint: The first $50 (1 billion tokens) are free with a business email. Documentation: https://t.co/C0ewJV5apR
👩💻 Python SDK (code snippet attached)
3/4
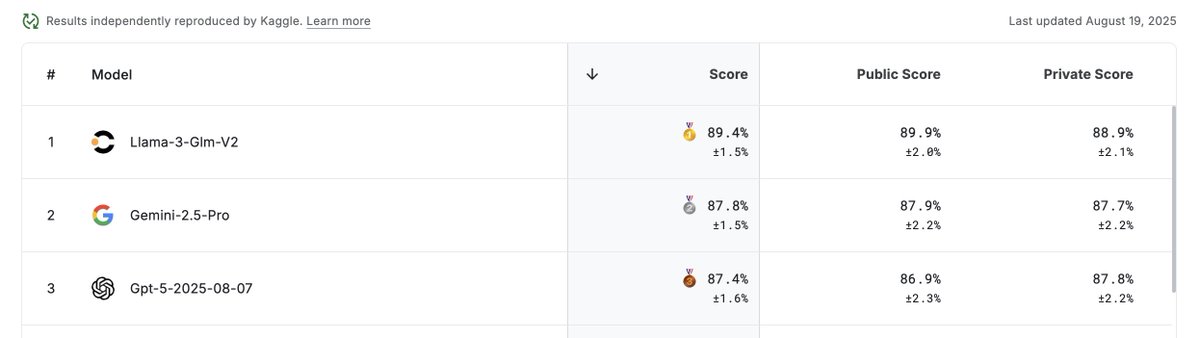
🏆 It's official - Contextual AI is now at the top of the FACTS leaderboard for groundedness, beating out strong competition from Gemini 2.5 Pro and GPT-5!
Congrats to our research team @w33lliam@rajan__vivek@nandita__naik@Thienhn97@sheshanshag@shikibmehri on this awesome achievement!
We had an interesting meta-learning at @aiDotEngineer World’s Fair from some of the organizers of the MCP track: there has been such an explosion in MCP Server creation, that one of the emerging challenges in this space is selecting the right one for your task.
📢 As promised ✨, we're open-sourcing LMUnit! Our SoTA generative model for fine-grained criteria evaluation of your LLM responses 🎯
✅ SoTA on Flask & BigGbench
✅ SoTA generative reward model on RewardBench2
🤗 Models available on @huggingface: https://t.co/rHe2Xl3wHH
💻 Github repo: https://t.co/Q7vVMG8EWH
📄 Paper: https://t.co/nonydlCszX
✍️ Blog: https://t.co/epyyUyp6hd
See more details in the quoted tweet👇