Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
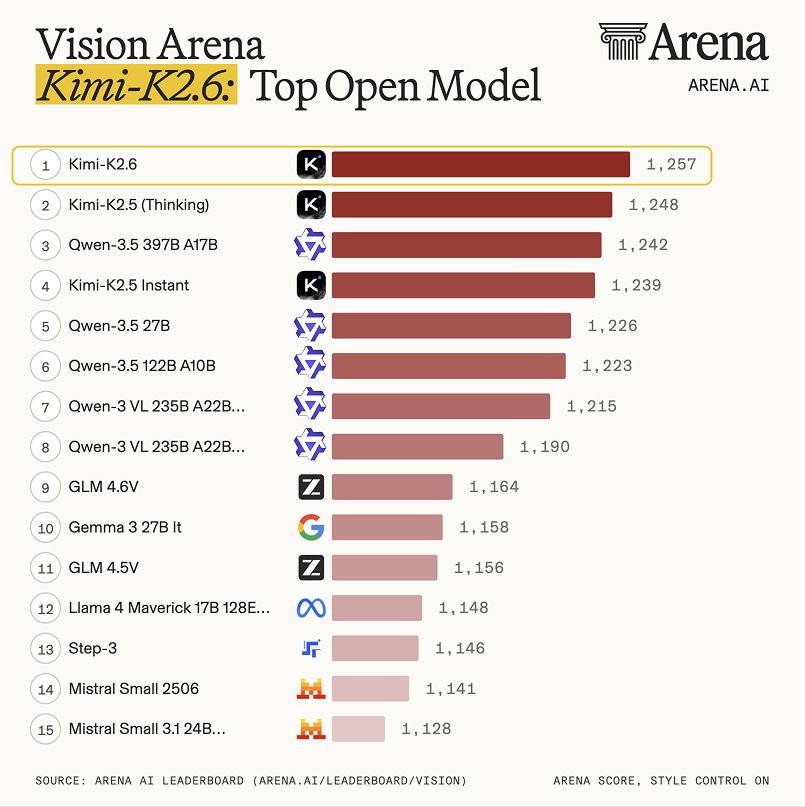
Kimi K2.6 is the new SOTA open model in Vision and Document Arena, with solid gains since Kimi K2.5:
- #1 open on Vision Arena (#15 overall), +14 over #2 Kimi K2.5 (Thinking)
- #1 open on Document Arena (#8 overall), +9 over K2.5 and on par with proprietary models like Muse Spark and Gemini 3.1 Pro.
Huge congrats again to the @Kimi_Moonshot team on the open source progress!
Meet Kimi K2.6 Agent Swarm 👋
Highlights:
🔹 Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from 100 / 1,500 in K2.5).
🔹 Outputs are real files, not chat - one run delivers 100+ files, 100,000-word literature reviews, or 20,000-row datasets.
🔹Heterogeneous skills - search, analysis, coding, long-form writing, and visual generation all running in parallel
🔗Try it at: https://t.co/2Tu8McUaUa
The Hermes Agent Creative Hackathon starts now
16 Days, $25k in Prizes
Presented by @Kimi_Moonshot & @NousResearch
For the tinkerers pushing Hermes Agent into creative domains: video, image, audio, 3D, long-form writing, creative software, interactive media and more.
Show us what your Hermes Agent can do.
Details Below ↓
Kimi K2.5 is now available on #WorkersAI. You can now build and run agents end-to-end on the Cloudflare Developer Platform. Read about how we tuned our inference stack to drive down costs for internal agent workflows.
https://t.co/kEQ6HHpoJS
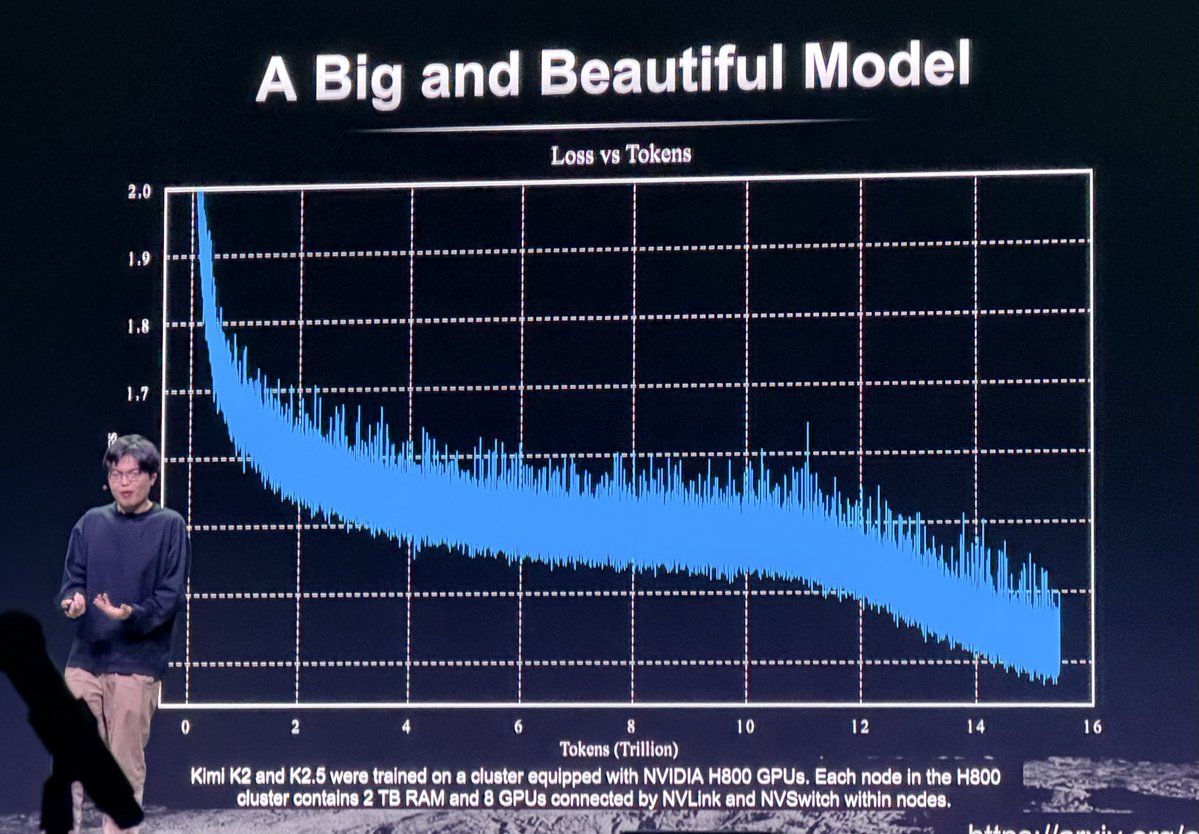
Per Moonshot AI CEO Zhilin Yang at GTC today, this is the "most beautiful image" he's ever seen. 📉
Made possible by NVIDIA H800 clusters. ✨
https://t.co/NAXkGGfP8Z
Good news: the Kimi Code 3X Quota Boost is here to stay.
No expiration. No catch. Just 3 times the power, permanently.
From quick fixes to full-scale production, there's a plan for every need.
Go build something amazing.
🥝 Meet Kimi K2.5, Open-Source Visual Agentic Intelligence.
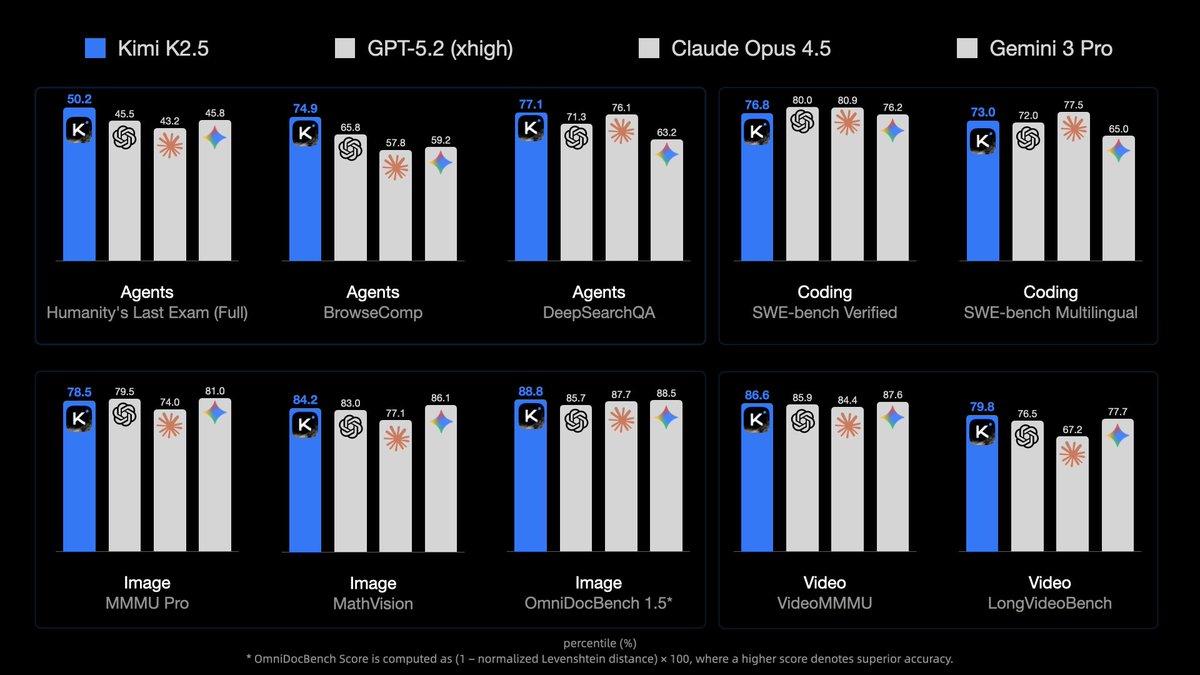
🔹 Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%)
🔹 Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%)
🔹 Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion.
🔹 Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup.
-
🥝 K2.5 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
🥝 K2.5 Agent Swarm in beta for high-tier users.
🥝 For production-grade coding, you can pair K2.5 with Kimi Code: https://t.co/A5WQozJF3s
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/6h2KkoA0xd
🔗 Weights & code: https://t.co/H38KegeDIY
Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask:
"What do you think about xyz"?
There is no "you". Next time try:
"What would be a good group of people to explore xyz? What would they say?"
The LLM can channel/simulate many perspectives but it hasn't "thought about" xyz for a while and over time and formed its own opinions in the way we're used to. If you force it via the use of "you", it will give you something by adopting a personality embedding vector implied by the statistics of its finetuning data and then simulate that. It's fine to do, but there is a lot less mystique to it than I find people naively attribute to "asking an AI".