Solo founder: Genhone (stress-test SaaS ideas) + Genwriter (cover letters that fit the job). Posting architecture, tradeoffs, numbers. AI @ Accenture by day.
I'm building two AI SaaS products in public — Genhone and Genwriter — and posting what shipping them teaches.
Architecture, model choices, costs, mistakes, and the occasional number worth posting.
Martin Fowler's blog shaped how I think about software design. Years later, the "don'ts" he wrote are the sharpest description I have of how coding agents write code.
Left alone, they reach for the same complexity Fowler warned against: a helper that wraps one call, a config flag nobody asked for, a base class for the one place it's used.
The agent wrote it in seconds, so it's tempting not to care. But the cost of writing code dropped and the cost of reading it didn't. I'm still responsible for the agent's mistakes, and complexity I can't follow is complexity I can't catch a bug in. The next agent run reads that code as its context too, so a clean codebase is easier for it to change correctly than a clever one. Cheap for the agent to add, expensive for both of us to maintain.
So the same principles that made me a better developer are a block in my AGENTS.md and CLAUDE.md:
- No speculative abstractions. Extract a helper or base class only when it's used in 2+ real places now. Three similar lines beat a premature abstraction.
- No one-line wrappers. Don't add a helper that only wraps one expression or one call. Inline it unless the helper removes real duplication or names repeated domain behavior.
- No future-proofing. No config flags or extension points for requirements that don't exist yet.
- No defensive over-engineering. No handling for edge cases that can't happen in the current code. Trust internal contracts.
- No unused flexibility. Nothing configurable until a second consumer exists today.
- Scope-bound changes. A bug fix changes only the broken behavior. A feature adds only what was asked. No drive-by cleanup.
What rule did you add to your agent instructions after seeing the same mistake twice?
@ArtificialAnlys can we get an update on the fallback rates for fable after the classifier updates? Like you published here before https://t.co/OgmXpYgo6z
Last week was mostly bug fixes and small improvements. The most interesting one: a subscription that should have been dead still worked. The bug was one word that meant two things.
I moved Genhone's billing from Stripe to Paddle. Paddle has no `expired` status. When a subscription ends, it's `canceled`.
My code already used `canceled` for something else: still active, paid through the period, just not renewing. My terminal state was `expired`.
So Paddle's `canceled` means it's over. Mine means it's still running. I must have missed it in the large amount of code changes during the migration. I caught it on one of my own test accounts before it reached a real user.
@kevinwhinnery@Common_Conor “have been updated” sounds like marketing wording for “expect more fallbacks” which makes the statement with “API behavior is the same” very misleading.
Previously Anthropic reported <5% fallbacks. Can you share the number after the “updates”?
@ushercakes@zacodil That’s not true. The flag and downgrade to Opus mechanism was also published three weeks ago. The big difference is that they heavily expanded their classifier. Totally different deal.
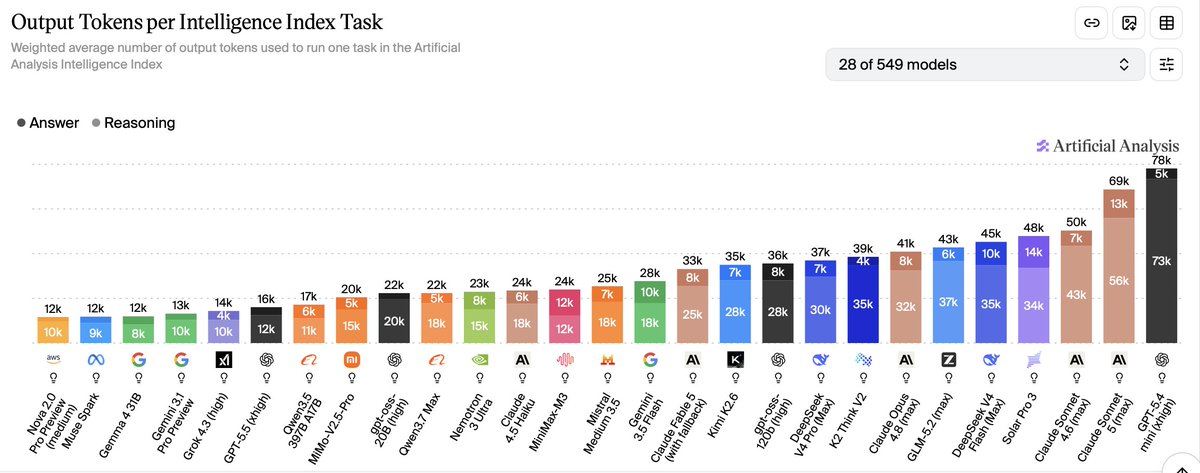
@elvissun answer tokens are close to 2x too. would expect much more useless prose in the answers.
feels like the trick to gaming benchmarks with small models now is just excessive reasoning. gemini flash 3.5, same story (compared to gemini 3.1 pro).
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5.
We'll begin restoring access tomorrow, and will share an update soon.
We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.
Sonnet 5 costs less per token than Opus 4.8, and more per task.
Artificial Analysis's Intelligence Index: Opus 4.8 max is $1.80 a task, Sonnet 5 max is $2.29. The cheaper model, 27% more to do the same work.
You don't pay per token, you pay per task. Sonnet reasons longer and answers less concisely, so it burns more tokens until the low rate stops mattering.
Gemini 3.5 Flash pulled the same trick.
Chain-of-thought used to be something you wrote in app code. Then the labs trained it in and gave you a setting.
GPT-5.6 Sol does it again, one layer up. `max` just thinks longer, one agent. `ultra` spawns subagents that run in parallel and merge their work. The orchestration we used to write around the model now runs inside the model call.
So if your edge is an agent pattern you built in app code, treat it as temporary. Whatever makes your product feel smart today is a candidate for next year's provider default. Build on it, don't mistake it for a moat.
I don't need analytics to count signups. My database already does that. What I can't see is how many people land on the page and leave before they sign up.
On a public EU page, before consent, every way I found to count those visitors was wrong in a different way.
Load nothing until consent: safe, but you miss everyone who leaves before clicking accept. Undercount.
PostHog with persistence: 'memory': no cookies, no local storage, nothing to consent to. But memory dies on reload, so every refresh and reopened tab is a new visitor. Overcount.
The middle setting is cookieless_mode: 'always'. Still no browser storage. PostHog hashes the IP, user agent, and a daily salt on its server, so a refresh stays one visitor for the day. Tomorrow they count as new. Better counts than memory mode.
The catch is legal. That hash is built from the IP, which is personal data. PostHog's argument: it's irreversible, so nothing personal is stored. I couldn't find a court ruling that settles it, and German courts have been strict on analytics. Low risk, not no risk.
So before consent you pick your error: undercount, overcount, or a server-side hash with a little legal risk.
This is my current understanding, not legal advice.
I stopped guessing where Genwriter's cover-letter generator loses people.
Before I rewrite copy, change the form, or blame the model, I instrumented the funnel. Not to the first letter, but all the way to the purchase:
public_page_viewed
public_generator_started
public_generator_submitted
generation_claim_completed
generation_completed <- first letter
credits_exhausted <- free credits run out
payment_received <- the signal that pays the bills
A free letter that never converts is a cost, not a win. The step I care about most is the gap between running out of free credits and paying for more.
What event do you wish you'd tracked before you started fixing conversion?
A free trial without a credit card is an invitation to abuse. For an AI product, every run costs money, so "free and anonymous" becomes a bill you pay.
So the card stays. But asking for it before anyone's seen the product is its own problem.
This week I added a public example output to Genhone. A real result the app produced, open to anyone, no signup. Nothing to run, so nothing to abuse, but enough to see what the product does.
It's just the output for now, not the live workflow. I'll try to add that next.
I'll also track who saw the demo before signing up, as a signal it may have helped them decide.
Have public demo pages notably increased signups for you?
Just added another footer to my pages. `Ask AI about ...`, this one opens Gemini, Claude, ChatGPT, Grok, and Perplexity with a prefilled product prompt.
Created a skill to quickly add that to new pages:
https://t.co/9Zm0mv2Lvw
It might do nothing for AI discoverability, and that's fine. It costs nothing to leave there.
And even if it never helps an AI find my products, the answers are good on their own. The responses I got back explain what I built clearly enough to help whoever clicks.
I keep seeing posts here and on Reddit about getting backlinks.
Most advice starts with DR. But I wonder how much DR matters from a page with no audience fit?
Maybe I'm underrating pure SEO value. But a weaker site with the right audience feels more interesting to me than a strong domain with no overlap.
What's your experience?
@elvissun Ah, makes sense. Will dig into your post about the Codex/Claude goal setup. Thanks!
Any reason for opus-4.7? 4.8 felt much better to me, so I didn't see a reason to keep using 4.7.