'Agent Harness Engineering: A Survey' just cited my Agent Skills for Context Engineering project in its Context & Memory Management section.
It’s a new paper on OpenReview (authors from CMU, Yale, Johns Hopkins, Amazon + others). They reviewed 170+ open-source projects and pulled real production lessons from OpenAI, Anthropic, and LangChain.
Agent performance in the real world = Model capability + Harness quality
For long-horizon, multi-step, production tasks, the harness has become the main bottleneck. Simple harness tweaks (better tool formats, sandbox changes, automated verification loops) deliver significant gains on benchmarks.
This is the second time my open-source work has been cited in academic research (first was Peking University’s State Key Lab paper on meta context engineering).
I’m genuinely proud of that, but more than anything it reminds me why I love open source. I’m not from academia. I learned this field by building, shipping, writing...
Open source lets your experiments enter the research papers. That is still one of the best parts of this field.
The paper is worth reading. We're moving from “build one agent” to “operate a fleet of long-running agents” and the paper repeatedly shows that the biggest improvements come from turning production traces into regression tests and automated harness fixes.
Paper & Repo: https://t.co/PAjqvOXedL
AutoResearch AI 这论文挺值得看的。
它讲的不是“AI 帮你总结论文”这种单点能力,而是一个更大的趋势:科研正在从 task-level AI,走向 workflow-level AI。
也就是说,AI 以后不只是帮你查文献、写代码、润色论文,而是可能参与完整科研流程:读文献、找问题、提假设、设计实验、调用工具跑实验、验证结果、写报告、再根据反馈修改。
论文里有个概念叫 Vibe Research,我觉得很形象:现在很多科研人其实已经在做了。人类给方向,AI 帮忙查、写、跑、改,最后人类负责判断和验证。
但作者也很清醒:真正的 AI 科学家还没到来。当前系统最大的问题不是会不会生成想法,而是证据能不能保存、实验能不能复现、弱方向能不能被及时拒绝、结论能不能追溯来源。
我觉得这篇文章最大的启发是:未来科研能力的竞争,可能不只是“谁会用 AI 写论文”,而是谁能搭出一套可靠的 AI research workflow。
AI for Science 的下一步,不是更会聊天的科研助手,而是更可验证、更可复现、更能闭环的科研工作流。
https://t.co/prnPUiBckS
#AIforScience #AutoResearch #Codex #claudecode
New research from Microsoft Research
I see a lot of AI engineers handwriting agent skill docs and hope they generalize.
Probably not optimal. This works show why.
It treats the skill doc as a trainable external state of a frozen agent instead.
It introduces SkillOpt, where an optimizer model makes validation-gated edits to the skill file. It adds, deletes, or replaces instructions, with a textual learning rate that controls how aggressively each round rewrites the doc. The agent itself never changes.
SkillOpt is best or tied on all 52 (model, benchmark, harness) cells.
On GPT-5.5 it adds 23.5 points in direct chat, 24.8 with Codex, and 19.1 with Claude Code over no skill. It beats human-written skills, TextGrad, GEPA, and EvoSkill, carries zero extra inference-time cost, and the learned skills transfer across models and harnesses.
Paper: https://t.co/mNgTmmT32U
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Anthropic pays $750,000+ a year for engineers who can build LLM architectures from scratch. Stanford taught the entire thing in 1 hour lecture & released it for free.
Bookmark & watch this today before someone takes it down.
Just launched GBrain v0.8.0
If you have it installed, you can just ask your Claw/Hermes to upgrade to the latest GBrain and we'll automatically ask if you want to install your Voice WebRTC endpoint and Twilio number
It's a true mega brain-trip to talk to your agent directly.
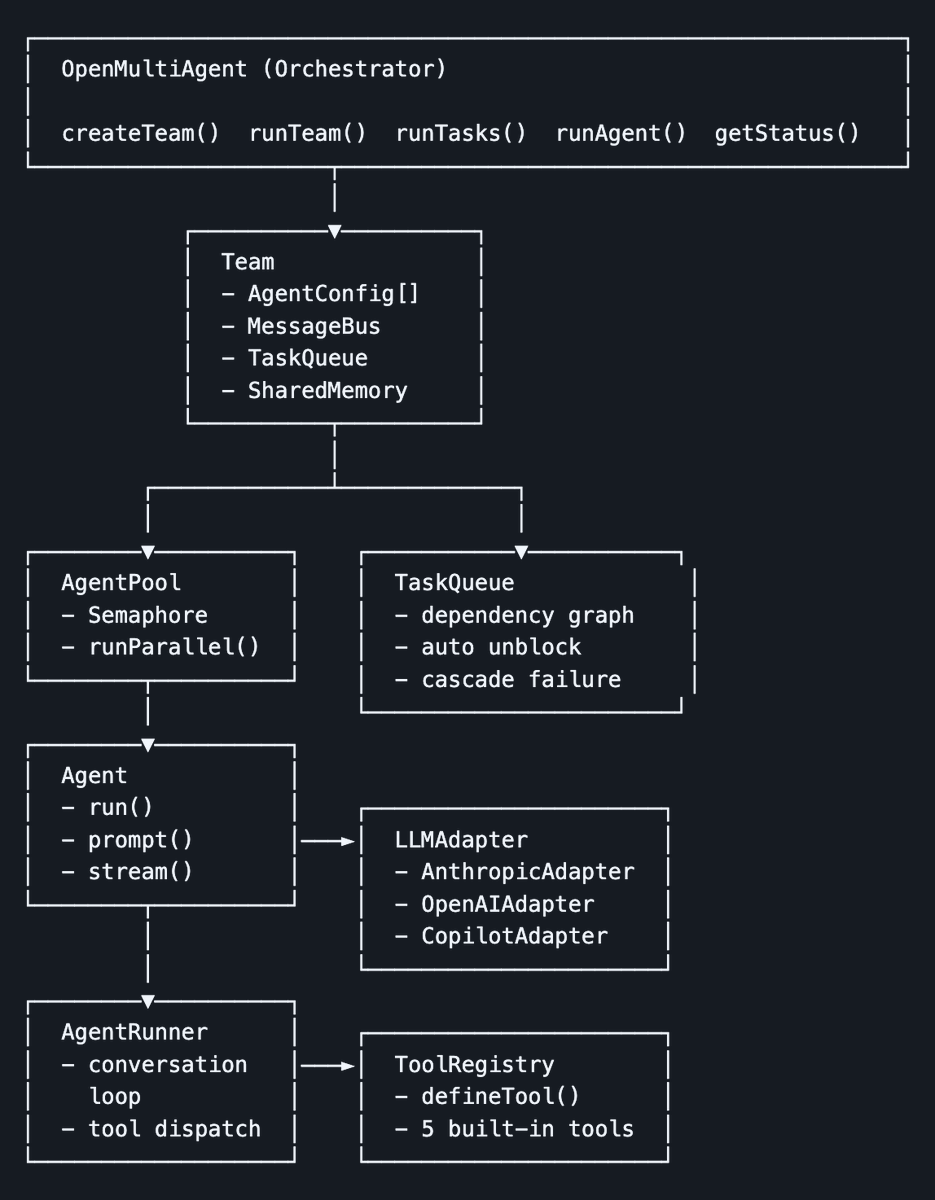
After the Claude Code source code leak, a former PM extracted its multi-agent orchestration system into an open source model agnostic framework.
He studied the architecture, focused on the multi-agent orchestration layer (the coordinator that breaks goals into tasks, team system, message bus, task scheduler with dependency resolution), and reimplemented these patterns from scratch as a standalone open source framework without infringing on Anthropic's code.
The result is what @JackChen_x calls an "open-multi-agent." Unlike claude-agent-sdk, which spawns a CLI process per agent, this runs entirely in-process and can be deployed anywhere (serverless, Docker, CI/CD)
Check it out: https://t.co/w3XjnZEk92
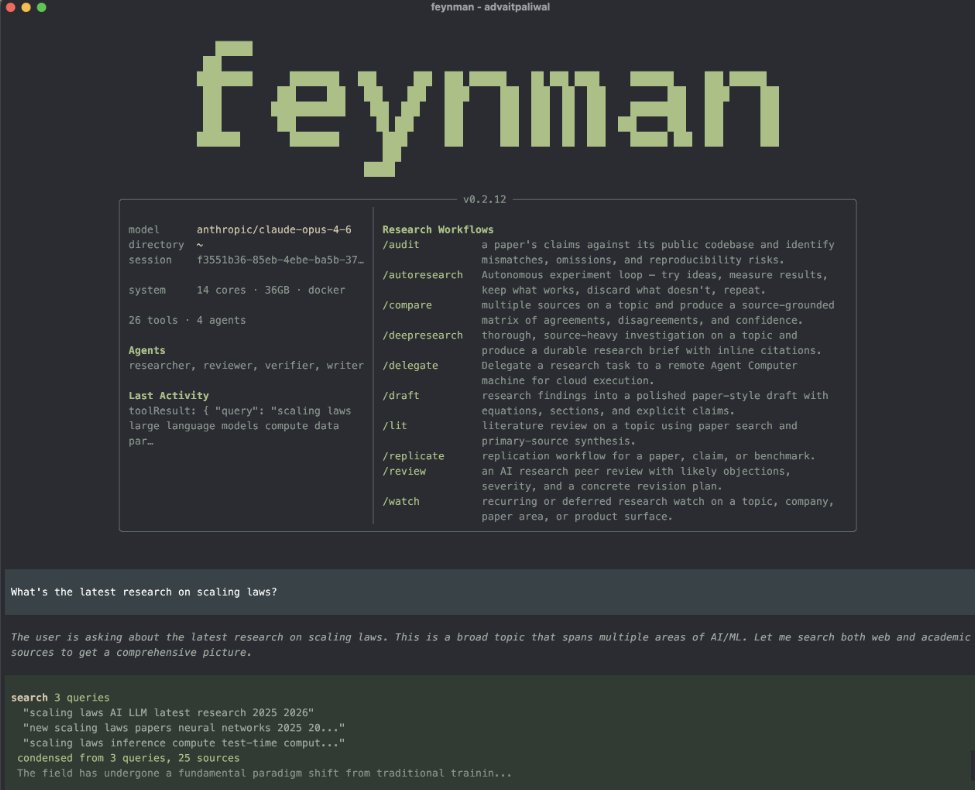
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
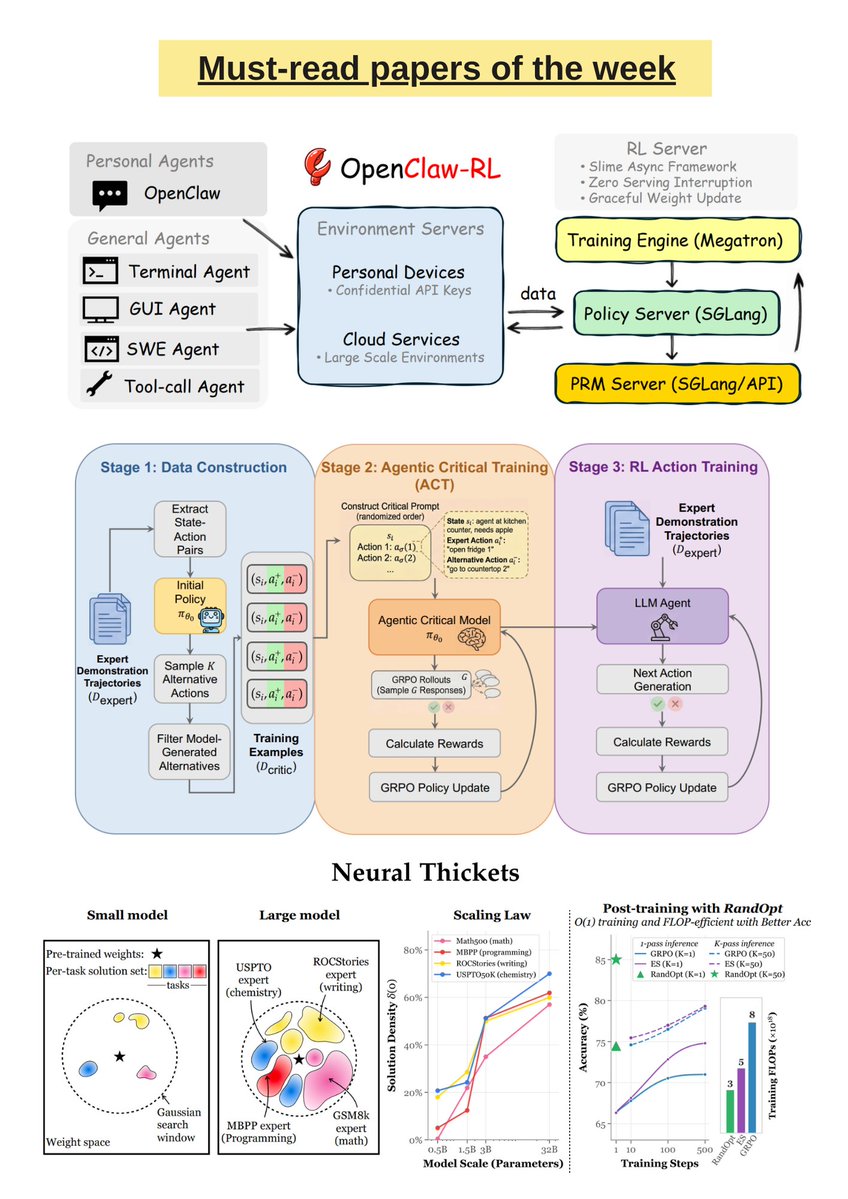
Must-read AI research of the week:
▪️ OpenClaw-RL
▪️ Meta-Reinforcement Learning with Self-Reflection for Agentic Search
▪️ Agentic Critical Training
▪️ Video-Based Reward Modeling for Computer-Use Agents
▪️ AutoResearch-RL
▪️ Neural Thickets
▪️ Training Language Models via Neural Cellular Automata
▪️ The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
▪️ Lost in Backpropagation: The LM Head is a Gradient Bottleneck
▪️ IndexCache
▪️ Attention Residuals
▪️ REMIX: Reinforcement Routing for Mixtures of LoRAs in LLM Finetuning
▪️ Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
▪️ Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
▪️ How Far Can Unsupervised RLVR Scale LLM Training?
▪️ Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
▪️ Reading, Not Thinking: Understanding and Bridging the Modality Gap When Text Becomes Pixels in Multimodal LLMs
▪️ Scale Space Diffusion
Find the full list and the main AI news and updates from NVIDIA GTC here: https://t.co/T985DbaCvR
A Survey of Context Engineering
160+ pages covering the most important research around context engineering for LLMs.
This is a must-read!
Here are my notes: