1/ I believe rules as code will be the most important societal and technological change of the 2020's. It will be impacting both the physical and digitals world. But what is it? and why is it important? Or why you should care? 👇 #rulesascode
Big news! We are organizing The Gradient with Prologin!
The Gradient is a recruitment-focused coding competition to spot the brightest minds in coding and AI-assisted development. 🧑💻
💡Why join?
✔️ Showcase your skills and critical thinking
🏆 Fast-tracked interviews, immersion days, cash prizes, subscriptions to Vibe and so much more!
🙋 Perfect for final-year students and recent graduates looking for internships and early-career roles!
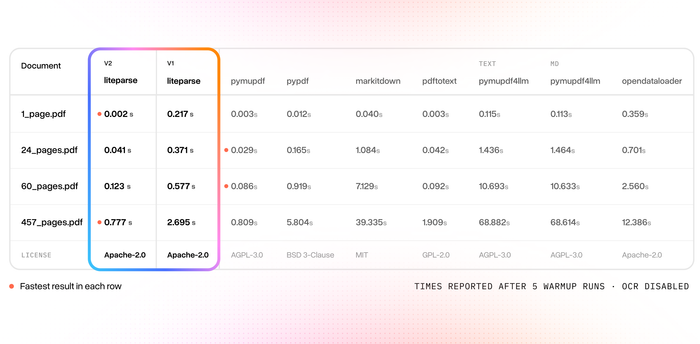
We've created the world's fastest PDF parser ⚡️
And it's more accurate than any other open-source, model-free PDF parser out there (pymupdf, pypdf, markitdown, pdftotext, opendataloader, pymupdf4llm)
Introducing LiteParse v2 - we rewrote the entire library into Rust and adapted it as native packages for Python and Node.
It supports 50+ different document types, can be triggered directly or installable directly within your favorite AI agent.
Blog: https://t.co/ckb0G73ESs
Repo: https://t.co/JNER0mVcB8
@jdrhyne@jerryjliu0 opendataloader bench is not evaluating liteparse task. liteparse does spatial text (aka project the text in a 2d grid respecting original layout, allowing agent to understand it), opendataloader evaluate lineralize text (text is reorder in reading order, destroying spatial info)
A full tour through RAG, document context, and AI agents - from 2023 to 2026 🌎🤖
@hexapode gave a comprehensive 90-min workshop at @aiDotEngineer Singapore last week that comprehensively traces through how topics like retrieval, agent loops, agentic workflows, and document understanding have evolved in the last 3 years.
We’re excited to share the 116-page slide deck online. If you’re seeing this for the first time, you’ll get a sense of how all AI patterns have evolved since the very beginning. Including the following topics:
💡 The 12 pain points of naive RAG
💡The importance of reranking and query-rewriting
💡How we’ve increased offloaded logic to the agentic loop as models improved (and coincidentally, the retrieval layer can get simpler)
💡Retrieval being the bottleneck as agents improved
💡Why document parsing is an extremely hard problem, even now in 2026
💡Exploring parsing outputs, from markdown to chunks to structured JSON metadata
💡Modern agent form factors around workflows and deep research
If you’ve followed us or the space since the beginning, some of this will feel a bit nostalgic and will provide context on why our core focus today is narrowly focused on SOTA document parsing for agents.
If you’re seeing this for the first time, hopefully there’s some useful historical context in here!
Slides: https://t.co/ey15yuJ2AW
@arlind0xBB@jerryjliu0@llama_index Note: This need to be done in the repo directory after cloning it, the skill that it run is here https://t.co/pXzagdbTrr
@arlind0xBB@jerryjliu0@llama_index We make it a one line to integrate any solution you want to evaluate and have access to with claude code: /integrate-pipeline <name> <API docs or SDK link>
Do share back the results!
We’re open sourcing the first document OCR benchmark for the agentic era, ParseBench.
Document parsing is the foundation of every AI agent that works with real-world files. ParseBench is a benchmark that measures parsing quality specifically for agent knowledge work:
✅ It optimizes for semantic correctness (instead of exact similarity)
✅ It has the most comprehensive distribution of real-world enterprise documents
It contains ~2,000 human-verified enterprise document pages with 167,000+ test rules across five dimensions that matter most: tables, charts, content faithfulness, semantic formatting, and visual grounding.
We benchmarked 14 known document parsers on ParseBench, from frontier/OSS VLMs to specialized parsers to LlamaParse. Here are some of our findings:
💡 Increasing compute budget yields diminishing returns - Gemini/gpt-5-mini/haiku gain 3-5 points from minimal to high thinking, at 4x the cost.
💡 Charts are the most polarizing dimension for evaluation. Most specialized parsers score below 6%, while some VLM-based parsers do a bit better.
💡 VLMs are great at visual understanding but terrible at layout extraction. GPT-5-mini/haiku score below 10% on our visual grounding task, all specialized parsers do much better.
💡 No method crushes all 5 dimensions at once, but LlamaParse achieves the highest overall score at 84.9%, and is the leader in 4 out of the 5 dimensions.
This is by far the deepest technical work that we’ve published as a company. I would encourage you to start with our blog and explore our links to Hugging Face to GitHub. All the details are in our full 35-page (!!) ArXiv whitepaper.
🌐: Blog: https://t.co/57OHkx0pQW
📄 Paper: https://t.co/Ho2oH2xEAM
💻 Code: https://t.co/6P7UxqOZYA
📊 Dataset: https://t.co/YguIXWm41j
🎥 YouTube: https://t.co/6Fh1Nsk9ei
I was frustrated with not being able to know why the code written by my colleague agents was in the codebase, so I build a tool to version agent trace along code in git.
git blame tells you who. git why tells you why.
https://t.co/T0gRSQqE5Q
Our latest LiteParse release gives your AI agent access to text bounding boxes within any PDF 📐
LiteParse is our fast/free open-source document parser that can extract text from any document. Besides the extracted text, we also expose bounding boxes for every text block.
This means that if you're building an AI agent over PDFs, it can now trace back to the precise line in the document and highlight it to the user, creating an audit trail for any decision made over this unstructured data.
We've created a new guide that shows you how to get bounding boxes (and use it to highlight text on the page similar to the example below).
Come check it out! https://t.co/YJFRFPyWxJ
LiteParse: https://t.co/JNER0mVcB8
Reports show document parsing accuracy for financial PDFs can improve 15% using LlamaParse + Gemini 3.1 Pro.
The tools extract structured data from unstructured brokerage statements and complex tables:
📈 Precise reasoning
📂 Clean PDF data
⚡️ Event-driven scaling
Code & details → https://t.co/bq7J6tZNmh
Improve document parsing accuracy by 15% for financial PDFs.
Use LlamaParse and Gemini 3.1 Pro to extract high-quality data from unstructured brokerage statements and complex tables.
📈 Precise reasoning
📂 Structured PDF data
⚡️ Event-driven scaling
Dive into the code on GitHub → https://t.co/yi7KxVzNPY