Here's a baseline quick bench between Anthropic and OpenAI models which I'm now content with.
This test runs Warden's stock securitiy-review skill across some known Sentry priors. These are security findings (excluding defense-in-depth) of various levels.
I can't explain the changes in Opus 4.7/4.8, but what I can tell you is: its simply not a good product. If a model update breaks usage of a model, I'll use. different model.
I'll likely be exploring switching our implementation to run GPT 5.5 (low) for PR review, as that's the right cost tradeoff we're looking for.
Generally speaking, the way you can read this is simple:
Higher % of known is desirable. Higher total findings is a secondary value add, but cost is the tradeoff.
More findings != exclusively more value. It likely means it found more lower sev (or in this case, defense-in-depth-style), that you may not even care to address.
In general consider this just an interesting unscientific experiment, one that anecdotally is important but not aimining to be a true benchmark.
Read more in the Warden docs: https://t.co/3ooTkswjUp
p.s. if you find something wrong in the data please let me know
at 50gp, bottles should be priced in!
i’m all for incentivizing recycling…
but effectively raising prices with hidden junk fees to cover workers comp for Crumb because you’re not adequately protecting him on bottle recovery is going to make me shop for health potions elsewhere
I really love Laravel Cloud, but am a bit sad about the pricing changes. The free plan is now $5 (with $5 credit, no preview environments), and compute is roughly doubling in price. So for most people it's the same cost or more.
So not really cheaper unless you use ultralow RAM
My view on RTX Spark and Surface Laptop Ultra and new Windows updates at build
Microsoft might get me back to Windows. Surface Laptop Ultra is nearly a MacBook Pro with similar specs and performance.
The Windows updates solve the annoying stuff with Windows… hmmm
In the last 6 months at @Ahrefs, we analyzed over 1 billion data points across 14 studies. Here's what we learned about AI search optimization:
1) "Best X" blog listicles are the single most prominent content format cited by AI chatbots. They make up 43.8% of all page types cited by ChatGPT specifically.
2) 67% of ChatGPT's top 1,000 citations come from sources marketers can't influence: Wikipedia (29.7%), homepages (23.8%), app stores (6.6%). Only 32.3% are influenceable content like educational pages, reviews, news, and blog posts.
3) 28.3% of ChatGPT's most-cited pages have zero Google organic visibility. These pages get cited repeatedly by ChatGPT despite not ranking in Google at all. A completely separate discovery layer.
4) ChatGPT only cites about 50% of the URLs it retrieves. It fetches dozens of pages per query but uses half as background context without attribution. This means that being retrieved and being cited are very different things.
5) Adding schema markup had zero meaningful impact on AI citations. AI Overviews actually dipped −4.6%, while AI Mode (+2.4%) and ChatGPT (+2.2%) showed changes indistinguishable from zero.
6) YouTube mentions have the highest correlation (0.737) with AI brand visibility out of all the factors we studied (including all the conventional SEO metrics like backlinks, page count, DR, etc). This held true for both Google-owned and OpenAI products.
7) AI Overviews reduce clicks to the #1 result by 58%. That’s up from 34.5% just 10 months earlier. The trend is accelerating.
8) 99.9% of AI Overviews appear on informational intent queries. Transactional, navigational, and local searches are almost entirely AIO-free. Shopping triggers AIOs just 3.2% of the time.
9) For a given search query, Google’s AI Mode and AI Overviews reach the same conclusions 86% of the time — but cite almost entirely different sources (only 13.7% citation overlap).
10) AI Overviews change every 2.15 days on average, with 70% of content differing between consecutive observations. But semantic similarity stays at 0.95. The words, sources, and entities constantly shuffle, but the actual meaning barely moves.
Congrats to @PaddlePaddle on the open release of PaddleOCR-VL-1.6! 🚀
An upgraded compact document parsing model hitting a 96.33% score on OmniDocBench v1.6, outperforming top-tier VLMs.🤖
https://t.co/xovFqwPeDW
📊 Benchmark Accuracy: Achieves 96.33% on OmniDocBench v1.6, while setting new performance records on OmniDocBench v1.5 and Real5-OmniDocBench for text, formula, and table recognition.
⚡ Upgraded Capabilities: Built with a region-aware data optimization framework. Brings significant precision leaps in tables, charts, seals, Chinese ancient documents, and rare characters.
🧠 Staged Optimization: Adopts a progressive post-training recipe based on curated data selection and reinforcement learning to enhance supervision signals.
🔄 Seamless Migration: Model architecture is fully compatible with PaddleOCR-VL-1.5 for a zero-cost plug-and-play replacement.
Keye VL 2.0-30B-A3B 🔥 New multimodal model from @KwaiKeye
✨ 30B/3B active - Apache 2.0
✨ 256K context via DeepSeek Sparse Attention (probably the first model to ship this in production?👀)
✨ Gets MORE accurate as you feed it more frames
✨ Matchs Qwen3 VL and Gemini 3 Flash on benchmarks
Mellum started with code completion.
Mellum2 is built for more – handling both natural language and code.
A 12B-parameter open-source LLM for routing, RAG, and sub-agents, optimized for ultra-low-latency inference.
Now on @huggingface.
Learn more: https://t.co/28sG8Ql52L
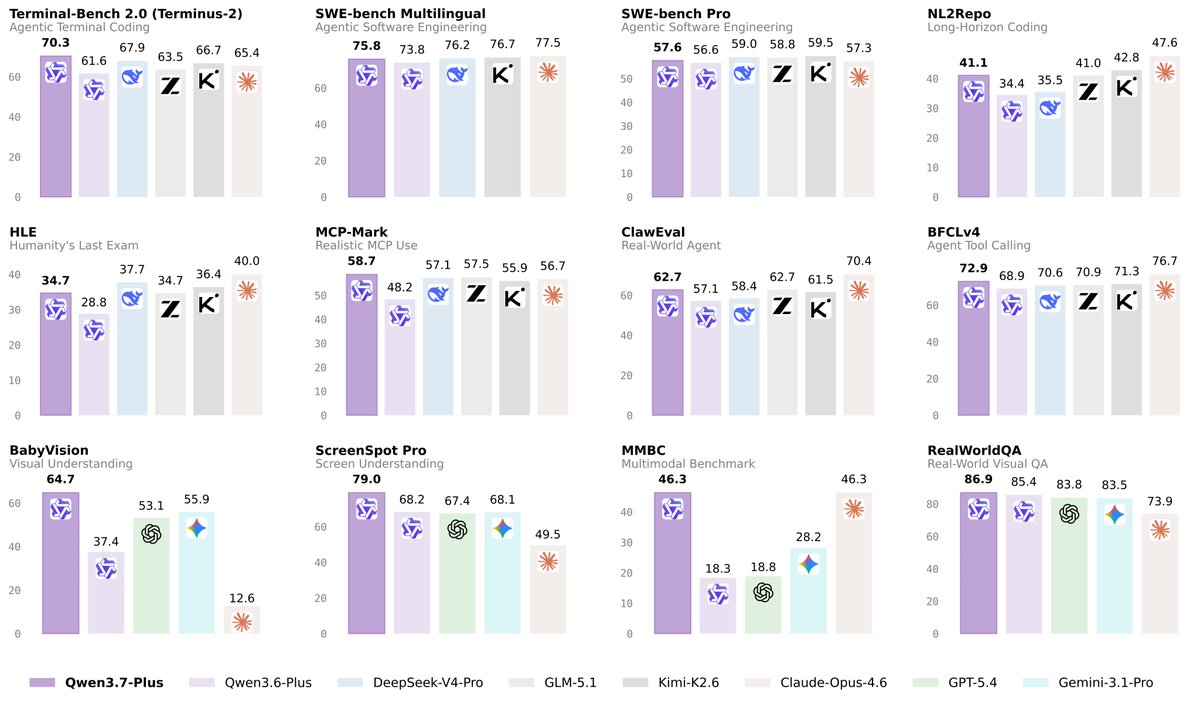
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
@assertchris@cmgmyr something to watch out for: usually tool definitions are put at the very beginning, like before the system prompt. so by turning tools on and oof, you end up breaking the key value cache. this is more expensive and slower as it needs to recompute the entire context.
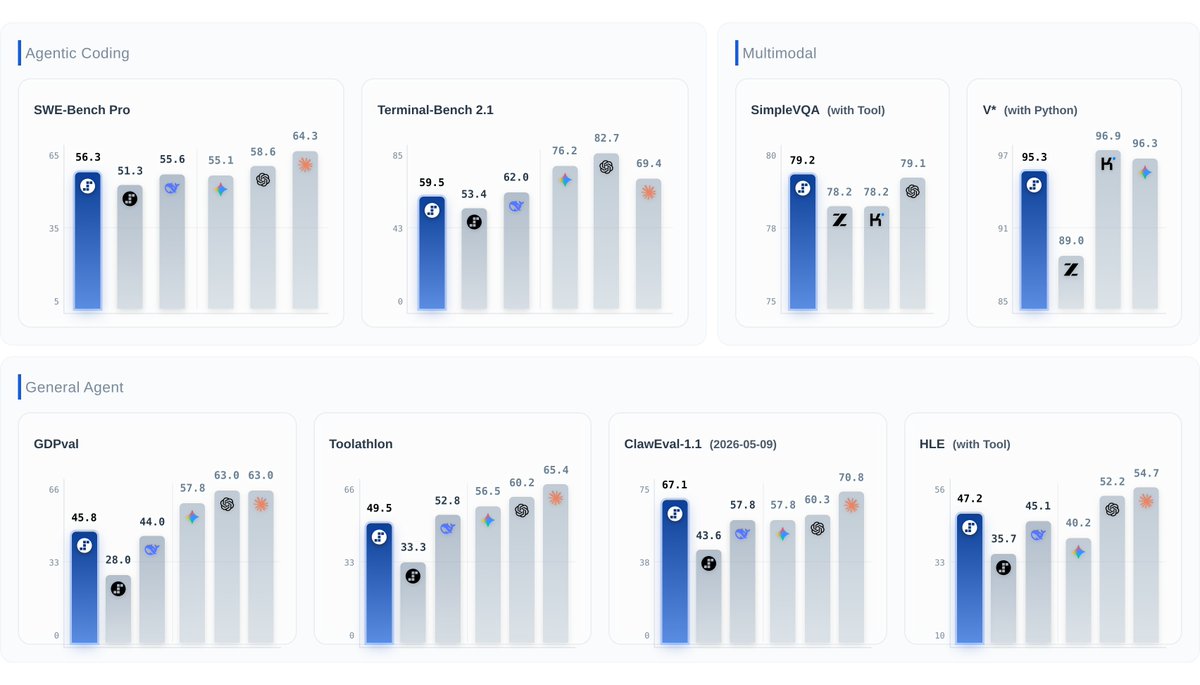
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
@zeeg same r/e codex
surely you’ll get some feeling on if it’s worth upgrading just based on warden.
you don’t have to use it, but you should tweet out an update eventually! even if it’s the teams vibes
i’m waiting for david’s review on 4.8.
after the sentry guidance on 4.7 being a lot more expensive, i moved back to 4.6 and never thought about it again.
i heard theres a new model release today?
is it going to help you get to PMF? attract new customers? solve a problem you couldn't solve before?
if not, consider why you even care
i'd be happier if anthropic released sonnet 4.8 instead of opus 4.8
sonnet 4.5 really had the best balance like the writing felt natural, the characters reacted in the right way
sonnet 4.6 and opus 4.7 is almost useless for creative work
opus 4.6 is okay, but it uses too many tokens
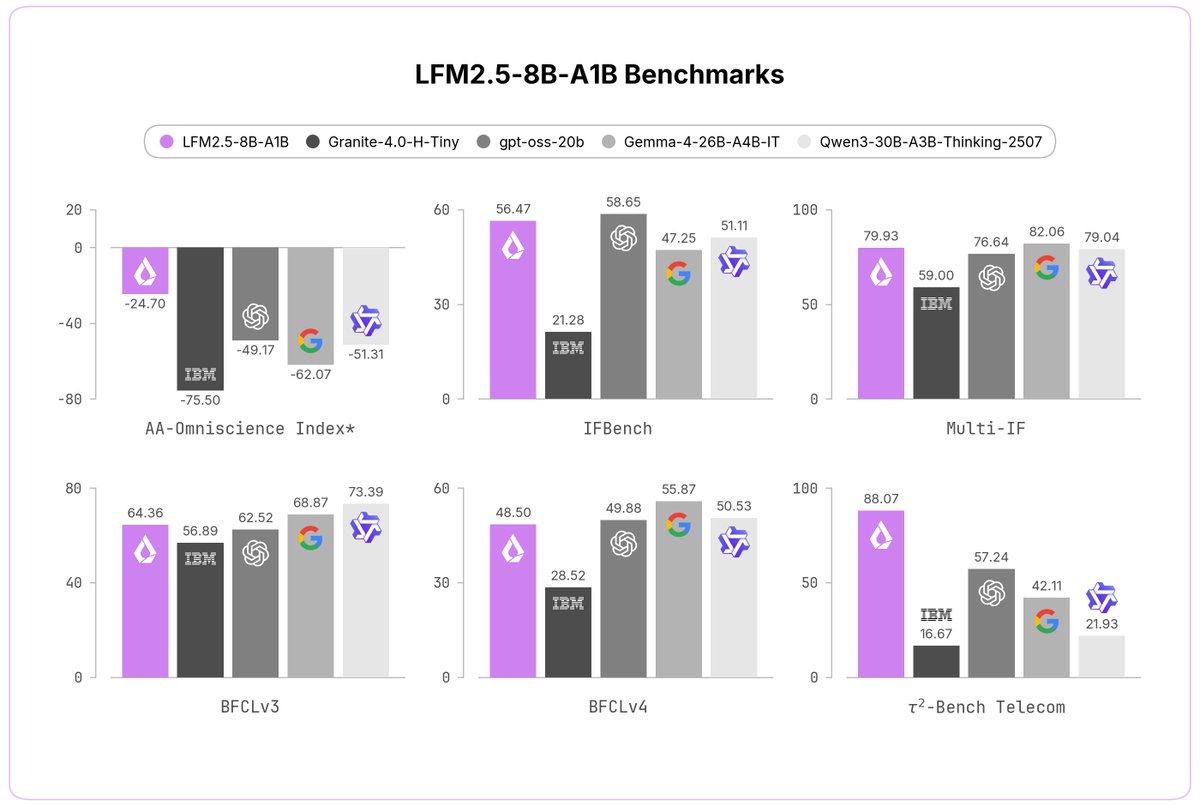
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵