The brain’s “default mode” and “action mode” networks are two sides of the same attractor.
Encoding a macro-scale Bayesian prior that biases processing toward internal or external drive.
Organization of neuropeptide systems in the human brain | https://t.co/v4JigZkMP4
Neuropeptides are functionally diverse signaling molecules in the brain and body.
@ericg_ceballos curates an atlas of neuropeptide receptors and relates it to brain function @NatureNeuro 🧩 🧠 ⤵️
New discovery! Different anesthetics all seem to push the brain into unconsciousness in the same way: Activity is destabilized and dominated by slow waves. This could block signals.
https://t.co/bUPlOMWM3K
#neuroscience@MIT_Picower@mitbrainandcog@mcgovernmit@ScienceMIT
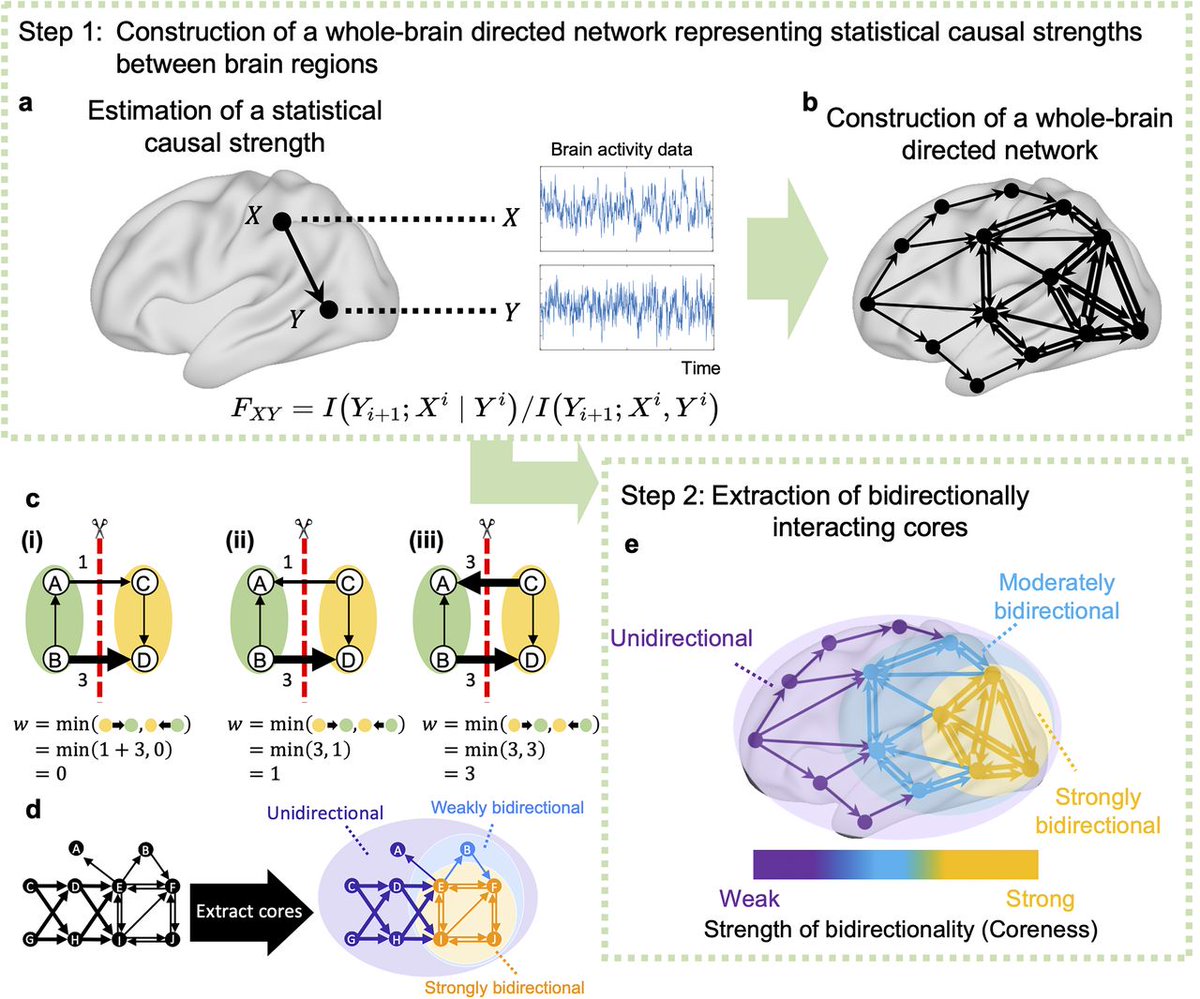
#JNeurosci: Findings from @_ttaguchi@JunKitazono@shuxnys and @oizumim offer novel insights into how network cores with strong bidirectional interactions contribute to the mechanisms underlying conscious perception and cognitive functions.
https://t.co/MUKmfWf6KJ
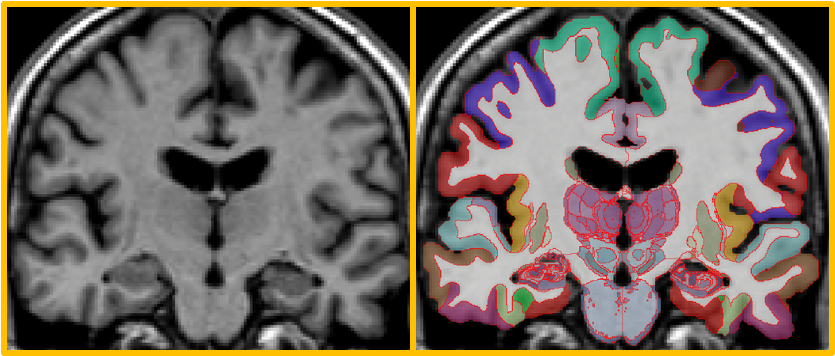
Major update to NextBrain segmentation! Version 1 was unusable without a huge GPU. New release:
1. Uses @rohitrango's FireANTs & simplified atlas to segment a brain in 20-30 mins without a GPU (or minutes on a GPU).
2. It is more robust.
Give it a try!
https://t.co/nKWyscc4AJ
The metabolic costs of cognition
Review by Sharna D. Jamadar (@SharnaJamadar), Anna Behler (@Anna_NeuroSci), Hamish Deery (@DeeryHamish), & Michael Breakspear (@DrBreaky)
Free access before March 4: https://t.co/OMVwrs5TpW
Understanding cognitive processes across spatial scales of the brain
Review by Hayoung Song (@HayoungSong5), JeongJun Park (@JeongjunPark2), & Monica D. Rosenberg (@monicarosenb)
Free access until Dec 24: https://t.co/4amjHeBTJc
I am a sucker for QA/QC. AIDAqc makes it easy.
We are trying it in our lab, and plan to use its reports in future pulications. great work @AswendtMarkus and Aref
The affective gradient hypothesis: an affect-centered account of motivated behavior
Opinion by Amitai Shenhav (@amitaishenhav)
Free access before Nov 13: https://t.co/ADW90jSxkl
Revisiting one of the most beautiful concepts in all of science.
"Action is one of the two terms in pre-relativity physics which survive unmodified in a description of the absolute world. The only other survival is entropy." -
Arthur Eddington, in 1920.
📘 🧵
Brain-wide dynamics linking sensation to action during decision-making https://t.co/Pq7YGa1Bfi - incredible study recording 15k neurons over 52 brain regions while mice accumulated evidence towards a choice
@WiringTheBrain Will add this work from their SWC colleague @SonjaBHofer as an example of lower brain simple 'machinery' that can decisively control amongst states whose exact form is upper brain defined
https://t.co/cLSf58cxcq
OpenAI Strawberry (o1) is out! We are finally seeing the paradigm of inference-time scaling popularized and deployed in production. As Sutton said in the Bitter Lesson, there're only 2 techniques that scale indefinitely with compute: learning & search. It's time to shift focus to the latter.
1. You don't need a huge model to perform reasoning. Lots of parameters are dedicated to memorizing facts, in order to perform well in benchmarks like trivia QA. It is possible to factor out reasoning from knowledge, i.e. a small "reasoning core" that knows how to call tools like browser and code verifier. Pre-training compute may be decreased.
2. A huge amount of compute is shifted to serving inference instead of pre/post-training. LLMs are text-based simulators. By rolling out many possible strategies and scenarios in the simulator, the model will eventually converge to good solutions. The process is a well-studied problem like AlphaGo's monte carlo tree search (MCTS).
3. OpenAI must have figured out the inference scaling law a long time ago, which academia is just recently discovering. Two papers came out on Arxiv a week apart last month:
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Brown et al. finds that DeepSeek-Coder increases from 15.9% with one sample to 56% with 250 samples on SWE-Bench, beating Sonnet-3.5.
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Snell et al. finds that PaLM 2-S beats a 14x larger model on MATH with test-time search.
4. Productionizing o1 is much harder than nailing the academic benchmarks. For reasoning problems in the wild, how to decide when to stop searching? What's the reward function? Success criterion? When to call tools like code interpreter in the loop? How to factor in the compute cost of those CPU processes? Their research post didn't share much.
5. Strawberry easily becomes a data flywheel. If the answer is correct, the entire search trace becomes a mini dataset of training examples, which contain both positive and negative rewards.
This in turn improves the reasoning core for future versions of GPT, similar to how AlphaGo’s value network — used to evaluate quality of each board position — improves as MCTS generates more and more refined training data.
📢 Excited to share our latest publication in @CommsBio on how memories are embodied through hippocampal-premotor cortex coupling! 🧠
Incredible work led by Nathalie Meyer (@nathalie_heidi) and Baptiste Gauthier!
👉 More details below:
https://t.co/HxuEIaBLWC #epfl
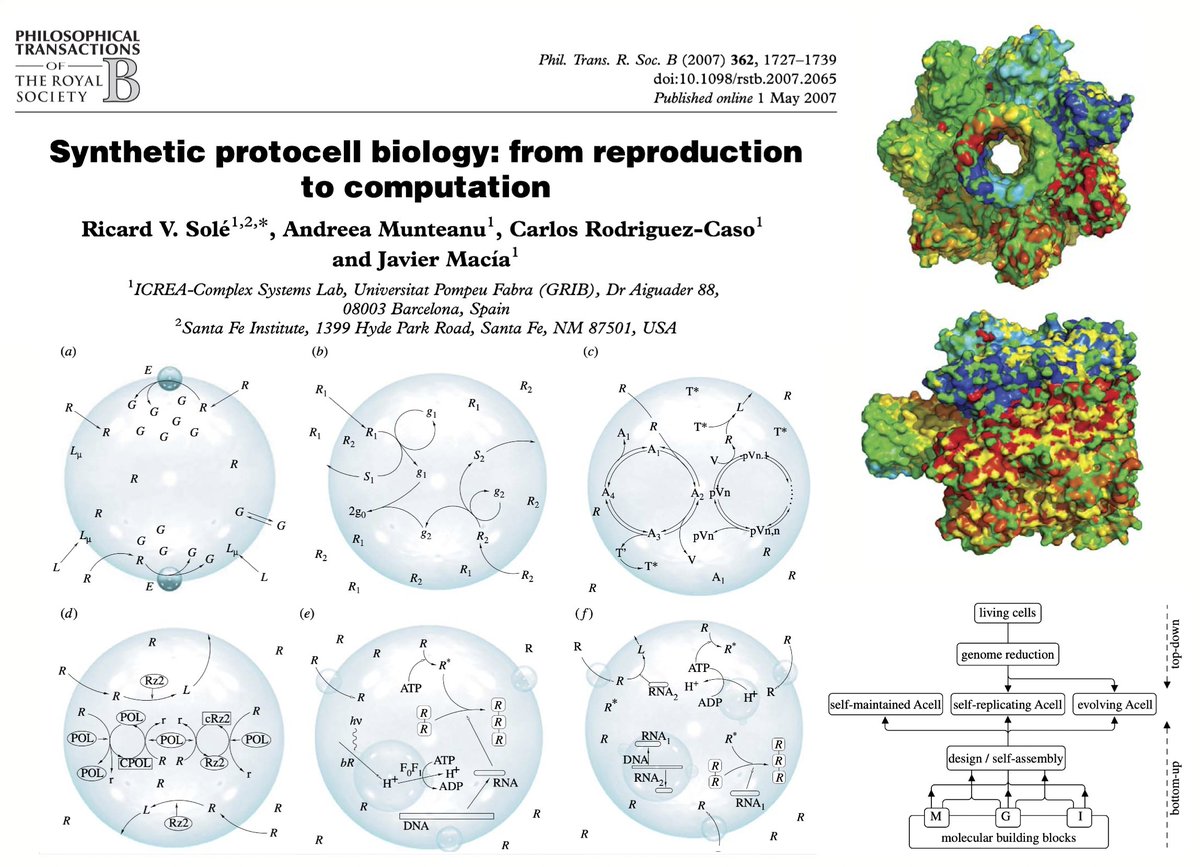
Is it possible to create an artificial cell from scratch? What kind of design principles and constraints will be involved? How can physics and maths guide research? Check our @RSocPublishing paper @AndreeaMuntean2 from chemistry to synthetic biology. https://t.co/67uUY8KXjQ