We've spent years treating evaluation as the side quest.
It's starting to look like the main quest.
https://t.co/DrTehpwWM7
https://t.co/lyOPiRxInA
https://t.co/JeE4EIRFTG
The bottleneck in AI is increasingly shifting from model capability to measurement capability.
The harder question is becoming: how do we know what they're actually capable of?
3 signals worth watching:
- ExploitBench brings granularity to exploit evals beyond pass/fail
- Anthropic's Glasswing shows AI finds vulnerabilities faster than humans can patch them
- Their exploit eval work pushes agentic evals into realistic envs over trivial benchmarks
We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000+ tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
Most people think in terms of what’s there. Signals. Data. Presence. The Maxwell Algorithm flips that.
It’s really about fields. Not objects. Not rows in a database. Fields. Where energy moves, where pressure builds, where something is about to change. You’re not modeling things, you’re modeling influence.
That’s exactly how I use it.
With ruvector and Cognitum, I don’t try to track everything. That’s a losing game. I treat the system like a field and look for gradients. Where is coherence breaking. Where is tension forming. Where is flow accelerating.
Take RuView. I’m not “seeing a person” through walls. I’m tracking disturbances in the RF field. Breathing is a periodic ripple. Heartbeat is a micro fluctuation. Movement is a phase shift. I’m reading the field, not the object.
Same with dynamic mincut. The cut is not just a boundary. It’s where the field is weakest. Where separation naturally occurs. That’s your signal. That’s where something important is happening.
Agents follow that. They don’t scan everything. They move toward pressure. Toward change.
Practically, this means less compute, faster detection, and better decisions. You’re not reacting after the fact. You’re moving with the system as it evolves.
Once you start thinking in fields instead of objects, everything gets simpler.
You stop searching.
You start sensing.
How do you maximize LLM inference performance while staying within your budget?
My latest post covers these latest techniques:
1. Semantic routing across model tiers
2. Prefill & decode disaggregation
3. Quantization
4. Context routing
5. Speculative decoding
👉 https://t.co/2deUL279cG
You are probably hearing every influential software developer in your social media feed rave about the new generation of coding assistants like Claude Code, Augment, Cursor, and Google Antigravity. What's happening?
1/n
Sounds incredible until you read the fine print. The compiler generates less efficient code than GCC with all optimizations disabled. It doesn’t have its own assembler or linker. It can’t produce a 16-bit x86 code generator. And Carlini himself says it has “nearly reached the limits of Opus’s abilities.” New features and bugfixes kept breaking existing functionality.
So what did $20,000 and two weeks actually buy? A compiler that passes 99% of GCC’s torture tests but can’t match the output quality of a tool that’s had 37 years of human engineering. That’s the constraint nobody’s pricing in.
The real story is in the cost curve, not the capability demo. $20,000 for 100,000 lines means $0.20 per line of generated code. A senior compiler engineer costs roughly $150/hour. At maybe 50 polished lines per hour for something this complex, that’s $3/line. AI just did it at 15x cheaper, and it will only get cheaper from here.
But the code isn’t equivalent. The AI version needs a human to finish the assembler, fix the linker, optimize the output, and prevent regressions. Those are the hardest 20% of the problem, and they represent 80% of the engineering value. Anthropic built the demo. Shipping the product still requires humans.
This tells you exactly where we are in the autonomous software timeline. AI can now produce impressive first drafts of complex systems at trivial cost. Turning those drafts into production software still requires the judgment that costs $300K+ per year in compiler engineer salary. The gap between “compiles the Linux kernel” and “replaces GCC” is measured in decades of accumulated engineering wisdom that no model has internalized yet.
The companies that understand this will use agent teams to generate the 80% and hire engineers to finish the 20%. The companies that don’t will ship $20,000 compilers that produce slower code than a free tool from 1987.
🧵 Thread: Introducing MAMF Explorer 🧵
A practical way to understand real matmul performance on GPUs, not just theoretical peaks.
https://t.co/j4R3LHRAFt
We spun up a new GitHub repo for all things MCP at @Google.
Get info on our remote managed MCP servers, open source MCP servers, examples, and learning resources.
https://t.co/q6erJX2Xcc
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
After rewatching Home Alone, I couldn’t stop wondering:
how plausible is the oversleep that leaves Kevin behind?
So I wrote a tiny paper and ran the numbers.
Merry Christmas! 🎄
"Not your weights, not your brain"
I see this as pluggable exocortexes.
You will be using closed-source exocortexes for work, where "giving up control in exchange for a better brain" gives you an edge.
For your personal, private life you will plug in something that actually cares about you, does not make you vulnerable to private company control for profit.
Finally, Python 3.14 lets you disable GIL!
It's a big deal because earlier, even if you wrote multi-threaded code, Python could only run one thread at a time, giving no performance benefit.
But now, Python can run your multi-threaded code in parallel.
And uv fully supports it!
Understanding GPU Architecture from Cornell
https://t.co/B1tDsYOCVF
During a low-level discussion at a casual meetup, many folks were interested in understanding GPUs more closely.
While CPUs optimize for complex control flow (see those big cores + caches), the GPUs maximize throughput with thousands of simple cores sharing memory. The GPU architecture roadmap is a good starting point for diving deeper.
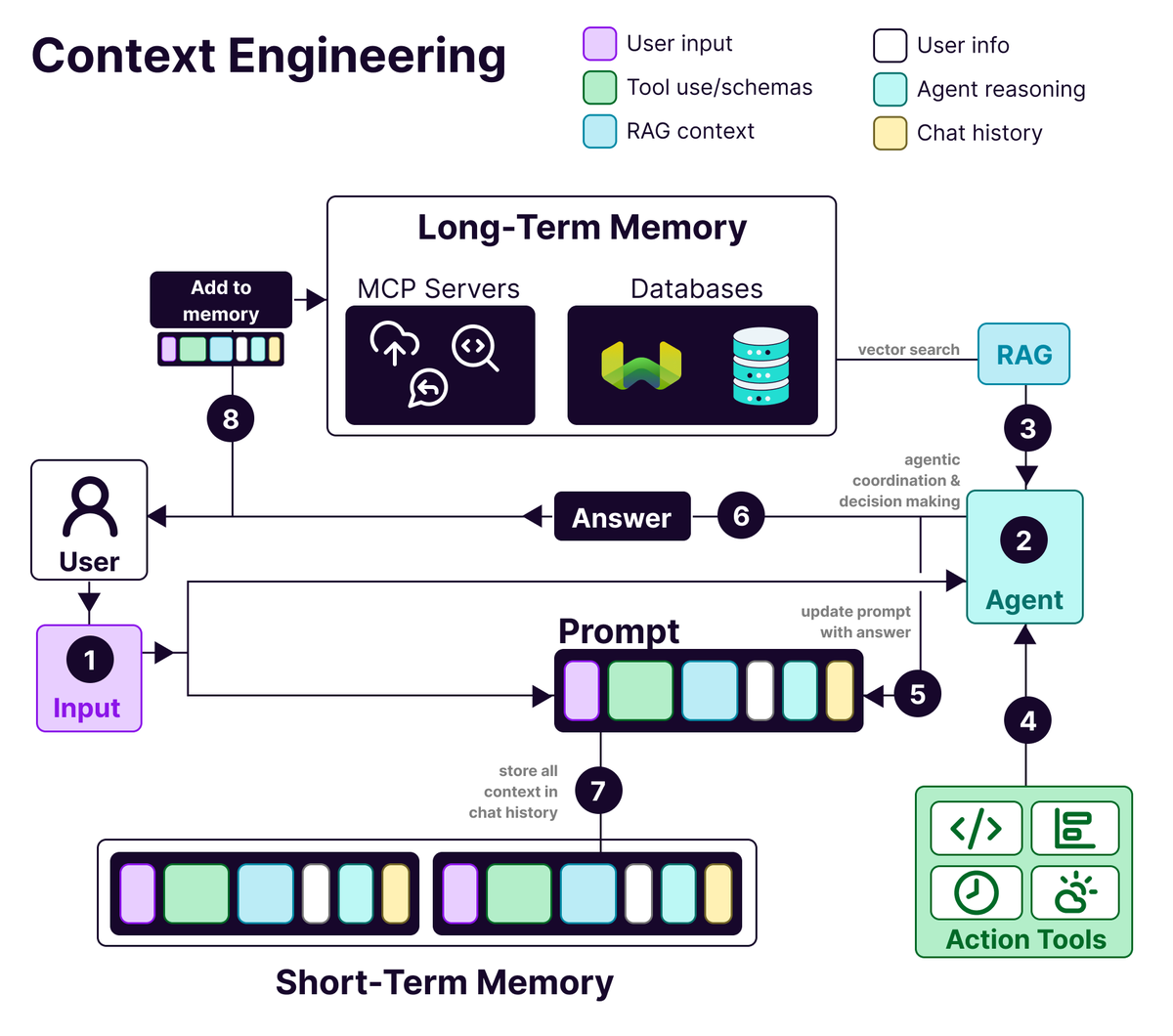
Prompt engineering is dead. Long live 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴
(Well, not quite dead - but it's definitely evolving into something way more powerful)
Meet 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 - the art of building dynamic systems that give LLMs exactly what they need to succeed.
As we move from simple chatbots to complex AI agents, we're realizing that clever prompts aren't enough. What matters is orchestrating an entire ecosystem of information that flows into your LLM.
So what exactly does that mean?
It's about building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task.
The anatomy of a context-engineered system includes:
📊 𝗨𝘀𝗲𝗿 𝗜𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻: Preferences, history, and personalization data
🔧 𝗧𝗼𝗼𝗹 𝗨𝘀𝗲: APIs, calculators, search engines - whatever the LLM needs to get the job done
🔍 𝗥𝗔𝗚 𝗖𝗼𝗻𝘁𝗲𝘅𝘁: Retrieved information from vector databases like Weaviate
💬 𝗨𝘀𝗲𝗿 𝗜𝗻𝗽𝘂𝘁: The actual query or task at hand
🧠 𝗔𝗴𝗲𝗻𝘁 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴: The LLM's thought process and decision-making chain
📜 𝗖𝗵𝗮𝘁 𝗛𝗶𝘀𝘁𝗼𝗿𝘆: Previous interactions that provide continuity
But what about the memory architecture?
• 𝗦𝗵𝗼𝗿𝘁-𝘁𝗲𝗿𝗺 𝗺𝗲𝗺𝗼𝗿𝘆: Lives in the context window, handling current conversations
• 𝗟𝗼𝗻𝗴-𝘁𝗲𝗿𝗺 𝗺𝗲𝗺𝗼𝗿𝘆: Stored in vector databases (like Weaviate), persisting user preferences and past interactions across sessions
Why does this matter? Because when agentic systems fail, it's rarely because the model isn't smart enough. It's because we haven't given it the right context.
The format matters too. A well-structured error message beats a massive JSON blob every time. Just like humans, LLMs need clear, digestible communication.
It turns out,
> GRPO is performing the arithmetic mean --> token-level scaling
> GSPO is performing the geometric mean --> sequence-level scaling
Check the blog if you do not have time to read.
https://t.co/tVHJnSYFse
Burnout happens when there is no progress. Burnout also happens when you have no visibility into how dots will connect in the future. Burnout is about not being able to close the loop after putting a ton of effort and not seeing enough results.