Almost all animals sleep. Why don’t LMs?
Introducing our new work on language model sleep.
tl;dr : A periodic, recurrent “sleep” phase allows LMs to digest their context and transfer it into their weights, improving recall and reasoning on challenging tasks.
@suchenzang If we ever want to make mythos-level models widely available, we need to figure out how to prevent them from doing bad things like hacking software.
but if accessibility doesn't matter I guess we can just keep gating access like ant has been doing
@_emliu When I was a PhD I also found usually the ROI was good! But sometimes the ROI is not so great.. I once tried applying for a cerebras grant ~2021 and stopped when I realized adapting to their system would be too hard. Though maybe their system is more user friendly now!
Sharing a super simple, user-owned memory module we've been playing around: nanomem
The basic idea is to treat memory as a pure intelligence problem: ingestion, structuring, and (selective) retrieval are all just LLM calls & agent loops on a on-device markdown file tree. Each file lists a set of facts w/ metadata (timestamp, confidence, source, etc.); no embeddings/RAG/training of any kind.
For example:
- `nanomem add <fact>` starts an agent loop to walk the tree, read relevant files, and edit.
- `nanomem retrieve <query>` walks the tree and returns a single summary string (possibly assembled from many subtrees) related to the query.
What’s nice about this approach is that the memory system is, by construction:
1. partitionable (human/agents can easily separate `hobbies/snowboard.md` from `tax/residency.md` for data minimization + relevance)
2. portable and user-owned (it’s just text files)
3. interpretable (you know exactly what’s written and you can manually edit)
4. forward-compatible (future models can read memory files just the same, and memory quality/speed improves as models get better)
5. modularized (you can optimize ingestion/retrieval/compaction prompts separately)
Privacy & utility. I'm most excited about the ability to partition + selectively disclose memory at inference-time. Selective disclosure helps with both privacy (principle of least privilege & “need-to-know”) and utility (as too much context for a query can harm answer quality).
Composability. An inference-time memory module means: (1) you can run such a module with confidential inference (LLMs on TEEs) for provable privacy, and (2) you can selectively disclose context over unlinkable inference of remote models (demo below).
We built nanomem as part of the Open Anonymity project (https://t.co/fO14l5hRkp), but it’s meant to be a standalone module for humans and agents (e.g., you can write a SKILL for using the CLI tool). Still polishing the rough edges!
- GitHub (MIT): https://t.co/YYDCk5sIzc
- Blog: https://t.co/pexZTFdWzz
- Beta implementation in chat client soon: https://t.co/rsMjL3wzKQ
Work done with amazing project co-leads @amelia_kuang@cocozxu@erikchi !!
I recently started a new role as a Research Scientist at Google DeepMind!
Before looking ahead, I want to say a huge thank you to my former teammates at Meta. I'm incredibly grateful for the time we spent building together, and I know they will continue to build amazing things.
I’ve always admired DeepMind’s focus on building AI responsibly to benefit humanity. I'm really excited to collaborate with such a brilliant team and tackle some of the hardest foundational problems in our field.
Can't wait to get to work!
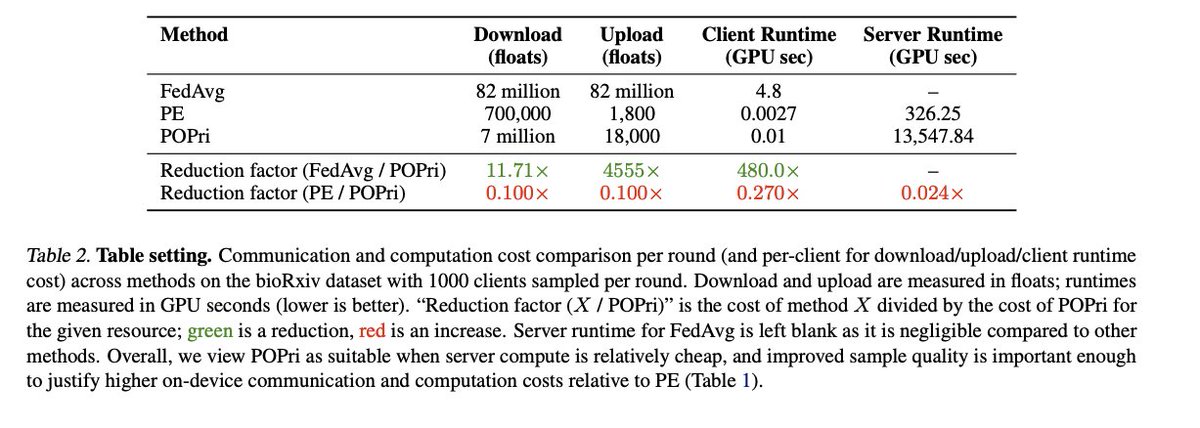
Gave a talk at @OpenAI on our work 🌸 POPri “Policy Optimization for Private Data”. POPri is a huge improvement in synthetic data generation under security+privacy constraints! Learn more:
POPri also sees strong efficiency gains vs prior state-of-the-art like Federated Learning, with much lighter computational burden on the user devices. In exchange, more server compute is used.